 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
PaLM: Scaling Language Modeling with Pathways
Apr 19, 2022



Large language models have been shown to achieve remarkable performance across a variety of natural language tasks using few-shot learning, which drastically reduces the number of task-specific training examples needed to adapt the model to a particular application. To further our understanding of the impact of scale on few-shot learning, we trained a 540-billion parameter, densely activated, Transformer language model, which we call Pathways Language Model PaLM. We trained PaLM on 6144 TPU v4 chips using Pathways, a new ML system which enables highly efficient training across multiple TPU Pods. We demonstrate continued benefits of scaling by achieving state-of-the-art few-shot learning results on hundreds of language understanding and generation benchmarks. On a number of these tasks, PaLM 540B achieves breakthrough performance, outperforming the finetuned state-of-the-art on a suite of multi-step reasoning tasks, and outperforming average human performance on the recently released BIG-bench benchmark. A significant number of BIG-bench tasks showed discontinuous improvements from model scale, meaning that performance steeply increased as we scaled to our largest model. PaLM also has strong capabilities in multilingual tasks and source code generation, which we demonstrate on a wide array of benchmarks. We additionally provide a comprehensive analysis on bias and toxicity, and study the extent of training data memorization with respect to model scale. Finally, we discuss the ethical considerations related to large language models and discuss potential mitigation strategies.
Scaling Up Models and Data with $\texttt{t5x}$ and $\texttt{seqio}$
Mar 31, 2022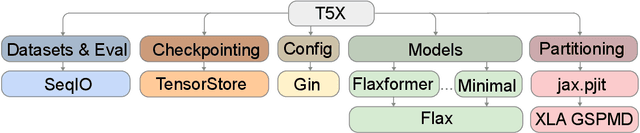
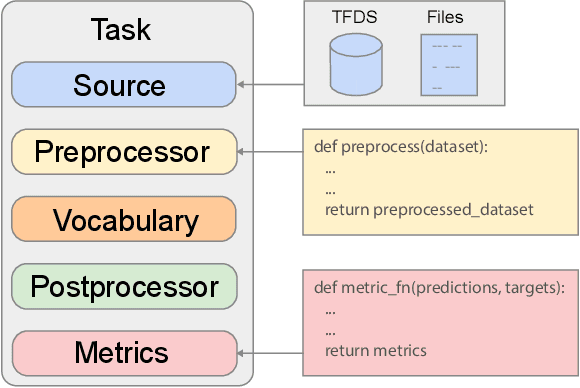
Recent neural network-based language models have benefited greatly from scaling up the size of training datasets and the number of parameters in the models themselves. Scaling can be complicated due to various factors including the need to distribute computation on supercomputer clusters (e.g., TPUs), prevent bottlenecks when infeeding data, and ensure reproducible results. In this work, we present two software libraries that ease these issues: $\texttt{t5x}$ simplifies the process of building and training large language models at scale while maintaining ease of use, and $\texttt{seqio}$ provides a task-based API for simple creation of fast and reproducible training data and evaluation pipelines. These open-source libraries have been used to train models with hundreds of billions of parameters on datasets with multiple terabytes of training data. Along with the libraries, we release configurations and instructions for T5-like encoder-decoder models as well as GPT-like decoder-only architectures. $\texttt{t5x}$ and $\texttt{seqio}$ are open source and available at https://github.com/google-research/t5x and https://github.com/google/seqio, respectively.
