 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning
Jan 28, 2022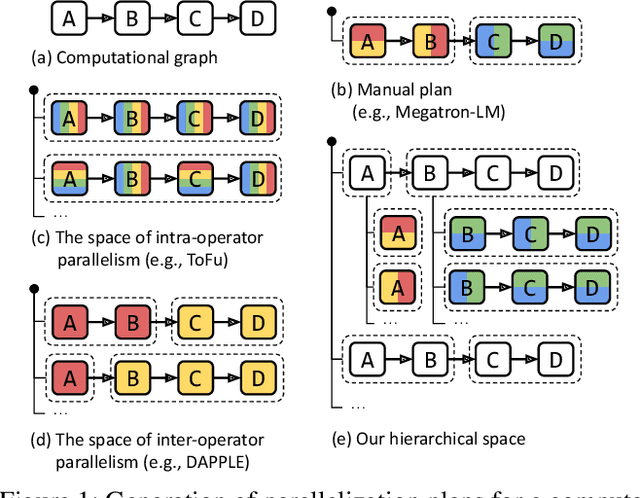
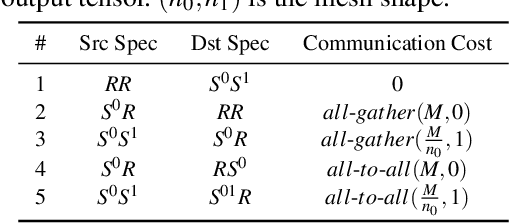

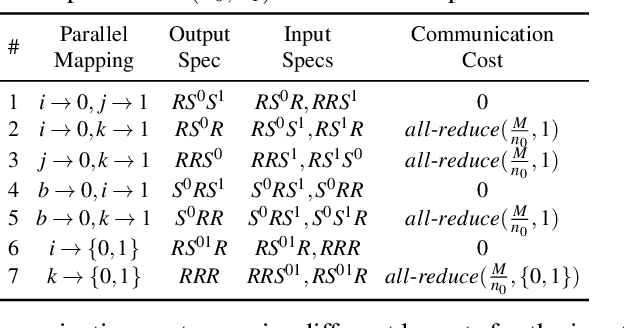
Alpa automates model-parallel training of large deep learning (DL) models by generating execution plans that unify data, operator, and pipeline parallelism. Existing model-parallel training systems either require users to manually create a parallelization plan or automatically generate one from a limited space of model parallelism configurations, which does not suffice to scale out complex DL models on distributed compute devices. Alpa distributes the training of large DL models by viewing parallelisms as two hierarchical levels: inter-operator and intra-operator parallelisms. Based on it, Alpa constructs a new hierarchical space for massive model-parallel execution plans. Alpa designs a number of compilation passes to automatically derive the optimal parallel execution plan in each independent parallelism level and implements an efficient runtime to orchestrate the two-level parallel execution on distributed compute devices. Our evaluation shows Alpa generates parallelization plans that match or outperform hand-tuned model-parallel training systems even on models they are designed for. Unlike specialized systems, Alpa also generalizes to models with heterogeneous architectures and models without manually-designed plans.
GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
Dec 13, 2021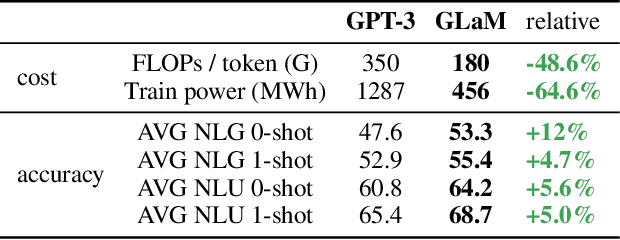
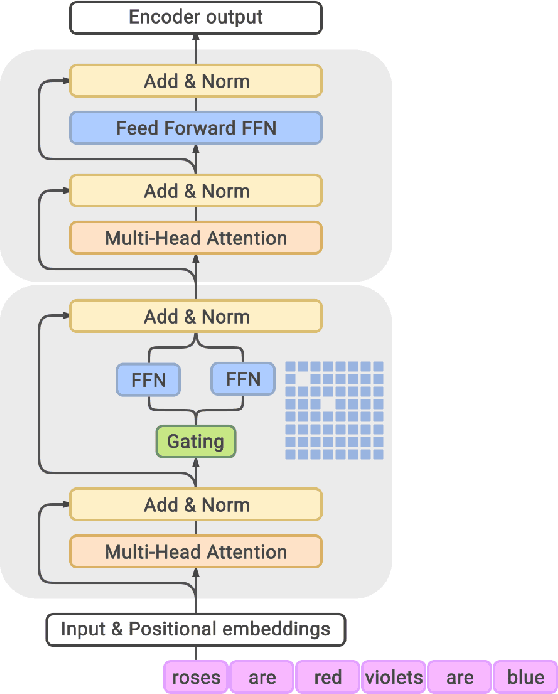
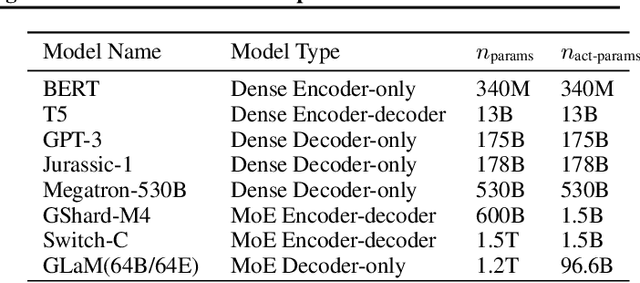
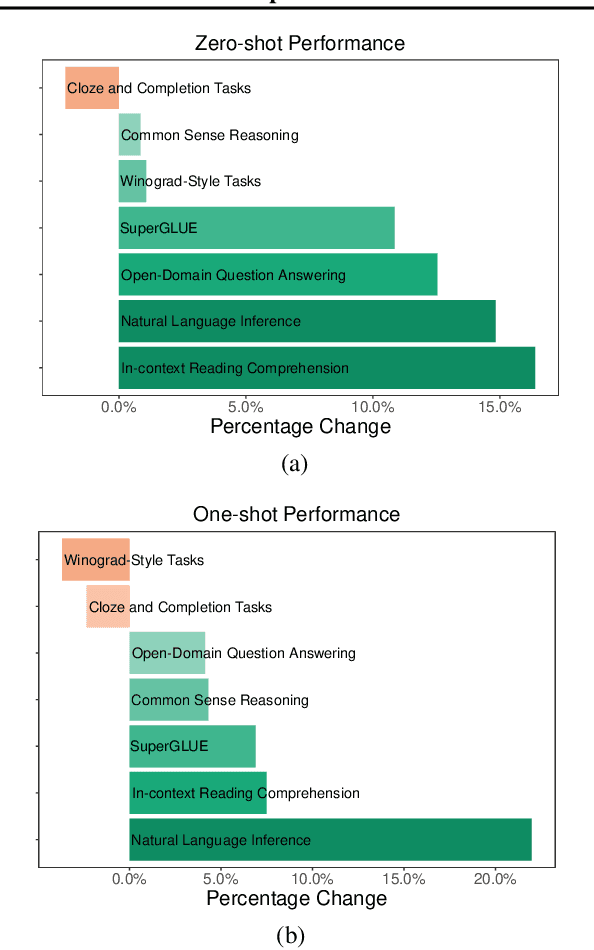
Scaling language models with more data, compute and parameters has driven significant progress in natural language processing. For example, thanks to scaling, GPT-3 was able to achieve strong results on in-context learning tasks. However, training these large dense models requires significant amounts of computing resources. In this paper, we propose and develop a family of language models named GLaM (Generalist Language Model), which uses a sparsely activated mixture-of-experts architecture to scale the model capacity while also incurring substantially less training cost compared to dense variants. The largest GLaM has 1.2 trillion parameters, which is approximately 7x larger than GPT-3. It consumes only 1/3 of the energy used to train GPT-3 and requires half of the computation flops for inference, while still achieving better overall zero-shot and one-shot performance across 29 NLP tasks.
