 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior over Evidence: Stereotype-Driven Diagnosis in LLM-Based L2 Pronunciation Feedback
Jun 13, 2026Large language models are increasingly deployed for written pronunciation feedback in second-language (L2) English learning, under the assumption that their diagnoses are grounded in the supplied speech evidence rather than in priors from pretraining. This assumption is tested on 1,800 L2-Arctic utterances spanning six L1 backgrounds, three audio-capable LLMs, four pronunciation dimensions, and five evidence conditions ranging from a text-only baseline to numeric acoustic features and raw audio. Each (utterance x model x condition x dimension) cell is scored on three metrics: Rating Accuracy (RA) against gold labels, Evidence Coherence (EC) assessing internal consistency without ground truth, and Grounded Correctness (GC) evaluated against gold evidence. Results show three findings across models. First, rating accuracy and grounded reasoning decouple: 39.6% of judged cells contain internally coherent reasoning that supports a wrong rating, against only 15.8% where the reasoning supports a correct rating. Second, phoneme-level feedback converges to a fixed inventory of L2-English difficulty phones that recurs across all six L1 backgrounds and all evidence conditions. Third, acoustic evidence improves the rating only when the supplied feature directly probes the target dimension: textualised F0 range raises pitch-variation grounding from (0.18-0.19) to (0.45-0.62) across all three models, while stress and phoneme correctness, which require target-to-realisation alignment, remain ungrounded. The same audio waveform without textualised F0 values does not reproduce this improvement. These findings indicate that current general-purpose LLMs are more reliable as verbalisers of externally computed pronunciation evidence than as standalone diagnostic engines.
Mimic Human Cognition, Master Multi-Image Reasoning: A Meta-Action Framework for Enhanced Visual Understanding
Jan 12, 2026While Multimodal Large Language Models (MLLMs) excel at single-image understanding, they exhibit significantly degraded performance in multi-image reasoning scenarios. Multi-image reasoning presents fundamental challenges including complex inter-relationships between images and scattered critical information across image sets. Inspired by human cognitive processes, we propose the Cognition-Inspired Meta-Action Framework (CINEMA), a novel approach that decomposes multi-image reasoning into five structured meta-actions: Global, Focus, Hint, Think, and Answer which explicitly modeling the sequential cognitive steps humans naturally employ. For cold-start training, we introduce a Retrieval-Based Tree Sampling strategy that generates high-quality meta-action trajectories to bootstrap the model with reasoning patterns. During reinforcement learning, we adopt a two-stage paradigm: an exploration phase with Diversity-Preserving Strategy to avoid entropy collapse, followed by an annealed exploitation phase with DAPO to gradually strengthen exploitation. To train our model, we construct a dataset of 57k cold-start and 58k reinforcement learning instances spanning multi-image, multi-frame, and single-image tasks. We conduct extensive evaluations on multi-image reasoning benchmarks, video understanding benchmarks, and single-image benchmarks, achieving competitive state-of-the-art performance on several key benchmarks. Our model surpasses GPT-4o on the MUIR and MVMath benchmarks and notably outperforms specialized video reasoning models on video understanding benchmarks, demonstrating the effectiveness and generalizability of our human cognition-inspired reasoning framework.
Systematic Framework of Application Methods for Large Language Models in Language Sciences
Dec 10, 2025Large Language Models (LLMs) are transforming language sciences. However, their widespread deployment currently suffers from methodological fragmentation and a lack of systematic soundness. This study proposes two comprehensive methodological frameworks designed to guide the strategic and responsible application of LLMs in language sciences. The first method-selection framework defines and systematizes three distinct, complementary approaches, each linked to a specific research goal: (1) prompt-based interaction with general-use models for exploratory analysis and hypothesis generation; (2) fine-tuning of open-source models for confirmatory, theory-driven investigation and high-quality data generation; and (3) extraction of contextualized embeddings for further quantitative analysis and probing of model internal mechanisms. We detail the technical implementation and inherent trade-offs of each method, supported by empirical case studies. Based on the method-selection framework, the second systematic framework proposed provides constructed configurations that guide the practical implementation of multi-stage research pipelines based on these approaches. We then conducted a series of empirical experiments to validate our proposed framework, employing retrospective analysis, prospective application, and an expert evaluation survey. By enforcing the strategic alignment of research questions with the appropriate LLM methodology, the frameworks enable a critical paradigm shift in language science research. We believe that this system is fundamental for ensuring reproducibility, facilitating the critical evaluation of LLM mechanisms, and providing the structure necessary to move traditional linguistics from ad-hoc utility to verifiable, robust science.
