 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReForm-Eval: Evaluating Large Vision Language Models via Unified Re-Formulation of Task-Oriented Benchmarks
Oct 17, 2023



Recent years have witnessed remarkable progress in the development of large vision-language models (LVLMs). Benefiting from the strong language backbones and efficient cross-modal alignment strategies, LVLMs exhibit surprising capabilities to perceive visual signals and perform visually grounded reasoning. However, the capabilities of LVLMs have not been comprehensively and quantitatively evaluate. Most existing multi-modal benchmarks require task-oriented input-output formats, posing great challenges to automatically assess the free-form text output of LVLMs. To effectively leverage the annotations available in existing benchmarks and reduce the manual effort required for constructing new benchmarks, we propose to re-formulate existing benchmarks into unified LVLM-compatible formats. Through systematic data collection and reformulation, we present the ReForm-Eval benchmark, offering substantial data for evaluating various capabilities of LVLMs. Based on ReForm-Eval, we conduct extensive experiments, thoroughly analyze the strengths and weaknesses of existing LVLMs, and identify the underlying factors. Our benchmark and evaluation framework will be open-sourced as a cornerstone for advancing the development of LVLMs.
Query Structure Modeling for Inductive Logical Reasoning Over Knowledge Graphs
May 23, 2023Logical reasoning over incomplete knowledge graphs to answer complex logical queries is a challenging task. With the emergence of new entities and relations in constantly evolving KGs, inductive logical reasoning over KGs has become a crucial problem. However, previous PLMs-based methods struggle to model the logical structures of complex queries, which limits their ability to generalize within the same structure. In this paper, we propose a structure-modeled textual encoding framework for inductive logical reasoning over KGs. It encodes linearized query structures and entities using pre-trained language models to find answers. For structure modeling of complex queries, we design stepwise instructions that implicitly prompt PLMs on the execution order of geometric operations in each query. We further separately model different geometric operations (i.e., projection, intersection, and union) on the representation space using a pre-trained encoder with additional attention and maxout layers to enhance structured modeling. We conduct experiments on two inductive logical reasoning datasets and three transductive datasets. The results demonstrate the effectiveness of our method on logical reasoning over KGs in both inductive and transductive settings.
AR-Diffusion: Auto-Regressive Diffusion Model for Text Generation
May 19, 2023Diffusion models have gained significant attention in the realm of image generation due to their exceptional performance. Their success has been recently expanded to text generation via generating all tokens within a sequence concurrently. However, natural language exhibits a far more pronounced sequential dependency in comparison to images, and the majority of existing language models are trained with a left-to-right auto-regressive approach. To account for the inherent sequential characteristic of natural language, we introduce Auto-Regressive Diffusion (AR-Diffusion). AR-Diffusion ensures that the generation of tokens on the right depends on the generated ones on the left, a mechanism achieved through employing a dynamic number of denoising steps that vary based on token position. This results in tokens on the left undergoing fewer denoising steps than those on the right, thereby enabling them to generate earlier and subsequently influence the generation of tokens on the right. In a series of experiments on various text generation tasks, including text summarization, machine translation, and common sense generation, AR-Diffusion clearly demonstrated its superiority over existing diffusion language models and that it can be $100\times\sim600\times$ faster when achieving comparable results. Our code is available at https://github.com/microsoft/ProphetNet/tree/master/AR-diffusion.
Unifying Structure Reasoning and Language Model Pre-training for Complex Reasoning
Jan 21, 2023Recent knowledge enhanced pre-trained language models have shown remarkable performance on downstream tasks by incorporating structured knowledge from external sources into language models. However, they usually suffer from a heterogeneous information alignment problem and a noisy knowledge injection problem. For complex reasoning, the contexts contain rich knowledge that typically exists in complex and sparse forms. In order to model structured knowledge in the context and avoid these two problems, we propose to unify structure reasoning and language model pre-training. It identifies four types of elementary knowledge structures from contexts to construct structured queries, and utilizes the box embedding method to conduct explicit structure reasoning along queries during language modeling. To fuse textual and structured semantics, we utilize contextual language representations of knowledge structures to initialize their box embeddings for structure reasoning. We conduct experiments on complex language reasoning and knowledge graph (KG) reasoning tasks. The results show that our model can effectively enhance the performance of complex reasoning of both language and KG modalities.
