 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraspVLA: a Grasping Foundation Model Pre-trained on Billion-scale Synthetic Action Data
May 06, 2025



Embodied foundation models are gaining increasing attention for their zero-shot generalization, scalability, and adaptability to new tasks through few-shot post-training. However, existing models rely heavily on real-world data, which is costly and labor-intensive to collect. Synthetic data offers a cost-effective alternative, yet its potential remains largely underexplored. To bridge this gap, we explore the feasibility of training Vision-Language-Action models entirely with large-scale synthetic action data. We curate SynGrasp-1B, a billion-frame robotic grasping dataset generated in simulation with photorealistic rendering and extensive domain randomization. Building on this, we present GraspVLA, a VLA model pretrained on large-scale synthetic action data as a foundational model for grasping tasks. GraspVLA integrates autoregressive perception tasks and flow-matching-based action generation into a unified Chain-of-Thought process, enabling joint training on synthetic action data and Internet semantics data. This design helps mitigate sim-to-real gaps and facilitates the transfer of learned actions to a broader range of Internet-covered objects, achieving open-vocabulary generalization in grasping. Extensive evaluations across real-world and simulation benchmarks demonstrate GraspVLA's advanced zero-shot generalizability and few-shot adaptability to specific human preferences. We will release SynGrasp-1B dataset and pre-trained weights to benefit the community.
WeGen: A Unified Model for Interactive Multimodal Generation as We Chat
Mar 03, 2025Existing multimodal generative models fall short as qualified design copilots, as they often struggle to generate imaginative outputs once instructions are less detailed or lack the ability to maintain consistency with the provided references. In this work, we introduce WeGen, a model that unifies multimodal generation and understanding, and promotes their interplay in iterative generation. It can generate diverse results with high creativity for less detailed instructions. And it can progressively refine prior generation results or integrating specific contents from references following the instructions in its chat with users. During this process, it is capable of preserving consistency in the parts that the user is already satisfied with. To this end, we curate a large-scale dataset, extracted from Internet videos, containing rich object dynamics and auto-labeled dynamics descriptions by advanced foundation models to date. These two information are interleaved into a single sequence to enable WeGen to learn consistency-aware generation where the specified dynamics are generated while the consistency of unspecified content is preserved aligned with instructions. Besides, we introduce a prompt self-rewriting mechanism to enhance generation diversity. Extensive experiments demonstrate the effectiveness of unifying multimodal understanding and generation in WeGen and show it achieves state-of-the-art performance across various visual generation benchmarks. These also demonstrate the potential of WeGen as a user-friendly design copilot as desired. The code and models will be available at https://github.com/hzphzp/WeGen.
FetchBot: Object Fetching in Cluttered Shelves via Zero-Shot Sim2Real
Feb 25, 2025



Object fetching from cluttered shelves is an important capability for robots to assist humans in real-world scenarios. Achieving this task demands robotic behaviors that prioritize safety by minimizing disturbances to surrounding objects, an essential but highly challenging requirement due to restricted motion space, limited fields of view, and complex object dynamics. In this paper, we introduce FetchBot, a sim-to-real framework designed to enable zero-shot generalizable and safety-aware object fetching from cluttered shelves in real-world settings. To address data scarcity, we propose an efficient voxel-based method for generating diverse simulated cluttered shelf scenes at scale and train a dynamics-aware reinforcement learning (RL) policy to generate object fetching trajectories within these scenes. This RL policy, which leverages oracle information, is subsequently distilled into a vision-based policy for real-world deployment. Considering that sim-to-real discrepancies stem from texture variations mostly while from geometric dimensions rarely, we propose to adopt depth information estimated by full-fledged depth foundation models as the input for the vision-based policy to mitigate sim-to-real gap. To tackle the challenge of limited views, we design a novel architecture for learning multi-view representations, allowing for comprehensive encoding of cluttered shelf scenes. This enables FetchBot to effectively minimize collisions while fetching objects from varying positions and depths, ensuring robust and safety-aware operation. Both simulation and real-robot experiments demonstrate FetchBot's superior generalization ability, particularly in handling a broad range of real-world scenarios, includ
SoFar: Language-Grounded Orientation Bridges Spatial Reasoning and Object Manipulation
Feb 18, 2025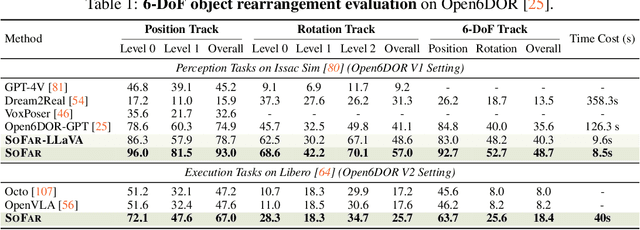

