 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoFar: Language-Grounded Orientation Bridges Spatial Reasoning and Object Manipulation
Feb 18, 2025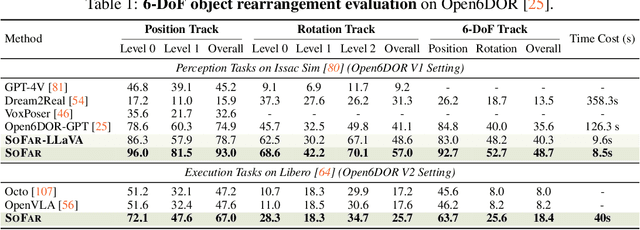

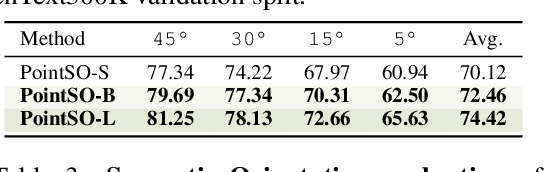
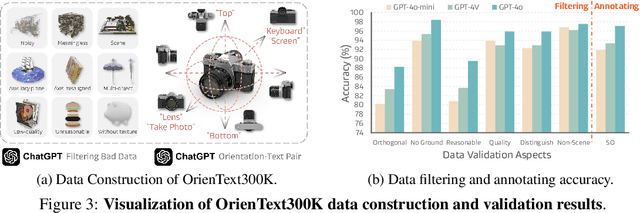
Spatial intelligence is a critical component of embodied AI, promoting robots to understand and interact with their environments. While recent advances have enhanced the ability of VLMs to perceive object locations and positional relationships, they still lack the capability to precisely understand object orientations-a key requirement for tasks involving fine-grained manipulations. Addressing this limitation not only requires geometric reasoning but also an expressive and intuitive way to represent orientation. In this context, we propose that natural language offers a more flexible representation space than canonical frames, making it particularly suitable for instruction-following robotic systems. In this paper, we introduce the concept of semantic orientation, which defines object orientations using natural language in a reference-frame-free manner (e.g., the ''plug-in'' direction of a USB or the ''handle'' direction of a knife). To support this, we construct OrienText300K, a large-scale dataset of 3D models annotated with semantic orientations that link geometric understanding to functional semantics. By integrating semantic orientation into a VLM system, we enable robots to generate manipulation actions with both positional and orientational constraints. Extensive experiments in simulation and real world demonstrate that our approach significantly enhances robotic manipulation capabilities, e.g., 48.7% accuracy on Open6DOR and 74.9% accuracy on SIMPLER.
Learning from Pattern Completion: Self-supervised Controllable Generation
Sep 27, 2024



The human brain exhibits a strong ability to spontaneously associate different visual attributes of the same or similar visual scene, such as associating sketches and graffiti with real-world visual objects, usually without supervising information. In contrast, in the field of artificial intelligence, controllable generation methods like ControlNet heavily rely on annotated training datasets such as depth maps, semantic segmentation maps, and poses, which limits the method's scalability. Inspired by the neural mechanisms that may contribute to the brain's associative power, specifically the cortical modularization and hippocampal pattern completion, here we propose a self-supervised controllable generation (SCG) framework. Firstly, we introduce an equivariant constraint to promote inter-module independence and intra-module correlation in a modular autoencoder network, thereby achieving functional specialization. Subsequently, based on these specialized modules, we employ a self-supervised pattern completion approach for controllable generation training. Experimental results demonstrate that the proposed modular autoencoder effectively achieves functional specialization, including the modular processing of color, brightness, and edge detection, and exhibits brain-like features including orientation selectivity, color antagonism, and center-surround receptive fields. Through self-supervised training, associative generation capabilities spontaneously emerge in SCG, demonstrating excellent generalization ability to various tasks such as associative generation on painting, sketches, and ancient graffiti. Compared to the previous representative method ControlNet, our proposed approach not only demonstrates superior robustness in more challenging high-noise scenarios but also possesses more promising scalability potential due to its self-supervised manner.
Point-GCC: Universal Self-supervised 3D Scene Pre-training via Geometry-Color Contrast
Jun 01, 2023



Geometry and color information provided by the point clouds are both crucial for 3D scene understanding. Two pieces of information characterize the different aspects of point clouds, but existing methods lack an elaborate design for the discrimination and relevance. Hence we explore a 3D self-supervised paradigm that can better utilize the relations of point cloud information. Specifically, we propose a universal 3D scene pre-training framework via Geometry-Color Contrast (Point-GCC), which aligns geometry and color information using a Siamese network. To take care of actual application tasks, we design (i) hierarchical supervision with point-level contrast and reconstruct and object-level contrast based on the novel deep clustering module to close the gap between pre-training and downstream tasks; (ii) architecture-agnostic backbone to adapt for various downstream models. Benefiting from the object-level representation associated with downstream tasks, Point-GCC can directly evaluate model performance and the result demonstrates the effectiveness of our methods. Transfer learning results on a wide range of tasks also show consistent improvements across all datasets. e.g., new state-of-the-art object detection results on SUN RGB-D and S3DIS datasets. Codes will be released at https://github.com/Asterisci/Point-GCC.
Contrast with Reconstruct: Contrastive 3D Representation Learning Guided by Generative Pretraining
Feb 05, 2023



Mainstream 3D representation learning approaches are built upon contrastive or generative modeling pretext tasks, where great improvements in performance on various downstream tasks have been achieved. However, by investigating the methods of these two paradigms, we find that (i) contrastive models are data-hungry that suffer from a representation over-fitting issue; (ii) generative models have a data filling issue that shows inferior data scaling capacity compared to contrastive models. This motivates us to learn 3D representations by sharing the merits of both paradigms, which is non-trivial due to the pattern difference between the two paradigms. In this paper, we propose contrast with reconstruct (ReCon) that unifies these two paradigms. ReCon is trained to learn from both generative modeling teachers and cross-modal contrastive teachers through ensemble distillation, where the generative student guides the contrastive student. An encoder-decoder style ReCon-block is proposed that transfers knowledge through cross attention with stop-gradient, which avoids pretraining over-fitting and pattern difference issues. ReCon achieves a new state-of-the-art in 3D representation learning, e.g., 91.26% accuracy on ScanObjectNN. Codes will be released at https://github.com/qizekun/ReCon.
Language-Assisted 3D Feature Learning for Semantic Scene Understanding
Dec 11, 2022



Learning descriptive 3D features is crucial for understanding 3D scenes with diverse objects and complex structures. However, it is usually unknown whether important geometric attributes and scene context obtain enough emphasis in an end-to-end trained 3D scene understanding network. To guide 3D feature learning toward important geometric attributes and scene context, we explore the help of textual scene descriptions. Given some free-form descriptions paired with 3D scenes, we extract the knowledge regarding the object relationships and object attributes. We then inject the knowledge to 3D feature learning through three classification-based auxiliary tasks. This language-assisted training can be combined with modern object detection and instance segmentation methods to promote 3D semantic scene understanding, especially in a label-deficient regime. Moreover, the 3D feature learned with language assistance is better aligned with the language features, which can benefit various 3D-language multimodal tasks. Experiments on several benchmarks of 3D-only and 3D-language tasks demonstrate the effectiveness of our language-assisted 3D feature learning. Code is available at https://github.com/Asterisci/Language-Assisted-3D.