BigSSL: Exploring the Frontier of Large-Scale Semi-Supervised Learning for Automatic Speech Recognition
Oct 01, 2021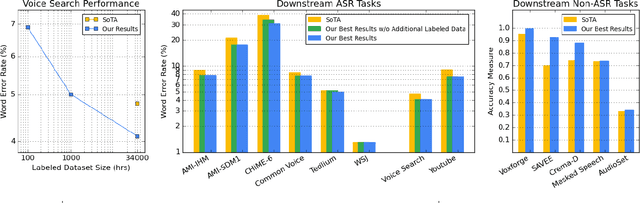
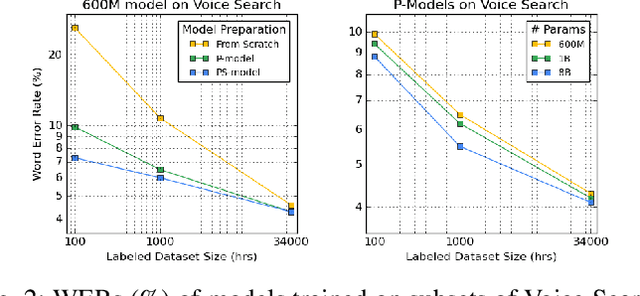
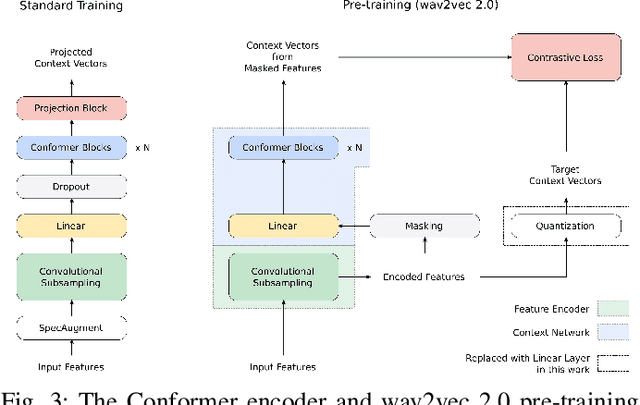
We summarize the results of a host of efforts using giant automatic speech recognition (ASR) models pre-trained using large, diverse unlabeled datasets containing approximately a million hours of audio. We find that the combination of pre-training, self-training and scaling up model size greatly increases data efficiency, even for extremely large tasks with tens of thousands of hours of labeled data. In particular, on an ASR task with 34k hours of labeled data, by fine-tuning an 8 billion parameter pre-trained Conformer model we can match state-of-the-art (SoTA) performance with only 3% of the training data and significantly improve SoTA with the full training set. We also report on the universal benefits gained from using big pre-trained and self-trained models for a large set of downstream tasks that cover a wide range of speech domains and span multiple orders of magnitudes of dataset sizes, including obtaining SoTA performance on many public benchmarks. In addition, we utilize the learned representation of pre-trained networks to achieve SoTA results on non-ASR tasks.
Scene Transformer: A unified multi-task model for behavior prediction and planning
Jun 15, 2021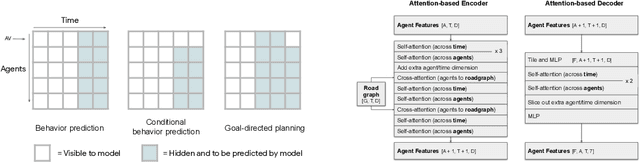
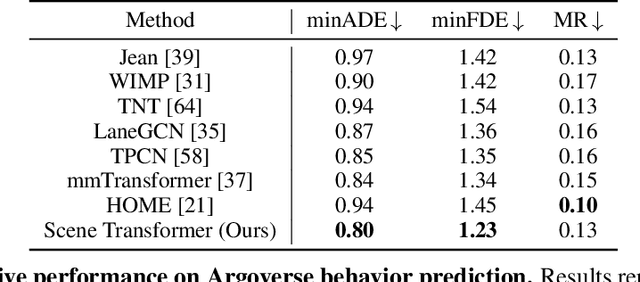
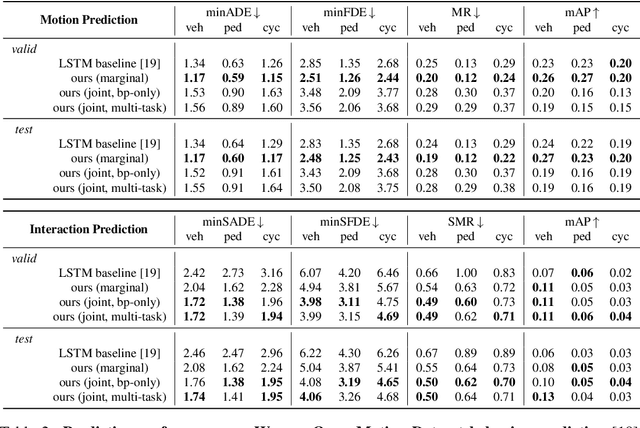
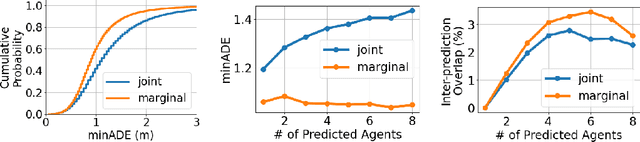
Predicting the future motion of multiple agents is necessary for planning in dynamic environments. This task is challenging for autonomous driving since agents (e.g., vehicles and pedestrians) and their associated behaviors may be diverse and influence each other. Most prior work has focused on first predicting independent futures for each agent based on all past motion, and then planning against these independent predictions. However, planning against fixed predictions can suffer from the inability to represent the future interaction possibilities between different agents, leading to sub-optimal planning. In this work, we formulate a model for predicting the behavior of all agents jointly in real-world driving environments