 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLung-R1: A Knowledge Graph-Guided LLM for Pulmonary Diagnostic Reasoning
Jun 10, 2026Diagnosing pulmonary diseases requires integrating heterogeneous evidence amid phenotypic variability and cross-disease overlap. Although large language models (LLMs) have shown progress on pulmonary knowledge question answering (QA) and information-processing tasks, reliable pulmonary diagnosis requires patient-specific, relation-aware reasoning over electronic medical record (EMR) evidence rather than isolated knowledge recall. We define this gap between pulmonary knowledge and case-level diagnostic reasoning as the Pulmonary Knowledge-to-Diagnosis Gap. To address it, we introduce LungKG, the first structured pulmonary knowledge graph for diagnostic knowledge organization and record-grounded reasoning. LungKG contains 59,038 nodes and 164,308 edges across 15 entity types and 112 relation types, serving as both a reusable pulmonary knowledge resource and the foundation for LungKG-guided model adaptation. Built on LungKG, we propose Lung-R1, a LungKG-guided pulmonary LLM trained through KG-constrained reasoning-chain construction and KG-guided reinforcement learning. In a 20-system evaluation, Lung-R1-14B achieves state-of-the-art performance across Choice, Pulmonary-QA, and EMR Diagnosis, reaching an EMR Diagnosis score of 4.3583 and surpassing the strongest non-Lung-R1 baseline by 0.1476 points. These results demonstrate the value of LungKG-guided training for EMR-based pulmonary diagnosis.
SEP-Attack: A Simple and Effective Paradigm for Transfer-Based Textual Adversarial Attack
May 24, 2026Despite the strong performance of deep neural networks in modern Web and language applications, they remain vulnerable to adversarial attacks, especially transferable attacks that generate adversarial examples using surrogate models without accessing the victim model. Transferable attacks in the text domain are still under-explored, with only a few studies addressing this challenging issue, often with suboptimal results due to equal treatment of submodels or inaccurate estimation of importance scores. To address these challenges, we propose a simple yet effective paradigm for transfer-based textual adversarial attack, named SEP-Attack. Specifically, we employ the Determinantal Point Process (DPP) to generate diverse surrogate ensemble weights, representing the transferability of submodels. Using these weights, we introduce a new metric to evaluate prediction confidence scores, which in turn are used to calculate word importance scores and generate adversarial candidates. Finally, we quantify the transferability score for each candidate and select the top ones as the final transferable adversarial examples. Experiments conducted on four datasets and two real-world APIs validate the efficacy of SEP-Attack, significantly outperforming state-of-the-art baselines.
ChainFlow-VLA: Causal Flow Planning with Vision-Language Models
May 22, 2026Current end-to-end autonomous driving systems are fundamentally limited by a mismatch between temporal causal reasoning and global trajectory consistency. Autoregressive (AR) models capture interaction-aware temporal dependencies via causal factorization, but their step-wise decoding leads to error accumulation and suboptimal global structure. In contrast, diffusion models optimize trajectories globally but lack explicit causal constraints, making them unreliable in interactive and safety-critical scenarios. This dichotomy reveals a deeper issue: existing methods treat causal modeling and global optimization as separate paradigms, without a principled way to unify them within a single trajectory distribution. To address this, we propose ChainFlow-VLA, which unifies causal generation and global refinement within a unified probabilistic framework. We formulate planning as a mixture over AR-induced modes and learn Vision-Language Model (VLM)-conditioned residual distributions over these modes. An autoregressive generator (Chain) produces a discrete set of causal trajectory modes, followed by a diffusion-based refiner (Flow) that leverages VLM hidden states as semantic priors to perform mode-conditioned correction in residual space while preserving causal structure. This straightforward conditioning seamlessly injects high-level scene understanding into fine-grained trajectory adjustments. Experiments demonstrate that ChainFlow-VLA achieves robust planning in ambiguous and long-tail scenarios, achieving a state-of-the-art score of 94.85 on the NAVSIM v1 leaderboard, matching human-level performance (94.8). Code will be available at https://github.com/AFARI-Research/ChainFlow-VLA.
CoWorld-VLA: Thinking in a Multi-Expert World Model for Autonomous Driving