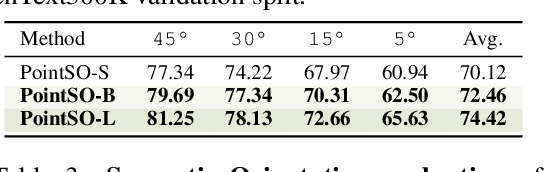
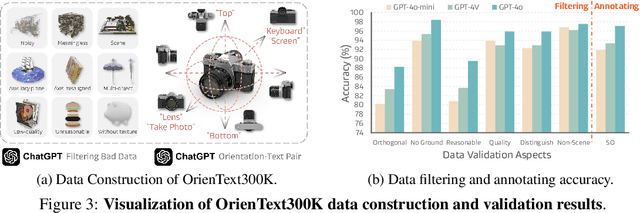
Spatial intelligence is a critical component of embodied AI, promoting robots to understand and interact with their environments. While recent advances have enhanced the ability of VLMs to perceive object locations and positional relationships, they still lack the capability to precisely understand object orientations-a key requirement for tasks involving fine-grained manipulations. Addressing this limitation not only requires geometric reasoning but also an expressive and intuitive way to represent orientation. In this context, we propose that natural language offers a more flexible representation space than canonical frames, making it particularly suitable for instruction-following robotic systems. In this paper, we introduce the concept of semantic orientation, which defines object orientations using natural language in a reference-frame-free manner (e.g., the ''plug-in'' direction of a USB or the ''handle'' direction of a knife). To support this, we construct OrienText300K, a large-scale dataset of 3D models annotated with semantic orientations that link geometric understanding to functional semantics. By integrating semantic orientation into a VLM system, we enable robots to generate manipulation actions with both positional and orientational constraints. Extensive experiments in simulation and real world demonstrate that our approach significantly enhances robotic manipulation capabilities, e.g., 48.7% accuracy on Open6DOR and 74.9% accuracy on SIMPLER.
Uni-NaVid: A Video-based Vision-Language-Action Model for Unifying Embodied Navigation Tasks
Dec 09, 2024A practical navigation agent must be capable of handling a wide range of interaction demands, such as following instructions, searching objects, answering questions, tracking people, and more. Existing models for embodied navigation fall short of serving as practical generalists in the real world, as they are often constrained by specific task configurations or pre-defined maps with discretized waypoints. In this work, we present Uni-NaVid, the first video-based vision-language-action (VLA) model designed to unify diverse embodied navigation tasks and enable seamless navigation for mixed long-horizon tasks in unseen real-world environments. Uni-NaVid achieves this by harmonizing the input and output data configurations for all commonly used embodied navigation tasks and thereby integrating all tasks in one model. For training Uni-NaVid, we collect 3.6 million navigation data samples in total from four essential navigation sub-tasks and foster synergy in learning across them. Extensive experiments on comprehensive navigation benchmarks clearly demonstrate the advantages of unification modeling in Uni-NaVid and show it achieves state-of-the-art performance. Additionally, real-world experiments confirm the model's effectiveness and efficiency, shedding light on its strong generalizability.
Code-as-Monitor: Constraint-aware Visual Programming for Reactive and Proactive Robotic Failure Detection
Dec 05, 2024