Designing Effective Sparse Expert Models
Feb 17, 2022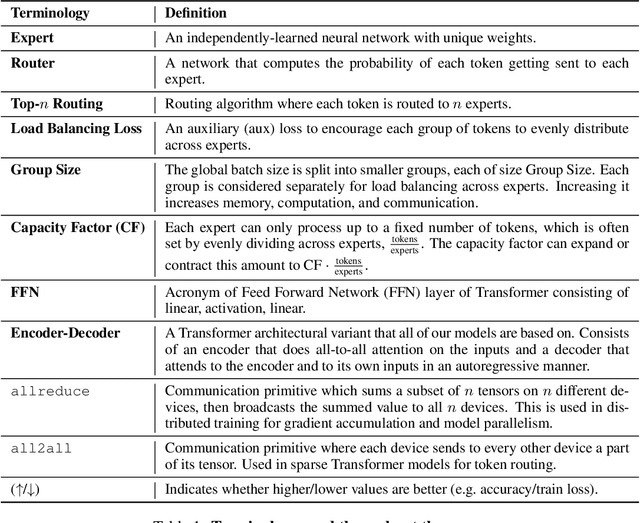
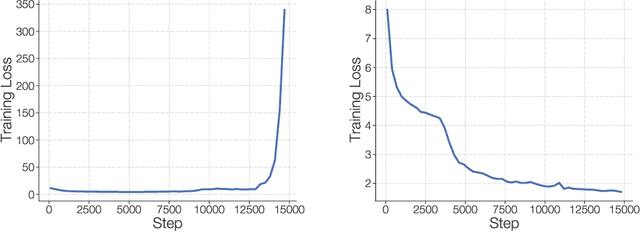

Scale has opened new frontiers in natural language processing -- but at a high cost. In response, Mixture-of-Experts (MoE) and Switch Transformers have been proposed as an energy efficient path to even larger and more capable language models. But advancing the state-of-the-art across a broad set of natural language tasks has been hindered by training instabilities and uncertain quality during fine-tuning. Our work focuses on these issues and acts as a design guide. We conclude by scaling a sparse model to 269B parameters, with a computational cost comparable to a 32B dense encoder-decoder Transformer (Stable and Transferable Mixture-of-Experts or ST-MoE-32B). For the first time, a sparse model achieves state-of-the-art performance in transfer learning, across a diverse set of tasks including reasoning (SuperGLUE, ARC Easy, ARC Challenge), summarization (XSum, CNN-DM), closed book question answering (WebQA, Natural Questions), and adversarially constructed tasks (Winogrande, ANLI R3).
LaMDA: Language Models for Dialog Applications
Feb 10, 2022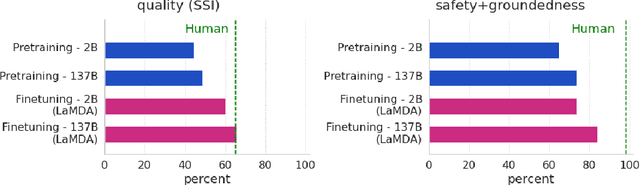
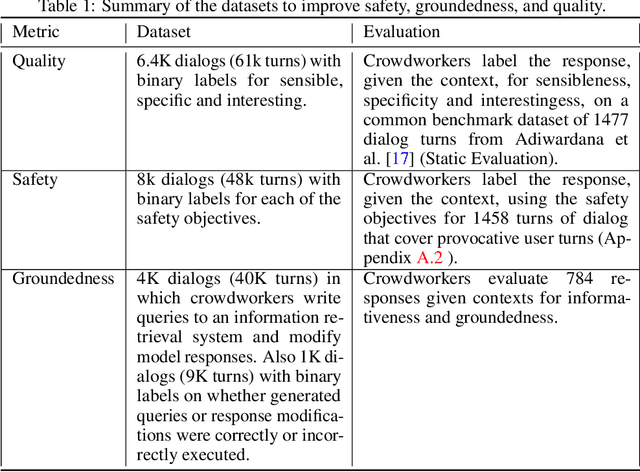
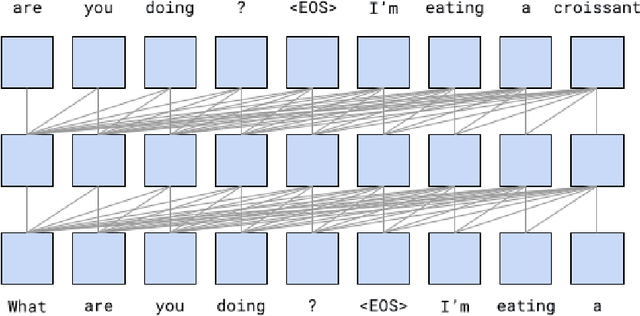

We present LaMDA: Language Models for Dialog Applications. LaMDA is a family of Transformer-based neural language models specialized for dialog, which have up to 137B parameters and are pre-trained on 1.56T words of public dialog data and web text. While model scaling alone can improve quality, it shows less improvements on safety and factual grounding. We demonstrate that fine-tuning with annotated data and enabling the model to consult external knowledge sources can lead to significant improvements towards the two key challenges of safety and factual grounding. The first challenge, safety, involves ensuring that the model's responses are consistent with a set of human values, such as preventing harmful suggestions and unfair bias. We quantify safety using a metric based on an illustrative set of human values, and we find that filtering candidate responses using a LaMDA classifier fine-tuned with a small amount of crowdworker-annotated data offers a promising approach to improving model safety. The second challenge, factual grounding, involves enabling the model to consult external knowledge sources, such as an information retrieval system, a language translator, and a calculator. We quantify factuality using a groundedness metric, and we find that our approach enables the model to generate responses grounded in known sources, rather than responses that merely sound plausible. Finally, we explore the use of LaMDA in the domains of education and content recommendations, and analyze their helpfulness and role consistency.
