 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Does It Exist: Spatio-Temporal Video Grounding for Multi-Form Sentences
Feb 25, 2020
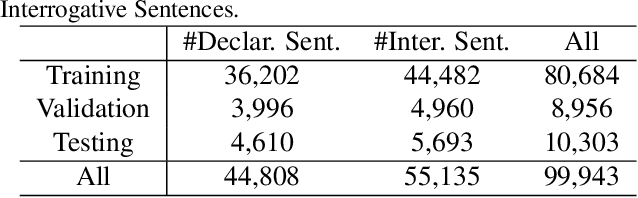
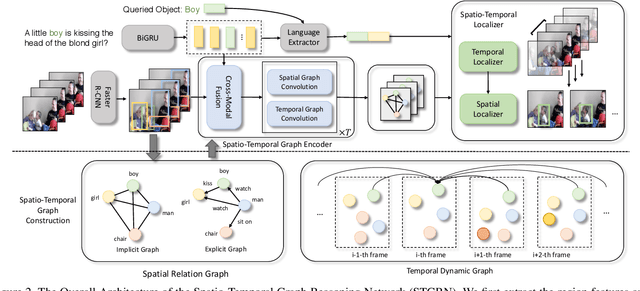
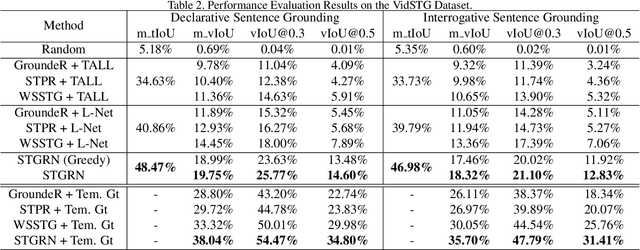
In this paper, we consider a novel task, Spatio-Temporal Video Grounding for Multi-Form Sentences (STVG). Given an untrimmed video and a declarative/interrogative sentence depicting an object, STVG aims to localize the spatiotemporal tube of the queried object. STVG has two challenging settings: (1) We need to localize spatio-temporal object tubes from untrimmed videos, where the object may only exist in a very small segment of the video; (2) We deal with multi-form sentences, including the declarative sentences with explicit objects and interrogative sentences with unknown objects. Existing methods cannot tackle the STVG task due to the ineffective tube pre-generation and the lack of object relationship modeling. Thus, we then propose a novel Spatio-Temporal Graph Reasoning Network (STGRN) for this task. First, we build a spatio-temporal region graph to capture the region relationships with temporal object dynamics, which involves the implicit and explicit spatial subgraphs in each frame and the temporal dynamic subgraph across frames. We then incorporate textual clues into the graph and develop the multi-step cross-modal graph reasoning. Next, we introduce a spatio-temporal localizer with a dynamic selection method to directly retrieve the spatiotemporal tubes without tube pre-generation. Moreover, we contribute a large-scale video grounding dataset VidSTG based on video relation dataset VidOR. The extensive experiments demonstrate the effectiveness of our method.
