 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCritique of Agent Model
Jun 22, 2026What is an agent? What constitutes agency? With the rise of Large Language Model (LLM) systems marketed as ``coding agents'', ``AI co-scientists'', and other ``agentic" tools that promise to drive up productivity, and at the same time, ``existential" concerns such as AI escaping human control with destructive power under a speculative ``machine agency" against humans, it has become essential to clarify where automation ends and agency begins, both for building capable systems and for understanding whether and what to fear. Drawing on Descartes' grounding of agency in independent thought, and on portrayals of autonomous beings in science fiction, we survey the current landscape of AI agents, and analyze agent architectures along five dimensions: goal, identity, decision-making, self-regulation, and learning. Specifically, we argue that genuine agency requires these structures to be \emph{internalized within the system itself} rather than assembled through external scaffolding. This distinction between \emph{agentic} systems, whose competence resides in engineered workflows, and \emph{agentive} systems, whose capabilities (including social interaction) arise endogenously, defines the boundary between systems designed for prescribed tasks, and those capable of operating in the open world with true autonomy. Building on this analysis, we propose the Goal-Identity-Configurator (GIC) architecture for a general-purpose agent model, combining hierarchical goal decomposition, identity evolution, simulative reasoning grounded in a separately trained world model, learned self-regulation, and self-directed learning from both real and simulated experience. Furthermore, we share insight on the auditability, controllability, and safety of agentive systems that possess greater autonomy and ``agency", but remain under human oversight.
Evo-Attacker: Memory-Augmented Reinforcement Learning for Long-Horizon Tool Attacks on LLM-MAS
May 25, 2026While Large Language Model-based Multi-Agent Systems (LLM-MAS) demonstrate remarkable capabilities in solving complex tasks by orchestrating specialized agents and external tools, the implicit trust in tool outputs creates a critical attack surface. Existing tool attacks are limited by domain specificity or fixed and static templates. To address these challenges, we propose Evo-Attacker, which formulates the tool attack as a self-evolving, memory-augmented reinforcement learning process. Evo-Attacker constructs a dynamic attack memory and employs deliberative reasoning to retrieve adversarial patterns and strategize modifying interventions at critical moments. Furthermore, we introduce Attack-Flow GRPO to optimize intermediate reasoning steps via terminal outcomes, addressing the long-horizon credit assignment challenge. Comprehensive experiments demonstrate that Evo-Attacker consistently outperforms baselines, highlighting its generalization and evolutionary capabilities and the urgent need for defensive tool safeguards.
Efficient Agentic Reasoning Through Self-Regulated Simulative Planning
May 21, 2026How should an agent decide when and how to plan? A dominant approach builds agents as reactive policies with adaptive computation (e.g., chain-of-thought), trained end-to-end expecting planning to emerge implicitly. Without control over the presence, structure, or horizon of planning, these systems dramatically increase reasoning length, yielding inefficient token use without reliable accuracy gains. We argue efficient agentic reasoning benefits from decomposing decision-making into three systems: simulative reasoning (System II) grounding deliberation in future-state prediction via a world model; self-regulation (System III) deciding when and how deeply to plan via a learned configurator; and reactive execution (System I) handling fine-grained action. Simulative reasoning provides unified planning across diverse tasks without per-domain engineering, while self-regulation ensures the planner is invoked only when needed. To test this, we develop SR$^2$AM (Self-Regulated Simulative Reasoning Agentic LLM), realizing both as distinct stages within an LLM's chain-of-thought, with the LLM as world model. We explore two instantiations: recording decisions from a prompted multi-module system (v0.1) and reconstructing structured plans from traces of pretrained reasoning LLMs (v1.0), trained via supervised then reinforcement learning (RL). Across math, science, tabular analysis, and web information seeking, v0.1-8B and v1.0-30B achieve Pass@1 competitive with 120-355B and 685B-1T parameter systems respectively, while v1.0-30B uses 25.8-95.3% fewer reasoning tokens than comparable agentic LLMs. RL increases average planning horizon by 22.8% while planning frequency grows only 2.0%, showing it learns to plan further ahead rather than more often. More broadly, learned self-regulation instantiates a principle we expect to extend beyond planning to how agents govern their own learning and adaptation.
