 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-G1: Towards General Vision Language Reasoning with Multi-Domain Data Curation
Aug 18, 2025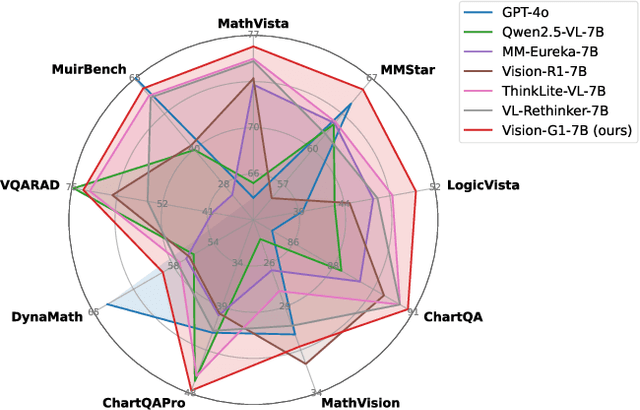

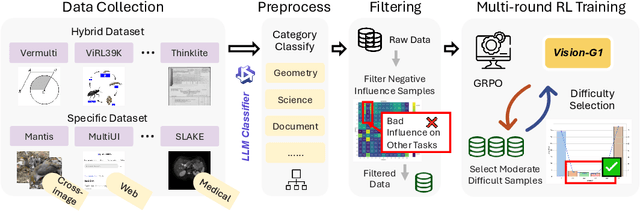

Despite their success, current training pipelines for reasoning VLMs focus on a limited range of tasks, such as mathematical and logical reasoning. As a result, these models face difficulties in generalizing their reasoning capabilities to a wide range of domains, primarily due to the scarcity of readily available and verifiable reward data beyond these narrowly defined areas. Moreover, integrating data from multiple domains is challenging, as the compatibility between domain-specific datasets remains uncertain. To address these limitations, we build a comprehensive RL-ready visual reasoning dataset from 46 data sources across 8 dimensions, covering a wide range of tasks such as infographic, mathematical, spatial, cross-image, graphic user interface, medical, common sense and general science. We propose an influence function based data selection and difficulty based filtering strategy to identify high-quality training samples from this dataset. Subsequently, we train the VLM, referred to as Vision-G1, using multi-round RL with a data curriculum to iteratively improve its visual reasoning capabilities. Our model achieves state-of-the-art performance across various visual reasoning benchmarks, outperforming similar-sized VLMs and even proprietary models like GPT-4o and Gemini-1.5 Flash. The model, code and dataset are publicly available at https://github.com/yuh-zha/Vision-G1.
SimuRA: Towards General Goal-Oriented Agent via Simulative Reasoning Architecture with LLM-Based World Model
Jul 31, 2025

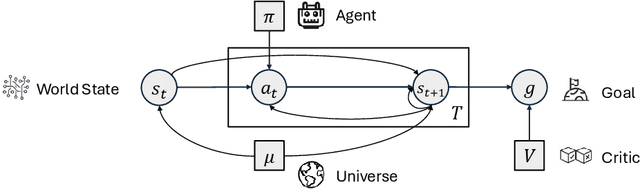

AI agents built on large language models (LLMs) hold enormous promise, but current practice focuses on a one-task-one-agent approach, which not only falls short of scalability and generality, but also suffers from the fundamental limitations of autoregressive LLMs. On the other hand, humans are general agents who reason by mentally simulating the outcomes of their actions and plans. Moving towards a more general and powerful AI agent, we introduce SimuRA, a goal-oriented architecture for generalized agentic reasoning. Based on a principled formulation of optimal agent in any environment, \modelname overcomes the limitations of autoregressive reasoning by introducing a world model for planning via simulation. The generalized world model is implemented using LLM, which can flexibly plan in a wide range of environments using the concept-rich latent space of natural language. Experiments on difficult web browsing tasks show that \modelname improves the success of flight search from 0\% to 32.2\%. World-model-based planning, in particular, shows consistent advantage of up to 124\% over autoregressive planning, demonstrating the advantage of world model simulation as a reasoning paradigm. We are excited about the possibility for training a single, general agent model based on LLMs that can act superintelligently in all environments. To start, we make SimuRA, a web-browsing agent built on \modelname with pretrained LLMs, available as a research demo for public testing.
Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective
Jun 17, 2025