in a unified manner. Inspired by recent language modeling approaches, we use a masking strategy as the query to our model, enabling one to invoke a single model to predict agent behavior in many ways, such as potentially conditioned on the goal or full future trajectory of the autonomous vehicle or the behavior of other agents in the environment. Our model architecture fuses heterogeneous world state in a unified Transformer architecture by employing attention across road elements, agent interactions and time steps. We evaluate our approach on autonomous driving datasets for behavior prediction, and achieve state-of-the-art performance. Our work demonstrates that formulating the problem of behavior prediction in a unified architecture with a masking strategy may allow us to have a single model that can perform multiple motion prediction and planning related tasks effectively.
GSPMD: General and Scalable Parallelization for ML Computation Graphs
May 10, 2021

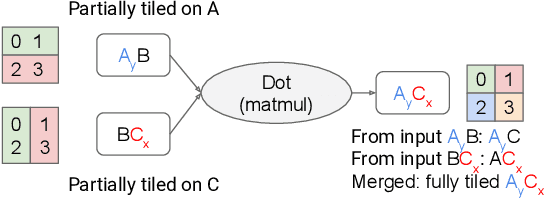
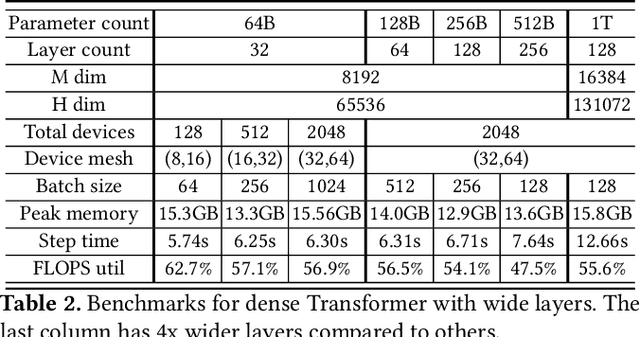
We present GSPMD, an automatic, compiler-based parallelization system for common machine learning computation graphs. It allows users to write programs in the same way as for a single device, then give hints through a few annotations on how to distribute tensors, based on which GSPMD will parallelize the computation. Its representation of partitioning is simple yet general, allowing it to express different or mixed paradigms of parallelism on a wide variety of models. GSPMD infers the partitioning for every operator in the graph based on limited user annotations, making it convenient to scale up existing single-device programs. It solves several technical challenges for production usage, such as static shape constraints, uneven partitioning, exchange of halo data, and nested operator partitioning. These techniques allow GSPMD to achieve 50% to 62% compute utilization on 128 to 2048 Cloud TPUv3 cores for models with up to one trillion parameters. GSPMD produces a single program for all devices, which adjusts its behavior based on a run-time partition ID, and uses collective operators for cross-device communication. This property allows the system itself to be scalable: the compilation time stays constant with increasing number of devices.