GENIE: Large Scale Pre-training for Text Generation with Diffusion Model
Dec 22, 2022In this paper, we propose a large-scale language pre-training for text GENeration using dIffusion modEl, which is named GENIE. GENIE is a pre-training sequence-to-sequence text generation model which combines Transformer and diffusion. The diffusion model accepts the latent information from the encoder, which is used to guide the denoising of the current time step. After multiple such denoise iterations, the diffusion model can restore the Gaussian noise to the diverse output text which is controlled by the input text. Moreover, such architecture design also allows us to adopt large scale pre-training on the GENIE. We propose a novel pre-training method named continuous paragraph denoise based on the characteristics of the diffusion model. Extensive experiments on the XSum, CNN/DailyMail, and Gigaword benchmarks shows that GENIE can achieves comparable performance with various strong baselines, especially after pre-training, the generation quality of GENIE is greatly improved. We have also conduct a lot of experiments on the generation diversity and parameter impact of GENIE. The code for GENIE will be made publicly available.
Learned Smartphone ISP on Mobile GPUs with Deep Learning, Mobile AI & AIM 2022 Challenge: Report
Nov 07, 2022



The role of mobile cameras increased dramatically over the past few years, leading to more and more research in automatic image quality enhancement and RAW photo processing. In this Mobile AI challenge, the target was to develop an efficient end-to-end AI-based image signal processing (ISP) pipeline replacing the standard mobile ISPs that can run on modern smartphone GPUs using TensorFlow Lite. The participants were provided with a large-scale Fujifilm UltraISP dataset consisting of thousands of paired photos captured with a normal mobile camera sensor and a professional 102MP medium-format FujiFilm GFX100 camera. The runtime of the resulting models was evaluated on the Snapdragon's 8 Gen 1 GPU that provides excellent acceleration results for the majority of common deep learning ops. The proposed solutions are compatible with all recent mobile GPUs, being able to process Full HD photos in less than 20-50 milliseconds while achieving high fidelity results. A detailed description of all models developed in this challenge is provided in this paper.
Locate Then Ask: Interpretable Stepwise Reasoning for Multi-hop Question Answering
Aug 22, 2022
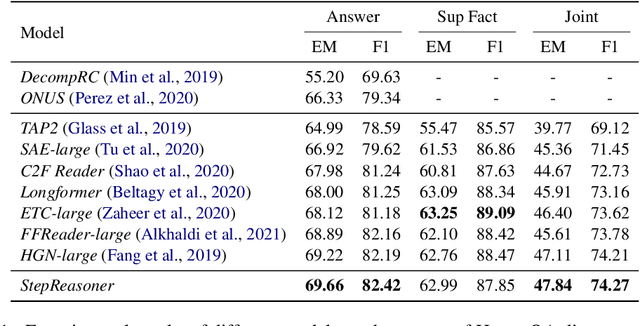
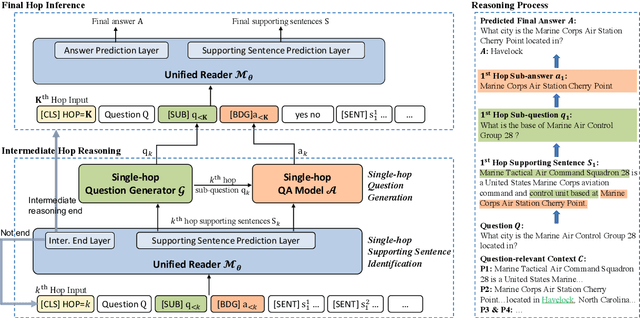
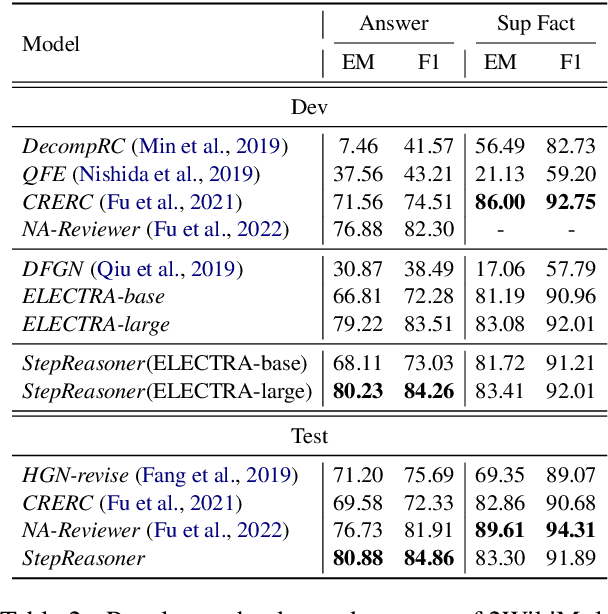
Multi-hop reasoning requires aggregating multiple documents to answer a complex question. Existing methods usually decompose the multi-hop question into simpler single-hop questions to solve the problem for illustrating the explainable reasoning process. However, they ignore grounding on the supporting facts of each reasoning step, which tends to generate inaccurate decompositions. In this paper, we propose an interpretable stepwise reasoning framework to incorporate both single-hop supporting sentence identification and single-hop question generation at each intermediate step, and utilize the inference of the current hop for the next until reasoning out the final result. We employ a unified reader model for both intermediate hop reasoning and final hop inference and adopt joint optimization for more accurate and robust multi-hop reasoning. We conduct experiments on two benchmark datasets HotpotQA and 2WikiMultiHopQA. The results show that our method can effectively boost performance and also yields a better interpretable reasoning process without decomposition supervision.