May 11, 2026Vision-Language-Action (VLA) models have emerged as a promising paradigm for end-to-end autonomous driving. However, existing reasoning mechanisms still struggle to provide planning-oriented intermediate representations: textual Chain-of-Thought (CoT) fails to preserve continuous spatiotemporal structure, while latent world reasoning remains difficult to use as a direct condition for action generation. In this paper, we propose CoWorld-VLA, a multi-expert world reasoning framework for autonomous driving, where world representations serve as explicit conditions to guide action planning. CoWorld-VLA extracts complementary world information through multi-source supervision and encodes it into expert tokens within the VLA, thereby providing planner-accessible conditioning signals. Specifically, we construct four types of tokens: semantic interaction, geometric structure, dynamic evolution, and ego trajectory tokens, which respectively model interaction intent, spatial structure, future temporal dynamics, and behavioral goals. During action generation, CoWorld-VLA employs a diffusion-based hierarchical multi-expert fusion planner, which is coupled with scene context throughout the joint denoising process to generate continuous ego trajectories. Experiments show that CoWorld-VLA achieves competitive results in both future scene generation and planning on the NAVSIM v1 benchmark, demonstrating strong performance in collision avoidance and trajectory accuracy. Ablation studies further validate the complementarity of expert tokens and their effectiveness as planning conditions for action generation. Code will be available at https://github.com/potatochip1211/CoWorld-VLA.
NoisyCausal: A Benchmark for Evaluating Causal Reasoning Under Structured Noise
May 05, 2026Causal reasoning in natural language requires identifying relevant variables, understanding their interactions, and reasoning about effects and interventions, often under noisy or ambiguous conditions. While large language models (LLMs) exhibit strong general reasoning abilities, they struggle to disentangle correlation from causation, particularly when observations are partially incorrect or irrelevant information is present. In this work, we introduce NoisyCausal, a new benchmark designed to evaluate causal reasoning under structured noise. Each instance is generated from a ground-truth causal graph and contextualized with a natural language scenario by injecting controllable forms of noise, such as irrelevant distractors, value perturbations, confounding, and partial observability. Moreover, we propose a modular reasoning framework that combines LLMs with explicit causal structure to address these challenges. Our method prompts the LLM to extract variables, construct a causal graph from context, and then reformulates the reasoning task as a structured prompt grounded in this graph. Rather than relying on statistical patterns alone, the LLM is guided by symbolic structure, enabling more interpretable and robust inference. Experimental results show that our method significantly outperforms standard prompting and reasoning baselines on NoisyCausal. Furthermore, it generalizes well to external benchmarks such as Cladder without task-specific tuning. Our findings highlight the importance of combining causal abstractions with language-driven reasoning to achieve faithful and robust causal understanding in LLMs.
TAO-Attack: Toward Advanced Optimization-Based Jailbreak Attacks for Large Language Models
Mar 03, 2026Large language models (LLMs) have achieved remarkable success across diverse applications but remain vulnerable to jailbreak attacks, where attackers craft prompts that bypass safety alignment and elicit unsafe responses. Among existing approaches, optimization-based attacks have shown strong effectiveness, yet current methods often suffer from frequent refusals, pseudo-harmful outputs, and inefficient token-level updates. In this work, we propose TAO-Attack, a new optimization-based jailbreak method. TAO-Attack employs a two-stage loss function: the first stage suppresses refusals to ensure the model continues harmful prefixes, while the second stage penalizes pseudo-harmful outputs and encourages the model toward more harmful completions. In addition, we design a direction-priority token optimization (DPTO) strategy that improves efficiency by aligning candidates with the gradient direction before considering update magnitude. Extensive experiments on multiple LLMs demonstrate that TAO-Attack consistently outperforms state-of-the-art methods, achieving higher attack success rates and even reaching 100\% in certain scenarios.
Vision-G1: Towards General Vision Language Reasoning with Multi-Domain Data Curation
Aug 18, 2025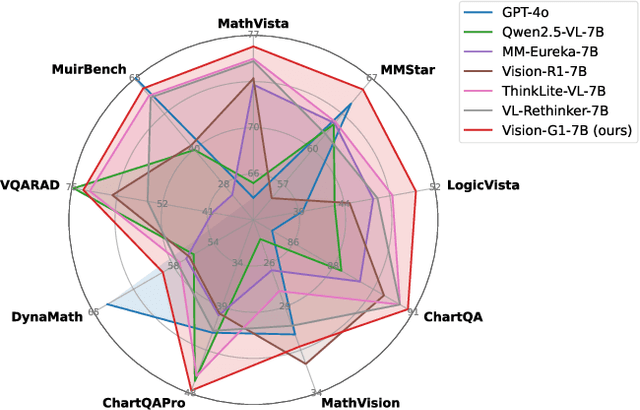