3D-MAN: 3D Multi-frame Attention Network for Object Detection
Mar 30, 2021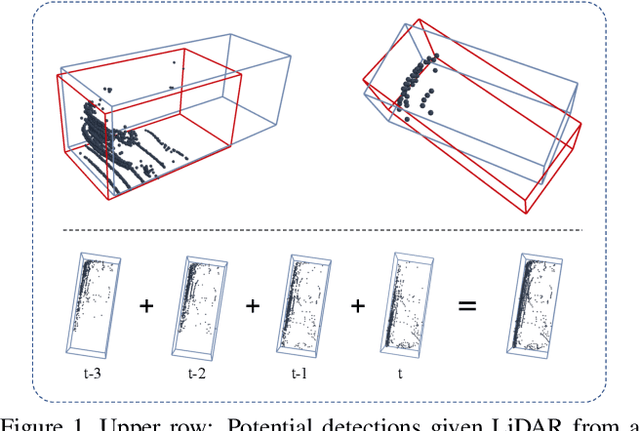

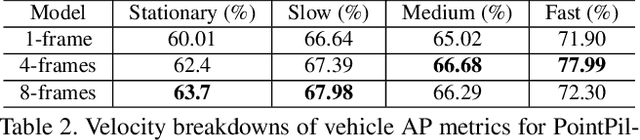
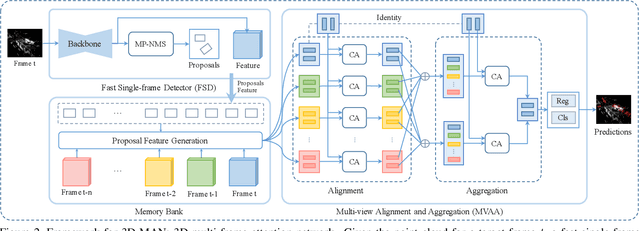
3D object detection is an important module in autonomous driving and robotics. However, many existing methods focus on using single frames to perform 3D detection, and do not fully utilize information from multiple frames. In this paper, we present 3D-MAN: a 3D multi-frame attention network that effectively aggregates features from multiple perspectives and achieves state-of-the-art performance on Waymo Open Dataset. 3D-MAN first uses a novel fast single-frame detector to produce box proposals. The box proposals and their corresponding feature maps are then stored in a memory bank. We design a multi-view alignment and aggregation module, using attention networks, to extract and aggregate the temporal features stored in the memory bank. This effectively combines the features coming from different perspectives of the scene. We demonstrate the effectiveness of our approach on the large-scale complex Waymo Open Dataset, achieving state-of-the-art results compared to published single-frame and multi-frame methods.