Primer: Searching for Efficient Transformers for Language Modeling
Sep 17, 2021
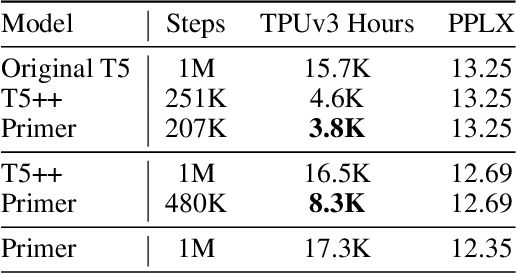
Large Transformer models have been central to recent advances in natural language processing. The training and inference costs of these models, however, have grown rapidly and become prohibitively expensive. Here we aim to reduce the costs of Transformers by searching for a more efficient variant. Compared to previous approaches, our search is performed at a lower level, over the primitives that define a Transformer TensorFlow program. We identify an architecture, named Primer, that has a smaller training cost than the original Transformer and other variants for auto-regressive language modeling. Primer's improvements can be mostly attributed to two simple modifications: squaring ReLU activations and adding a depthwise convolution layer after each Q, K, and V projection in self-attention. Experiments show Primer's gains over Transformer increase as compute scale grows and follow a power law with respect to quality at optimal model sizes. We also verify empirically that Primer can be dropped into different codebases to significantly speed up training without additional tuning. For example, at a 500M parameter size, Primer improves the original T5 architecture on C4 auto-regressive language modeling, reducing the training cost by 4X. Furthermore, the reduced training cost means Primer needs much less compute to reach a target one-shot performance. For instance, in a 1.9B parameter configuration similar to GPT-3 XL, Primer uses 1/3 of the training compute to achieve the same one-shot performance as Transformer. We open source our models and several comparisons in T5 to help with reproducibility.
GSPMD: General and Scalable Parallelization for ML Computation Graphs
May 10, 2021

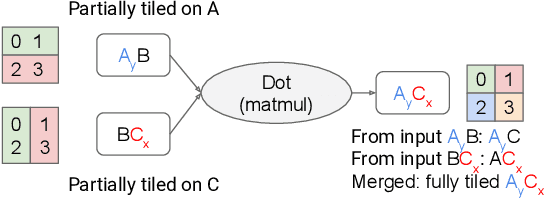
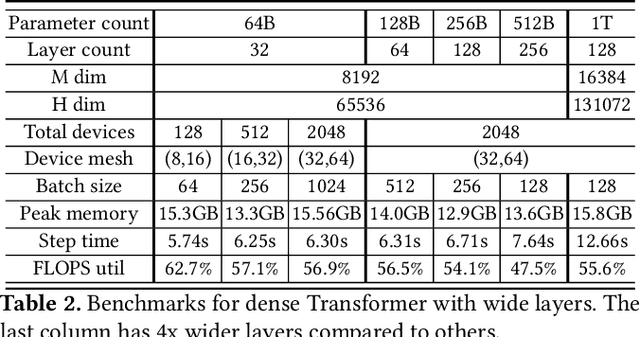
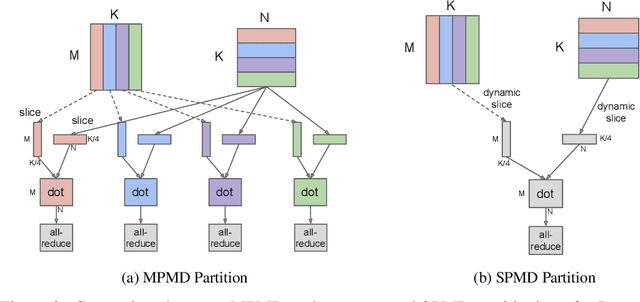
We present GSPMD, an automatic, compiler-based parallelization system for common machine learning computation graphs. It allows users to write programs in the same way as for a single device, then give hints through a few annotations on how to distribute tensors, based on which GSPMD will parallelize the computation. Its representation of partitioning is simple yet general, allowing it to express different or mixed paradigms of parallelism on a wide variety of models. GSPMD infers the partitioning for every operator in the graph based on limited user annotations, making it convenient to scale up existing single-device programs. It solves several technical challenges for production usage, such as static shape constraints, uneven partitioning, exchange of halo data, and nested operator partitioning. These techniques allow GSPMD to achieve 50% to 62% compute utilization on 128 to 2048 Cloud TPUv3 cores for models with up to one trillion parameters. GSPMD produces a single program for all devices, which adjusts its behavior based on a run-time partition ID, and uses collective operators for cross-device communication. This property allows the system itself to be scalable: the compilation time stays constant with increasing number of devices.