A Unified Continuous Learning Framework for Multi-modal Knowledge Discovery and Pre-training
Jun 11, 2022
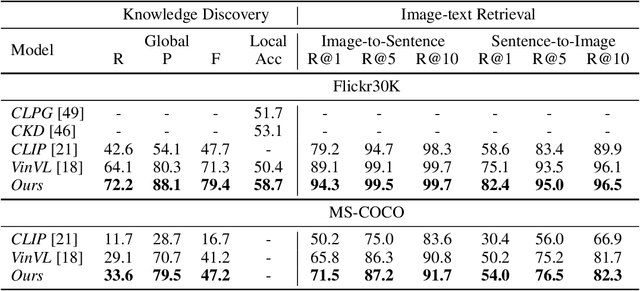
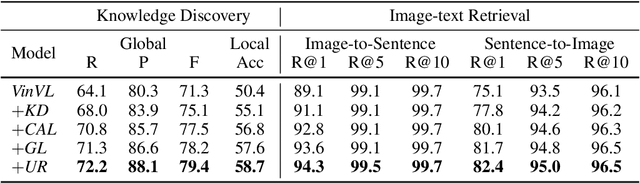
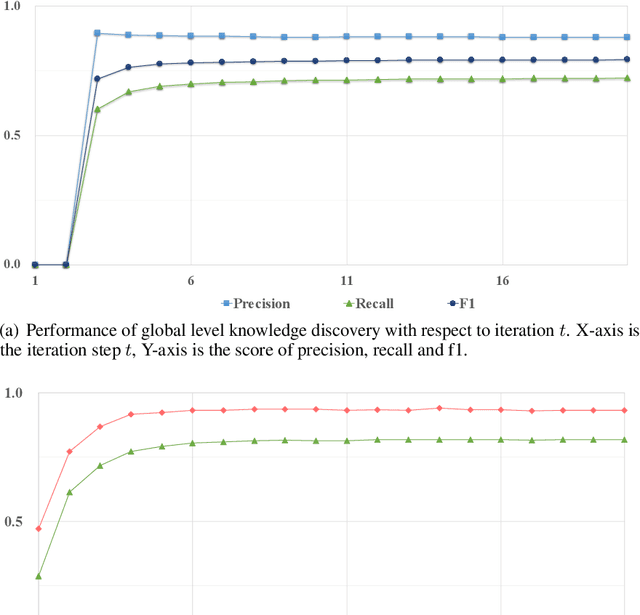
Multi-modal pre-training and knowledge discovery are two important research topics in multi-modal machine learning. Nevertheless, none of existing works make attempts to link knowledge discovery with knowledge guided multi-modal pre-training. In this paper, we propose to unify them into a continuous learning framework for mutual improvement. Taking the open-domain uni-modal datasets of images and texts as input, we maintain a knowledge graph as the foundation to support these two tasks. For knowledge discovery, a pre-trained model is used to identify cross-modal links on the graph. For model pre-training, the knowledge graph is used as the external knowledge to guide the model updating. These two steps are iteratively performed in our framework for continuous learning. The experimental results on MS-COCO and Flickr30K with respect to both knowledge discovery and the pre-trained model validate the effectiveness of our framework.