Scalable Scene Flow from Point Clouds in the Real World
Mar 15, 2021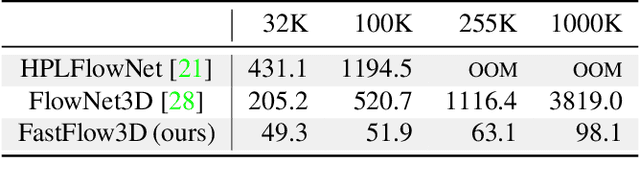
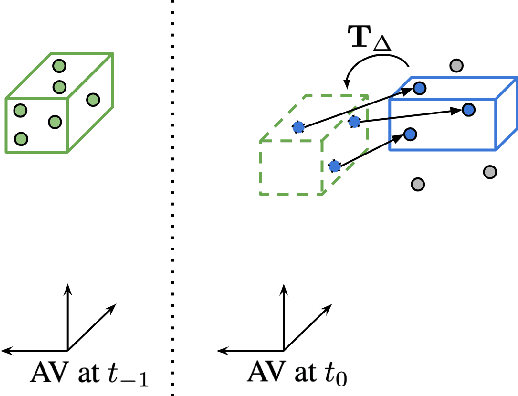
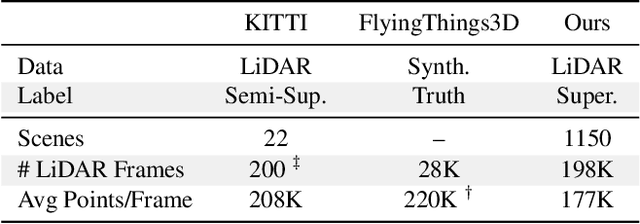
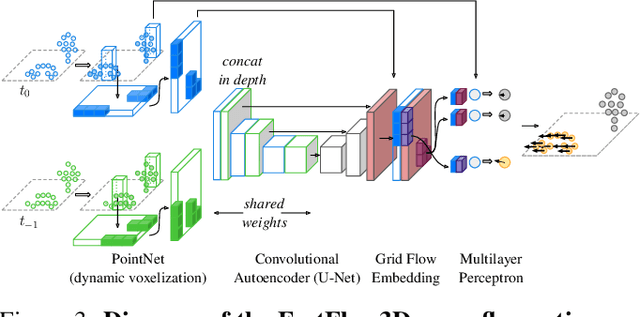
Autonomous vehicles operate in highly dynamic environments necessitating an accurate assessment of which aspects of a scene are moving and where they are moving to. A popular approach to 3D motion estimation -- termed scene flow -- is to employ 3D point cloud data from consecutive LiDAR scans, although such approaches have been limited by the small size of real-world, annotated LiDAR data. In this work, we introduce a new large scale benchmark for scene flow based on the Waymo Open Dataset. The dataset is $\sim$1,000$\times$ larger than previous real-world datasets in terms of the number of annotated frames and is derived from the corresponding tracked 3D objects. We demonstrate how previous works were bounded based on the amount of real LiDAR data available, suggesting that larger datasets are required to achieve state-of-the-art predictive performance. Furthermore, we show how previous heuristics for operating on point clouds such as artificial down-sampling heavily degrade performance, motivating a new class of models that are tractable on the full point cloud. To address this issue, we introduce the model architecture FastFlow3D that provides real time inference on the full point cloud. Finally, we demonstrate that this problem is amenable to techniques from semi-supervised learning by highlighting open problems for generalizing methods for predicting motion on unlabeled objects. We hope that this dataset may provide new opportunities for developing real world scene flow systems and motivate a new class of machine learning problems.
Pseudo-labeling for Scalable 3D Object Detection
Mar 02, 2021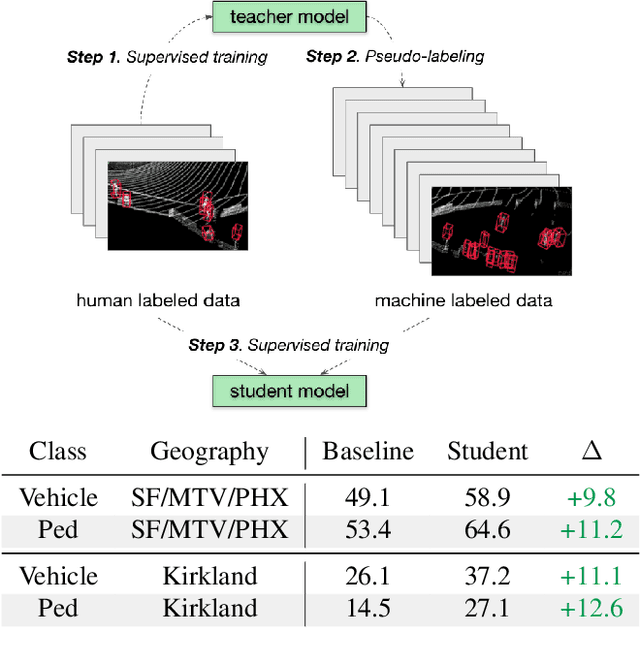
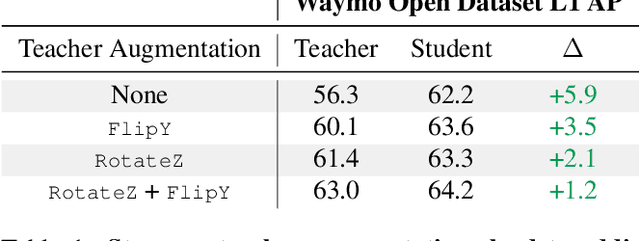
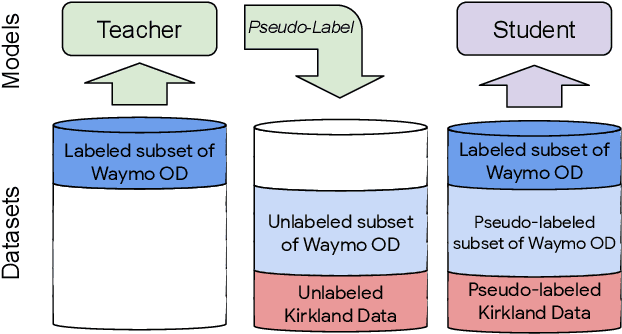
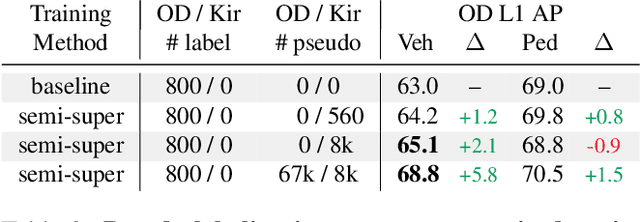