Do Transformer Modifications Transfer Across Implementations and Applications?
Feb 23, 2021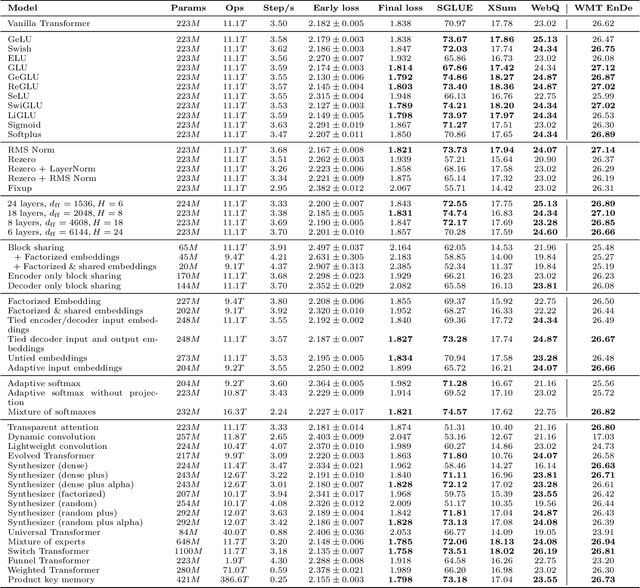
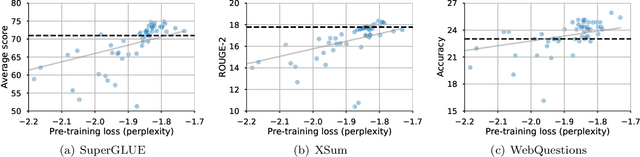
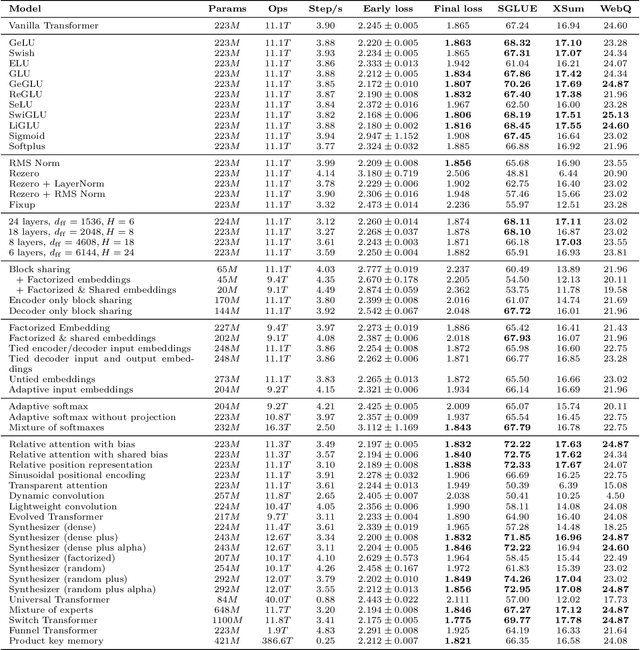
The research community has proposed copious modifications to the Transformer architecture since it was introduced over three years ago, relatively few of which have seen widespread adoption. In this paper, we comprehensively evaluate many of these modifications in a shared experimental setting that covers most of the common uses of the Transformer in natural language processing. Surprisingly, we find that most modifications do not meaningfully improve performance. Furthermore, most of the Transformer variants we found beneficial were either developed in the same codebase that we used or are relatively minor changes. We conjecture that performance improvements may strongly depend on implementation details and correspondingly make some recommendations for improving the generality of experimental results.