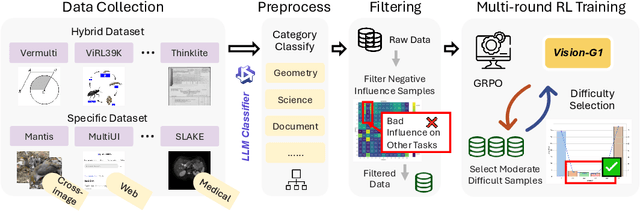

Despite their success, current training pipelines for reasoning VLMs focus on a limited range of tasks, such as mathematical and logical reasoning. As a result, these models face difficulties in generalizing their reasoning capabilities to a wide range of domains, primarily due to the scarcity of readily available and verifiable reward data beyond these narrowly defined areas. Moreover, integrating data from multiple domains is challenging, as the compatibility between domain-specific datasets remains uncertain. To address these limitations, we build a comprehensive RL-ready visual reasoning dataset from 46 data sources across 8 dimensions, covering a wide range of tasks such as infographic, mathematical, spatial, cross-image, graphic user interface, medical, common sense and general science. We propose an influence function based data selection and difficulty based filtering strategy to identify high-quality training samples from this dataset. Subsequently, we train the VLM, referred to as Vision-G1, using multi-round RL with a data curriculum to iteratively improve its visual reasoning capabilities. Our model achieves state-of-the-art performance across various visual reasoning benchmarks, outperforming similar-sized VLMs and even proprietary models like GPT-4o and Gemini-1.5 Flash. The model, code and dataset are publicly available at https://github.com/yuh-zha/Vision-G1.
CusConcept: Customized Visual Concept Decomposition with Diffusion Models
Oct 01, 2024



Enabling generative models to decompose visual concepts from a single image is a complex and challenging problem. In this paper, we study a new and challenging task, customized concept decomposition, wherein the objective is to leverage diffusion models to decompose a single image and generate visual concepts from various perspectives. To address this challenge, we propose a two-stage framework, CusConcept (short for Customized Visual Concept Decomposition), to extract customized visual concept embedding vectors that can be embedded into prompts for text-to-image generation. In the first stage, CusConcept employs a vocabulary-guided concept decomposition mechanism to build vocabularies along human-specified conceptual axes. The decomposed concepts are obtained by retrieving corresponding vocabularies and learning anchor weights. In the second stage, joint concept refinement is performed to enhance the fidelity and quality of generated images. We further curate an evaluation benchmark for assessing the performance of the open-world concept decomposition task. Our approach can effectively generate high-quality images of the decomposed concepts and produce related lexical predictions as secondary outcomes. Extensive qualitative and quantitative experiments demonstrate the effectiveness of CusConcept.
AdaptiveFusion: Adaptive Multi-Modal Multi-View Fusion for 3D Human Body Reconstruction
Sep 07, 2024



Recent advancements in sensor technology and deep learning have led to significant progress in 3D human body reconstruction. However, most existing approaches rely on data from a specific sensor, which can be unreliable due to the inherent limitations of individual sensing modalities. On the other hand, existing multi-modal fusion methods generally require customized designs based on the specific sensor combinations or setups, which limits the flexibility and generality of these methods. Furthermore, conventional point-image projection-based and Transformer-based fusion networks are susceptible to the influence of noisy modalities and sensor poses. To address these limitations and achieve robust 3D human body reconstruction in various conditions, we propose AdaptiveFusion, a generic adaptive multi-modal multi-view fusion framework that can effectively incorporate arbitrary combinations of uncalibrated sensor inputs. By treating different modalities from various viewpoints as equal tokens, and our handcrafted modality sampling module by leveraging the inherent flexibility of Transformer models, AdaptiveFusion is able to cope with arbitrary numbers of inputs and accommodate noisy modalities with only a single training network. Extensive experiments on large-scale human datasets demonstrate the effectiveness of AdaptiveFusion in achieving high-quality 3D human body reconstruction in various environments. In addition, our method achieves superior accuracy compared to state-of-the-art fusion methods.
HQA-Attack: Toward High Quality Black-Box Hard-Label Adversarial Attack on Text
Feb 02, 2024



Black-box hard-label adversarial attack on text is a practical and challenging task, as the text data space is inherently discrete and non-differentiable, and only the predicted label is accessible. Research on this problem is still in the embryonic stage and only a few methods are available. Nevertheless, existing methods rely on the complex heuristic algorithm or unreliable gradient estimation strategy, which probably fall into the local optimum and inevitably consume numerous queries, thus are difficult to craft satisfactory adversarial examples with high semantic similarity and low perturbation rate in a limited query budget. To alleviate above issues, we propose a simple yet effective framework to generate high quality textual adversarial examples under the black-box hard-label attack scenarios, named HQA-Attack. Specifically, after initializing an adversarial example randomly, HQA-attack first constantly substitutes original words back as many as possible, thus shrinking the perturbation rate. Then it leverages the synonym set of the remaining changed words to further optimize the adversarial example with the direction which can improve the semantic similarity and satisfy the adversarial condition simultaneously. In addition, during the optimizing procedure, it searches a transition synonym word for each changed word, thus avoiding traversing the whole synonym set and reducing the query number to some extent. Extensive experimental results on five text classification datasets, three natural language inference datasets and two real-world APIs have shown that the proposed HQA-Attack method outperforms other strong baselines significantly.