To safely deploy autonomous vehicles, onboard perception systems must work reliably at high accuracy across a diverse set of environments and geographies. One of the most common techniques to improve the efficacy of such systems in new domains involves collecting large labeled datasets, but such datasets can be extremely costly to obtain, especially if each new deployment geography requires additional data with expensive 3D bounding box annotations. We demonstrate that pseudo-labeling for 3D object detection is an effective way to exploit less expensive and more widely available unlabeled data, and can lead to performance gains across various architectures, data augmentation strategies, and sizes of the labeled dataset. Overall, we show that better teacher models lead to better student models, and that we can distill expensive teachers into efficient, simple students. Specifically, we demonstrate that pseudo-label-trained student models can outperform supervised models trained on 3-10 times the amount of labeled examples. Using PointPillars [24], a two-year-old architecture, as our student model, we are able to achieve state of the art accuracy simply by leveraging large quantities of pseudo-labeled data. Lastly, we show that these student models generalize better than supervised models to a new domain in which we only have unlabeled data, making pseudo-label training an effective form of unsupervised domain adaptation.
Computing Cliques and Cavities in Networks
Jan 03, 2021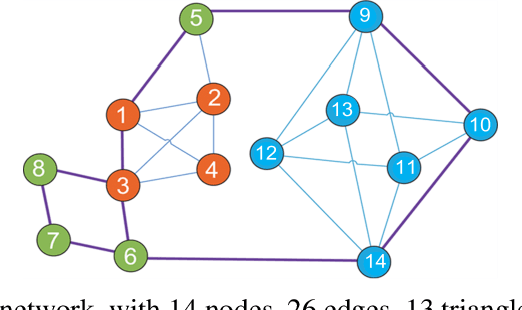

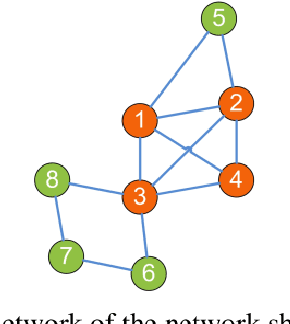
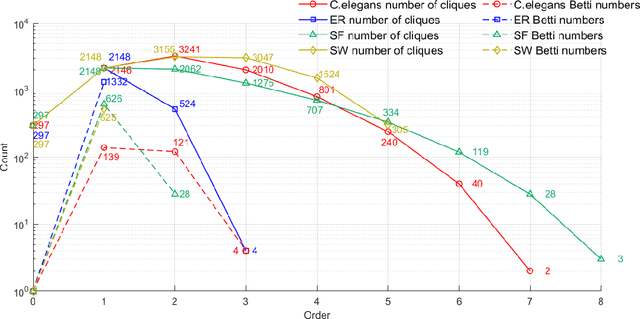
Complex networks have complete subgraphs such as nodes, edges, triangles, etc., referred to as cliques of different orders. Notably, cavities consisting of higher-order cliques have been found playing an important role in brain functions. Since searching for the maximum clique in a large network is an NP-complete problem, we propose using k-core decomposition to determine the computability of a given network subject to limited computing resources. For a computable network, we design a search algorithm for finding cliques of different orders, which also provides the Euler characteristic number. Then, we compute the Betti number by using the ranks of the boundary matrices of adjacent cliques. Furthermore, we design an optimized algorithm for finding cavities of different orders. Finally, we apply the algorithm to the neuronal network of C. elegans in one dataset, and find its all cliques and some cavities of different orders therein, providing a basis for further mathematical analysis and computation of the structure and function of the C. elegans neuronal network.