Weakly-Supervised Video Moment Retrieval via Semantic Completion Network
Nov 19, 2019
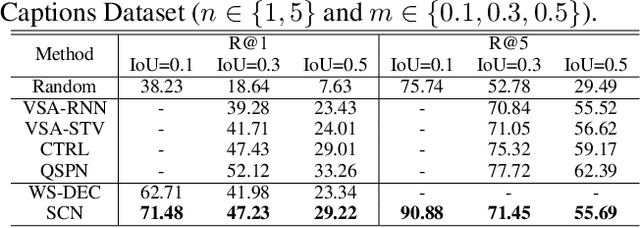
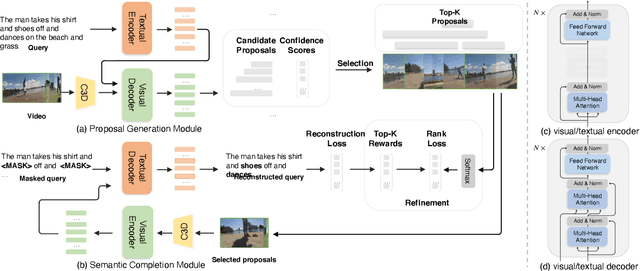
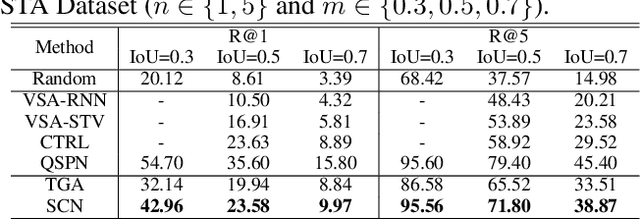
Video moment retrieval is to search the moment that is most relevant to the given natural language query. Existing methods are mostly trained in a fully-supervised setting, which requires the full annotations of temporal boundary for each query. However, manually labeling the annotations is actually time-consuming and expensive. In this paper, we propose a novel weakly-supervised moment retrieval framework requiring only coarse video-level annotations for training. Specifically, we devise a proposal generation module that aggregates the context information to generate and score all candidate proposals in one single pass. We then devise an algorithm that considers both exploitation and exploration to select top-K proposals. Next, we build a semantic completion module to measure the semantic similarity between the selected proposals and query, compute reward and provide feedbacks to the proposal generation module for scoring refinement. Experiments on the ActivityCaptions and Charades-STA demonstrate the effectiveness of our proposed method.
Deep Bayesian Multi-Target Learning for Recommender Systems
Feb 25, 2019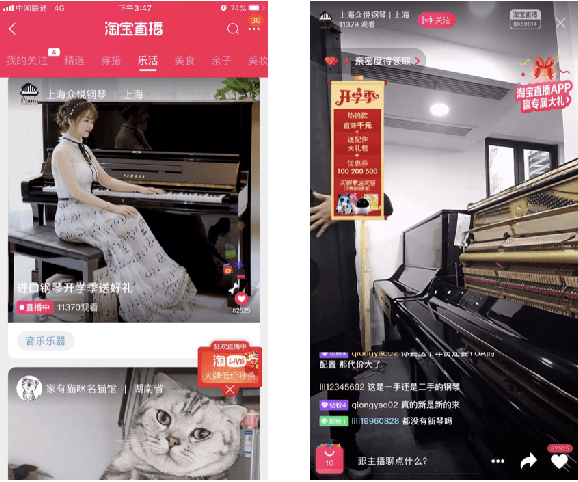
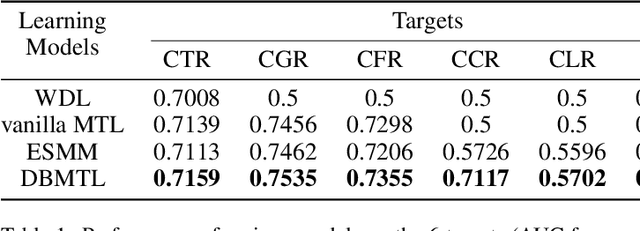
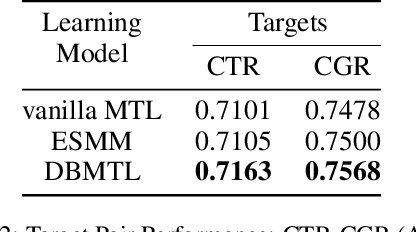
With the increasing variety of services that e-commerce platforms provide, criteria for evaluating their success become also increasingly multi-targeting. This work introduces a multi-target optimization framework with Bayesian modeling of the target events, called Deep Bayesian Multi-Target Learning (DBMTL). In this framework, target events are modeled as forming a Bayesian network, in which directed links are parameterized by hidden layers, and learned from training samples. The structure of Bayesian network is determined by model selection. We applied the framework to Taobao live-streaming recommendation, to simultaneously optimize (and strike a balance) on targets including click-through rate, user stay time in live room, purchasing behaviors and interactions. Significant improvement has been observed for the proposed method over other MTL frameworks and the non-MTL model. Our practice shows that with an integrated causality structure, we can effectively make the learning of a target benefit from other targets, creating significant synergy effects that improve all targets. The neural network construction guided by DBMTL fits in with the general probabilistic model connecting features and multiple targets, taking weaker assumption than the other methods discussed in this paper. This theoretical generality brings about practical generalization power over various targets distributions, including sparse targets and continuous-value ones.