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
Jan 11, 2021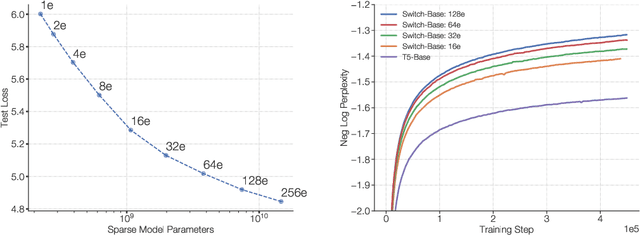
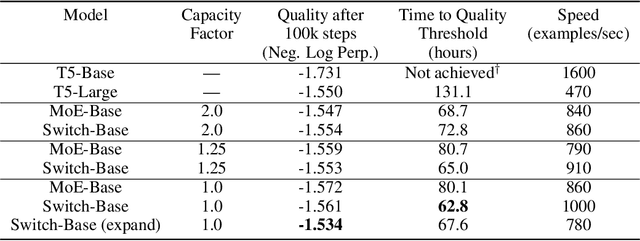
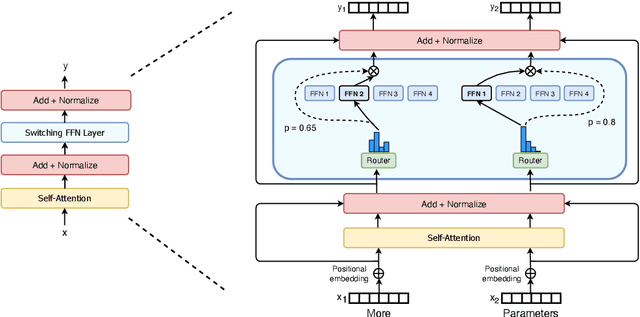
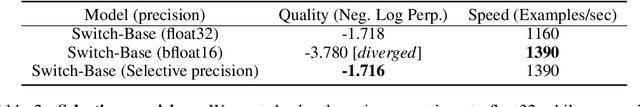
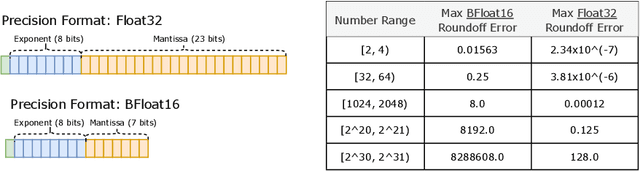
In deep learning, models typically reuse the same parameters for all inputs. Mixture of Experts (MoE) defies this and instead selects different parameters for each incoming example. The result is a sparsely-activated model -- with outrageous numbers of parameters -- but a constant computational cost. However, despite several notable successes of MoE, widespread adoption has been hindered by complexity, communication costs and training instability -- we address these with the Switch Transformer. We simplify the MoE routing algorithm and design intuitive improved models with reduced communication and computational costs. Our proposed training techniques help wrangle the instabilities and we show large sparse models may be trained, for the first time, with lower precision (bfloat16) formats. We design models based off T5-Base and T5-Large to obtain up to 7x increases in pre-training speed with the same computational resources. These improvements extend into multilingual settings where we measure gains over the mT5-Base version across all 101 languages. Finally, we advance the current scale of language models by pre-training up to trillion parameter models on the "Colossal Clean Crawled Corpus" and achieve a 4x speedup over the T5-XXL model.
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Jun 30, 2020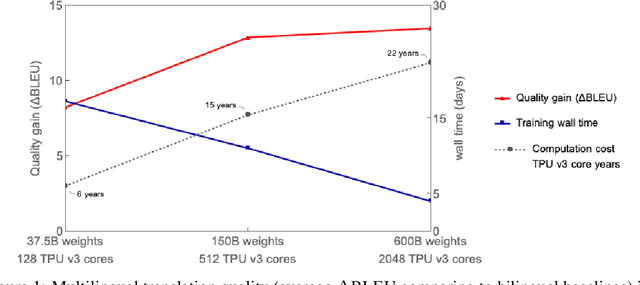
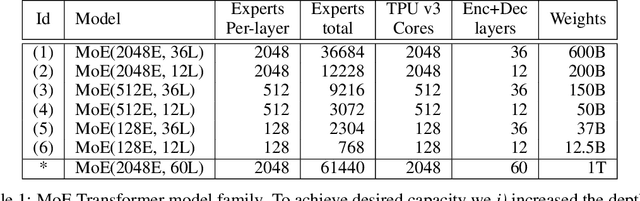
Neural network scaling has been critical for improving the model quality in many real-world machine learning applications with vast amounts of training data and compute. Although this trend of scaling is affirmed to be a sure-fire approach for better model quality, there are challenges on the path such as the computation cost, ease of programming, and efficient implementation on parallel devices. GShard is a module composed of a set of lightweight annotation APIs and an extension to the XLA compiler. It provides an elegant way to express a wide range of parallel computation patterns with minimal changes to the existing model code. GShard enabled us to scale up multilingual neural machine translation Transformer model with Sparsely-Gated Mixture-of-Experts beyond 600 billion parameters using automatic sharding. We demonstrate that such a giant model can efficiently be trained on 2048 TPU v3 accelerators in 4 days to achieve far superior quality for translation from 100 languages to English compared to the prior art.