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Jun 30, 2020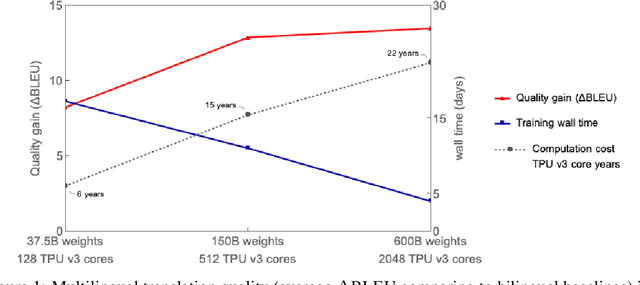
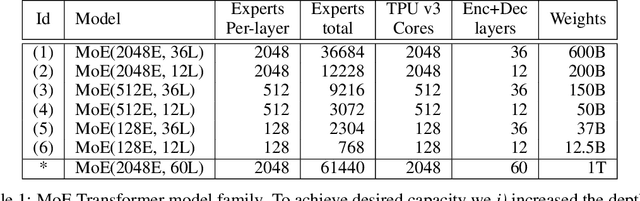
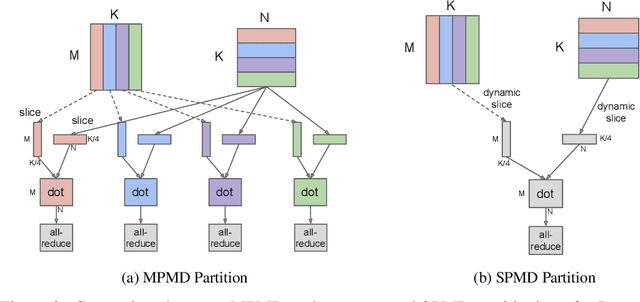
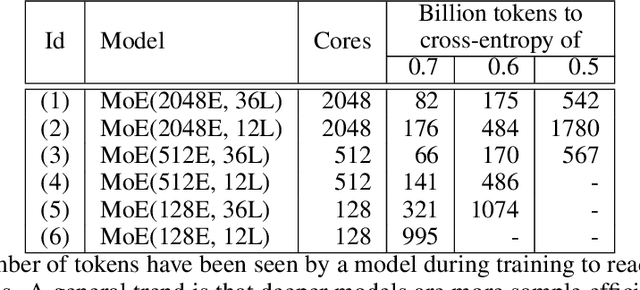
Neural network scaling has been critical for improving the model quality in many real-world machine learning applications with vast amounts of training data and compute. Although this trend of scaling is affirmed to be a sure-fire approach for better model quality, there are challenges on the path such as the computation cost, ease of programming, and efficient implementation on parallel devices. GShard is a module composed of a set of lightweight annotation APIs and an extension to the XLA compiler. It provides an elegant way to express a wide range of parallel computation patterns with minimal changes to the existing model code. GShard enabled us to scale up multilingual neural machine translation Transformer model with Sparsely-Gated Mixture-of-Experts beyond 600 billion parameters using automatic sharding. We demonstrate that such a giant model can efficiently be trained on 2048 TPU v3 accelerators in 4 days to achieve far superior quality for translation from 100 languages to English compared to the prior art.