Automatic detection and prevention of open-set failures are crucial in closed-loop robotic systems. Recent studies often struggle to simultaneously identify unexpected failures reactively after they occur and prevent foreseeable ones proactively. To this end, we propose Code-as-Monitor (CaM), a novel paradigm leveraging the vision-language model (VLM) for both open-set reactive and proactive failure detection. The core of our method is to formulate both tasks as a unified set of spatio-temporal constraint satisfaction problems and use VLM-generated code to evaluate them for real-time monitoring. To enhance the accuracy and efficiency of monitoring, we further introduce constraint elements that abstract constraint-related entities or their parts into compact geometric elements. This approach offers greater generality, simplifies tracking, and facilitates constraint-aware visual programming by leveraging these elements as visual prompts. Experiments show that CaM achieves a 28.7% higher success rate and reduces execution time by 31.8% under severe disturbances compared to baselines across three simulators and a real-world setting. Moreover, CaM can be integrated with open-loop control policies to form closed-loop systems, enabling long-horizon tasks in cluttered scenes with dynamic environments.
A General Theory for Compositional Generalization
May 20, 2024Compositional Generalization (CG) embodies the ability to comprehend novel combinations of familiar concepts, representing a significant cognitive leap in human intellectual advancement. Despite its critical importance, the deep neural network (DNN) faces challenges in addressing the compositional generalization problem, prompting considerable research interest. However, existing theories often rely on task-specific assumptions, constraining the comprehensive understanding of CG. This study aims to explore compositional generalization from a task-agnostic perspective, offering a complementary viewpoint to task-specific analyses. The primary challenge is to define CG without overly restricting its scope, a feat achieved by identifying its fundamental characteristics and basing the definition on them. Using this definition, we seek to answer the question "what does the ultimate solution to CG look like?" through the following theoretical findings: 1) the first No Free Lunch theorem in CG, indicating the absence of general solutions; 2) a novel generalization bound applicable to any CG problem, specifying the conditions for an effective CG solution; and 3) the introduction of the generative effect to enhance understanding of CG problems and their solutions. This paper's significance lies in providing a general theory for CG problems, which, when combined with prior theorems under task-specific scenarios, can lead to a comprehensive understanding of CG.
Text Grouping Adapter: Adapting Pre-trained Text Detector for Layout Analysis
May 13, 2024



Significant progress has been made in scene text detection models since the rise of deep learning, but scene text layout analysis, which aims to group detected text instances as paragraphs, has not kept pace. Previous works either treated text detection and grouping using separate models, or train a model from scratch while using a unified one. All of them have not yet made full use of the already well-trained text detectors and easily obtainable detection datasets. In this paper, we present Text Grouping Adapter (TGA), a module that can enable the utilization of various pre-trained text detectors to learn layout analysis, allowing us to adopt a well-trained text detector right off the shelf or just fine-tune it efficiently. Designed to be compatible with various text detector architectures, TGA takes detected text regions and image features as universal inputs to assemble text instance features. To capture broader contextual information for layout analysis, we propose to predict text group masks from text instance features by one-to-many assignment. Our comprehensive experiments demonstrate that, even with frozen pre-trained models, incorporating our TGA into various pre-trained text detectors and text spotters can achieve superior layout analysis performance, simultaneously inheriting generalized text detection ability from pre-training. In the case of full parameter fine-tuning, we can further improve layout analysis performance.
VisualCritic: Making LMMs Perceive Visual Quality Like Humans
Mar 19, 2024



At present, large multimodal models (LMMs) have exhibited impressive generalization capabilities in understanding and generating visual signals. However, they currently still lack sufficient capability to perceive low-level visual quality akin to human perception. Can LMMs achieve this and show the same degree of generalization in this regard? If so, not only could the versatility of LMMs be further enhanced, but also the challenge of poor cross-dataset performance in the field of visual quality assessment could be addressed. In this paper, we explore this question and provide the answer "Yes!". As the result of this initial exploration, we present VisualCritic, the first LMM for broad-spectrum image subjective quality assessment. VisualCritic can be used across diverse data right out of box, without any requirements of dataset-specific adaptation operations like conventional specialist models. As an instruction-following LMM, VisualCritic enables new capabilities of (1) quantitatively measuring the perceptual quality of given images in terms of their Mean Opinion Score (MOS), noisiness, colorfulness, sharpness, and other numerical indicators, (2) qualitatively evaluating visual quality and providing explainable descriptions, (3) discerning whether a given image is AI-generated or photographic. Extensive experiments demonstrate the efficacy of VisualCritic by comparing it with other open-source LMMs and conventional specialist models over both AI-generated and photographic images.
RelationVLM: Making Large Vision-Language Models Understand Visual Relations
Mar 19, 2024



The development of Large Vision-Language Models (LVLMs) is striving to catch up with the success of Large Language Models (LLMs), yet it faces more challenges to be resolved. Very recent works enable LVLMs to localize object-level visual contents and ground text to them. Nonetheless, current LVLMs still struggle to precisely understand visual relations due to the lack of relevant data. In this work, we present RelationVLM, a large vision-language model capable of comprehending various levels and types of relations whether across multiple images or within a video. Specifically, we devise a multi-stage relation-aware training scheme and a series of corresponding data configuration strategies to bestow RelationVLM with the capabilities of understanding semantic relations, temporal associations and geometric transforms. Extensive case studies and quantitative evaluations show RelationVLM has strong capability in understanding such relations and emerges impressive in-context capability of reasoning from few-shot examples by comparison. This work fosters the advancements of LVLMs by enabling them to support a wider range of downstream applications toward artificial general intelligence.