MVP: Multi-Stage Vision-Language Pre-Training via Multi-Level Semantic Alignment
Jan 29, 2022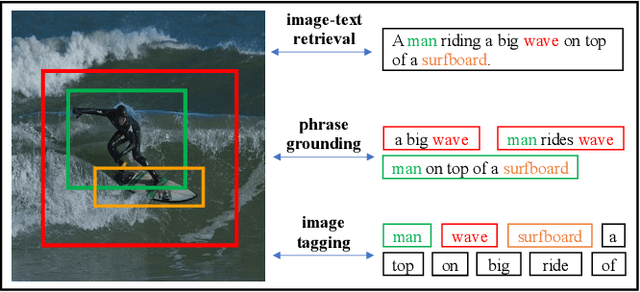
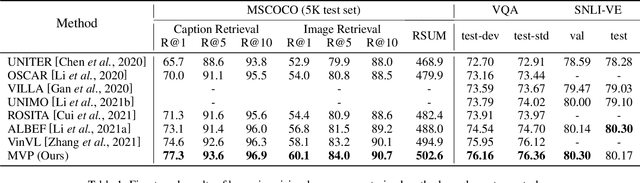
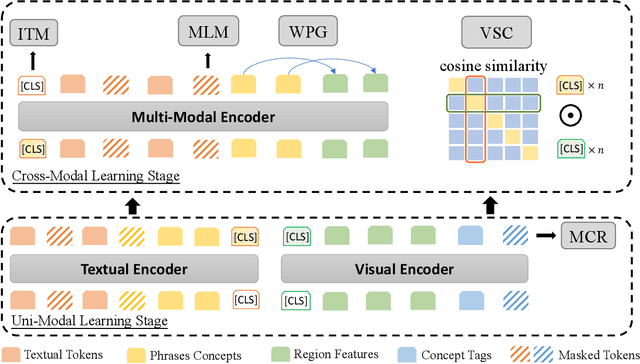
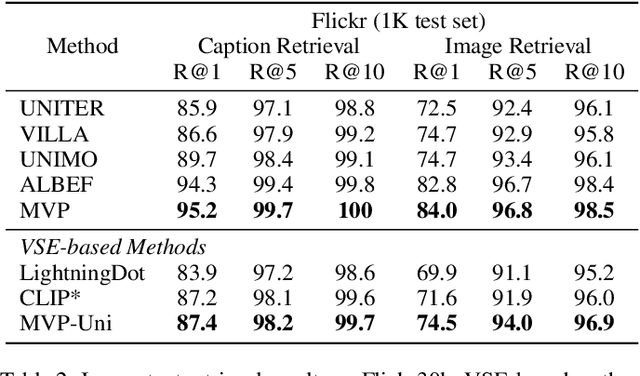
In this paper, we propose a Multi-stage Vision-language Pre-training (MVP) framework to learn cross-modality representation via multi-level semantic alignment. We introduce concepts in both modalities to construct two-level semantic representations for language and vision. Based on the multi-level input, we train the cross-modality model in two stages, namely, uni-modal learning and cross-modal learning. The former stage enforces within-modality interactions to learn multi-level semantics for each single modality. The latter stage enforces interactions across modalities via both coarse-grain and fine-grain semantic alignment tasks. Image-text matching and masked language modeling are then used to further optimize the pre-training model. Our model generates the-state-of-the-art results on several vision and language tasks.
Negative Sample is Negative in Its Own Way: Tailoring Negative Sentences for Image-Text Retrieval
Nov 05, 2021
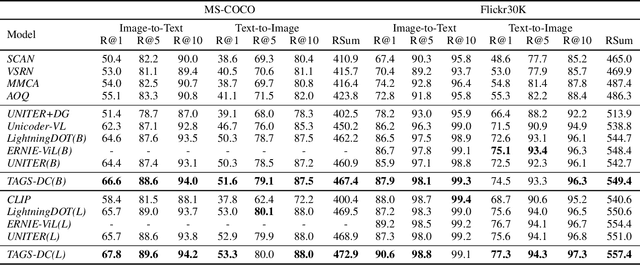

Matching model is essential for Image-Text Retrieval framework. Existing research usually train the model with a triplet loss and explore various strategy to retrieve hard negative sentences in the dataset. We argue that current retrieval-based negative sample construction approach is limited in the scale of the dataset thus fail to identify negative sample of high difficulty for every image. We propose our TAiloring neGative Sentences with Discrimination and Correction (TAGS-DC) to generate synthetic sentences automatically as negative samples. TAGS-DC is composed of masking and refilling to generate synthetic negative sentences with higher difficulty. To keep the difficulty during training, we mutually improve the retrieval and generation through parameter sharing. To further utilize fine-grained semantic of mismatch in the negative sentence, we propose two auxiliary tasks, namely word discrimination and word correction to improve the training. In experiments, we verify the effectiveness of our model on MS-COCO and Flickr30K compared with current state-of-the-art models and demonstrates its robustness and faithfulness in the further analysis. Our code is available in https://github.com/LibertFan/TAGS.