Reinforcement learning (RL) has emerged as a promising approach to improve large language model (LLM) reasoning, yet most open efforts focus narrowly on math and code, limiting our understanding of its broader applicability to general reasoning. A key challenge lies in the lack of reliable, scalable RL reward signals across diverse reasoning domains. We introduce Guru, a curated RL reasoning corpus of 92K verifiable examples spanning six reasoning domains--Math, Code, Science, Logic, Simulation, and Tabular--each built through domain-specific reward design, deduplication, and filtering to ensure reliability and effectiveness for RL training. Based on Guru, we systematically revisit established findings in RL for LLM reasoning and observe significant variation across domains. For example, while prior work suggests that RL primarily elicits existing knowledge from pretrained models, our results reveal a more nuanced pattern: domains frequently seen during pretraining (Math, Code, Science) easily benefit from cross-domain RL training, while domains with limited pretraining exposure (Logic, Simulation, and Tabular) require in-domain training to achieve meaningful performance gains, suggesting that RL is likely to facilitate genuine skill acquisition. Finally, we present Guru-7B and Guru-32B, two models that achieve state-of-the-art performance among open models RL-trained with publicly available data, outperforming best baselines by 7.9% and 6.7% on our 17-task evaluation suite across six reasoning domains. We also show that our models effectively improve the Pass@k performance of their base models, particularly on complex tasks less likely to appear in pretraining data. We release data, models, training and evaluation code to facilitate general-purpose reasoning at: https://github.com/LLM360/Reasoning360
Activation Control for Efficiently Eliciting Long Chain-of-thought Ability of Language Models
May 23, 2025Despite the remarkable reasoning performance, eliciting the long chain-of-thought (CoT) ability in large language models (LLMs) typically requires costly reinforcement learning or supervised fine-tuning on high-quality distilled data. We investigate the internal mechanisms behind this capability and show that a small set of high-impact activations in the last few layers largely governs long-form reasoning attributes, such as output length and self-reflection. By simply amplifying these activations and inserting "wait" tokens, we can invoke the long CoT ability without any training, resulting in significantly increased self-reflection rates and accuracy. Moreover, we find that the activation dynamics follow predictable trajectories, with a sharp rise after special tokens and a subsequent exponential decay. Building on these insights, we introduce a general training-free activation control technique. It leverages a few contrastive examples to identify key activations, and employs simple analytic functions to modulate their values at inference time to elicit long CoTs. Extensive experiments confirm the effectiveness of our method in efficiently eliciting long CoT reasoning in LLMs and improving their performance. Additionally, we propose a parameter-efficient fine-tuning method that trains only a last-layer activation amplification module and a few LoRA layers, outperforming full LoRA fine-tuning on reasoning benchmarks with significantly fewer parameters. Our code and data are publicly released.
Towards General Continuous Memory for Vision-Language Models
May 23, 2025



Language models (LMs) and their extension, vision-language models (VLMs), have achieved remarkable performance across various tasks. However, they still struggle with complex reasoning tasks that require multimodal or multilingual real-world knowledge. To support such capabilities, an external memory system that can efficiently provide relevant multimodal information is essential. Existing approaches generally concatenate image and text tokens into a long sequence as memory, which, however, may drastically increase context length and even degrade performance. In contrast, we propose using continuous memory, a compact set of dense embeddings to more effectively and efficiently represent multimodal and multilingual knowledge. Our key insight is that a VLM can serve as its own continuous memory encoder. We empirically show that this design improves performance on complex multimodal reasoning tasks. Building on this, we introduce a data-efficient and parameter-efficient method to fine-tune the VLM into a memory encoder, requiring only 1.2% of the model's parameters and a small corpus of 15.6K self-synthesized samples. Our approach CoMEM utilizes VLM's original capabilities to encode arbitrary multimodal and multilingual knowledge into just 8 continuous embeddings. Since the inference-time VLM remains frozen, our memory module is plug-and-play and can be flexibly integrated as needed. Extensive experiments across eight multimodal reasoning benchmarks demonstrate the effectiveness of our approach.
Decentralized Arena: Towards Democratic and Scalable Automatic Evaluation of Language Models
May 19, 2025