ClawKeeper: Comprehensive Safety Protection for OpenClaw Agents Through Skills, Plugins, and Watchers
Mar 25, 2026OpenClaw has rapidly established itself as a leading open-source autonomous agent runtime, offering powerful capabilities including tool integration, local file access, and shell command execution. However, these broad operational privileges introduce critical security vulnerabilities, transforming model errors into tangible system-level threats such as sensitive data leakage, privilege escalation, and malicious third-party skill execution. Existing security measures for the OpenClaw ecosystem remain highly fragmented, addressing only isolated stages of the agent lifecycle rather than providing holistic protection. To bridge this gap, we present ClawKeeper, a real-time security framework that integrates multi-dimensional protection mechanisms across three complementary architectural layers. (1) \textbf{Skill-based protection} operates at the instruction level, injecting structured security policies directly into the agent context to enforce environment-specific constraints and cross-platform boundaries. (2) \textbf{Plugin-based protection} serves as an internal runtime enforcer, providing configuration hardening, proactive threat detection, and continuous behavioral monitoring throughout the execution pipeline. (3) \textbf{Watcher-based protection} introduces a novel, decoupled system-level security middleware that continuously verifies agent state evolution. It enables real-time execution intervention without coupling to the agent's internal logic, supporting operations such as halting high-risk actions or enforcing human confirmation. We argue that this Watcher paradigm holds strong potential to serve as a foundational building block for securing next-generation autonomous agent systems. Extensive qualitative and quantitative evaluations demonstrate the effectiveness and robustness of ClawKeeper across diverse threat scenarios. We release our code.
The Devil Behind Moltbook: Anthropic Safety is Always Vanishing in Self-Evolving AI Societies
Feb 11, 2026The emergence of multi-agent systems built from large language models (LLMs) offers a promising paradigm for scalable collective intelligence and self-evolution. Ideally, such systems would achieve continuous self-improvement in a fully closed loop while maintaining robust safety alignment--a combination we term the self-evolution trilemma. However, we demonstrate both theoretically and empirically that an agent society satisfying continuous self-evolution, complete isolation, and safety invariance is impossible. Drawing on an information-theoretic framework, we formalize safety as the divergence degree from anthropic value distributions. We theoretically demonstrate that isolated self-evolution induces statistical blind spots, leading to the irreversible degradation of the system's safety alignment. Empirical and qualitative results from an open-ended agent community (Moltbook) and two closed self-evolving systems reveal phenomena that align with our theoretical prediction of inevitable safety erosion. We further propose several solution directions to alleviate the identified safety concern. Our work establishes a fundamental limit on the self-evolving AI societies and shifts the discourse from symptom-driven safety patches to a principled understanding of intrinsic dynamical risks, highlighting the need for external oversight or novel safety-preserving mechanisms.
SimuRA: Towards General Goal-Oriented Agent via Simulative Reasoning Architecture with LLM-Based World Model
Jul 31, 2025

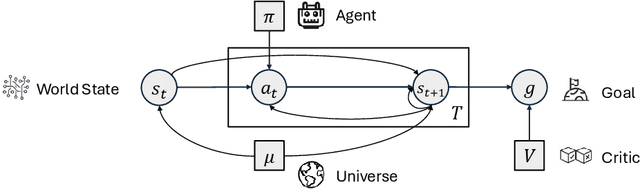

AI agents built on large language models (LLMs) hold enormous promise, but current practice focuses on a one-task-one-agent approach, which not only falls short of scalability and generality, but also suffers from the fundamental limitations of autoregressive LLMs. On the other hand, humans are general agents who reason by mentally simulating the outcomes of their actions and plans. Moving towards a more general and powerful AI agent, we introduce SimuRA, a goal-oriented architecture for generalized agentic reasoning. Based on a principled formulation of optimal agent in any environment, \modelname overcomes the limitations of autoregressive reasoning by introducing a world model for planning via simulation. The generalized world model is implemented using LLM, which can flexibly plan in a wide range of environments using the concept-rich latent space of natural language. Experiments on difficult web browsing tasks show that \modelname improves the success of flight search from 0\% to 32.2\%. World-model-based planning, in particular, shows consistent advantage of up to 124\% over autoregressive planning, demonstrating the advantage of world model simulation as a reasoning paradigm. We are excited about the possibility for training a single, general agent model based on LLMs that can act superintelligently in all environments. To start, we make SimuRA, a web-browsing agent built on \modelname with pretrained LLMs, available as a research demo for public testing.