The recent explosion of large language models (LLMs), each with its own general or specialized strengths, makes scalable, reliable benchmarking more urgent than ever. Standard practices nowadays face fundamental trade-offs: closed-ended question-based benchmarks (eg MMLU) struggle with saturation as newer models emerge, while crowd-sourced leaderboards (eg Chatbot Arena) rely on costly and slow human judges. Recently, automated methods (eg LLM-as-a-judge) shed light on the scalability, but risk bias by relying on one or a few "authority" models. To tackle these issues, we propose Decentralized Arena (dearena), a fully automated framework leveraging collective intelligence from all LLMs to evaluate each other. It mitigates single-model judge bias by democratic, pairwise evaluation, and remains efficient at scale through two key components: (1) a coarse-to-fine ranking algorithm for fast incremental insertion of new models with sub-quadratic complexity, and (2) an automatic question selection strategy for the construction of new evaluation dimensions. Across extensive experiments across 66 LLMs, dearena attains up to 97% correlation with human judgements, while significantly reducing the cost. Our code and data will be publicly released on https://github.com/maitrix-org/de-arena.
Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought
May 18, 2025Large Language Models (LLMs) have demonstrated remarkable performance in many applications, including challenging reasoning problems via chain-of-thoughts (CoTs) techniques that generate ``thinking tokens'' before answering the questions. While existing theoretical works demonstrate that CoTs with discrete tokens boost the capability of LLMs, recent work on continuous CoTs lacks a theoretical understanding of why it outperforms discrete counterparts in various reasoning tasks such as directed graph reachability, a fundamental graph reasoning problem that includes many practical domain applications as special cases. In this paper, we prove that a two-layer transformer with $D$ steps of continuous CoTs can solve the directed graph reachability problem, where $D$ is the diameter of the graph, while the best known result of constant-depth transformers with discrete CoTs requires $O(n^2)$ decoding steps where $n$ is the number of vertices ($D<n$). In our construction, each continuous thought vector is a superposition state that encodes multiple search frontiers simultaneously (i.e., parallel breadth-first search (BFS)), while discrete CoTs must choose a single path sampled from the superposition state, which leads to sequential search that requires many more steps and may be trapped into local solutions. We also performed extensive experiments to verify that our theoretical construction aligns well with the empirical solution obtained via training dynamics. Notably, encoding of multiple search frontiers as a superposition state automatically emerges in training continuous CoTs, without explicit supervision to guide the model to explore multiple paths simultaneously.
Voila: Voice-Language Foundation Models for Real-Time Autonomous Interaction and Voice Role-Play
May 05, 2025A voice AI agent that blends seamlessly into daily life would interact with humans in an autonomous, real-time, and emotionally expressive manner. Rather than merely reacting to commands, it would continuously listen, reason, and respond proactively, fostering fluid, dynamic, and emotionally resonant interactions. We introduce Voila, a family of large voice-language foundation models that make a step towards this vision. Voila moves beyond traditional pipeline systems by adopting a new end-to-end architecture that enables full-duplex, low-latency conversations while preserving rich vocal nuances such as tone, rhythm, and emotion. It achieves a response latency of just 195 milliseconds, surpassing the average human response time. Its hierarchical multi-scale Transformer integrates the reasoning capabilities of large language models (LLMs) with powerful acoustic modeling, enabling natural, persona-aware voice generation -- where users can simply write text instructions to define the speaker's identity, tone, and other characteristics. Moreover, Voila supports over one million pre-built voices and efficient customization of new ones from brief audio samples as short as 10 seconds. Beyond spoken dialogue, Voila is designed as a unified model for a wide range of voice-based applications, including automatic speech recognition (ASR), Text-to-Speech (TTS), and, with minimal adaptation, multilingual speech translation. Voila is fully open-sourced to support open research and accelerate progress toward next-generation human-machine interactions.
Synthesizing Privacy-Preserving Text Data via Finetuning without Finetuning Billion-Scale LLMs
Mar 16, 2025Synthetic data offers a promising path to train models while preserving data privacy. Differentially private (DP) finetuning of large language models (LLMs) as data generator is effective, but is impractical when computation resources are limited. Meanwhile, prompt-based methods such as private evolution, depend heavily on the manual prompts, and ineffectively use private information in their iterative data selection process. To overcome these limitations, we propose CTCL (Data Synthesis with ConTrollability and CLustering), a novel framework for generating privacy-preserving synthetic data without extensive prompt engineering or billion-scale LLM finetuning. CTCL pretrains a lightweight 140M conditional generator and a clustering-based topic model on large-scale public data. To further adapt to the private domain, the generator is DP finetuned on private data for fine-grained textual information, while the topic model extracts a DP histogram representing distributional information. The DP generator then samples according to the DP histogram to synthesize a desired number of data examples. Evaluation across five diverse domains demonstrates the effectiveness of our framework, particularly in the strong privacy regime. Systematic ablation validates the design of each framework component and highlights the scalability of our approach.
Training Large Language Models to Reason in a Continuous Latent Space
Dec 09, 2024



Large language models (LLMs) are restricted to reason in the "language space", where they typically express the reasoning process with a chain-of-thought (CoT) to solve a complex reasoning problem. However, we argue that language space may not always be optimal for reasoning. For example, most word tokens are primarily for textual coherence and not essential for reasoning, while some critical tokens require complex planning and pose huge challenges to LLMs. To explore the potential of LLM reasoning in an unrestricted latent space instead of using natural language, we introduce a new paradigm Coconut (Chain of Continuous Thought). We utilize the last hidden state of the LLM as a representation of the reasoning state (termed "continuous thought"). Rather than decoding this into a word token, we feed it back to the LLM as the subsequent input embedding directly in the continuous space. Experiments show that Coconut can effectively augment the LLM on several reasoning tasks. This novel latent reasoning paradigm leads to emergent advanced reasoning patterns: the continuous thought can encode multiple alternative next reasoning steps, allowing the model to perform a breadth-first search (BFS) to solve the problem, rather than prematurely committing to a single deterministic path like CoT. Coconut outperforms CoT in certain logical reasoning tasks that require substantial backtracking during planning, with fewer thinking tokens during inference. These findings demonstrate the promise of latent reasoning and offer valuable insights for future research.