When Genes Speak: A Semantic-Guided Framework for Spatially Resolved Transcriptomics Data Clustering
Nov 14, 2025Spatial transcriptomics enables gene expression profiling with spatial context, offering unprecedented insights into the tissue microenvironment. However, most computational models treat genes as isolated numerical features, ignoring the rich biological semantics encoded in their symbols. This prevents a truly deep understanding of critical biological characteristics. To overcome this limitation, we present SemST, a semantic-guided deep learning framework for spatial transcriptomics data clustering. SemST leverages Large Language Models (LLMs) to enable genes to "speak" through their symbolic meanings, transforming gene sets within each tissue spot into biologically informed embeddings. These embeddings are then fused with the spatial neighborhood relationships captured by Graph Neural Networks (GNNs), achieving a coherent integration of biological function and spatial structure. We further introduce the Fine-grained Semantic Modulation (FSM) module to optimally exploit these biological priors. The FSM module learns spot-specific affine transformations that empower the semantic embeddings to perform an element-wise calibration of the spatial features, thus dynamically injecting high-order biological knowledge into the spatial context. Extensive experiments on public spatial transcriptomics datasets show that SemST achieves state-of-the-art clustering performance. Crucially, the FSM module exhibits plug-and-play versatility, consistently improving the performance when integrated into other baseline methods.
SentinelAgent: Graph-based Anomaly Detection in Multi-Agent Systems
May 30, 2025The rise of large language model (LLM)-based multi-agent systems (MAS) introduces new security and reliability challenges. While these systems show great promise in decomposing and coordinating complex tasks, they also face multi-faceted risks across prompt manipulation, unsafe tool usage, and emergent agent miscoordination. Existing guardrail mechanisms offer only partial protection, primarily at the input-output level, and fall short in addressing systemic or multi-point failures in MAS. In this work, we present a system-level anomaly detection framework tailored for MAS, integrating structural modeling with runtime behavioral oversight. Our approach consists of two components. First, we propose a graph-based framework that models agent interactions as dynamic execution graphs, enabling semantic anomaly detection at node, edge, and path levels. Second, we introduce a pluggable SentinelAgent, an LLM-powered oversight agent that observes, analyzes, and intervenes in MAS execution based on security policies and contextual reasoning. By bridging abstract detection logic with actionable enforcement, our method detects not only single-point faults and prompt injections but also multi-agent collusion and latent exploit paths. We validate our framework through two case studies, including an email assistant and Microsoft's Magentic-One system, demonstrating its ability to detect covert risks and provide explainable root-cause attribution. Our work lays the foundation for more trustworthy, monitorable, and secure agent-based AI ecosystems.
ChainMarks: Securing DNN Watermark with Cryptographic Chain
May 08, 2025



With the widespread deployment of deep neural network (DNN) models, dynamic watermarking techniques are being used to protect the intellectual property of model owners. However, recent studies have shown that existing watermarking schemes are vulnerable to watermark removal and ambiguity attacks. Besides, the vague criteria for determining watermark presence further increase the likelihood of such attacks. In this paper, we propose a secure DNN watermarking scheme named ChainMarks, which generates secure and robust watermarks by introducing a cryptographic chain into the trigger inputs and utilizes a two-phase Monte Carlo method for determining watermark presence. First, ChainMarks generates trigger inputs as a watermark dataset by repeatedly applying a hash function over a secret key, where the target labels associated with trigger inputs are generated from the digital signature of model owner. Then, the watermarked model is produced by training a DNN over both the original and watermark datasets. To verify watermarks, we compare the predicted labels of trigger inputs with the target labels and determine ownership with a more accurate decision threshold that considers the classification probability of specific models. Experimental results show that ChainMarks exhibits higher levels of robustness and security compared to state-of-the-art watermarking schemes. With a better marginal utility, ChainMarks provides a higher probability guarantee of watermark presence in DNN models with the same level of watermark accuracy.
A Knowledge-enhanced Pathology Vision-language Foundation Model for Cancer Diagnosis
Dec 17, 2024

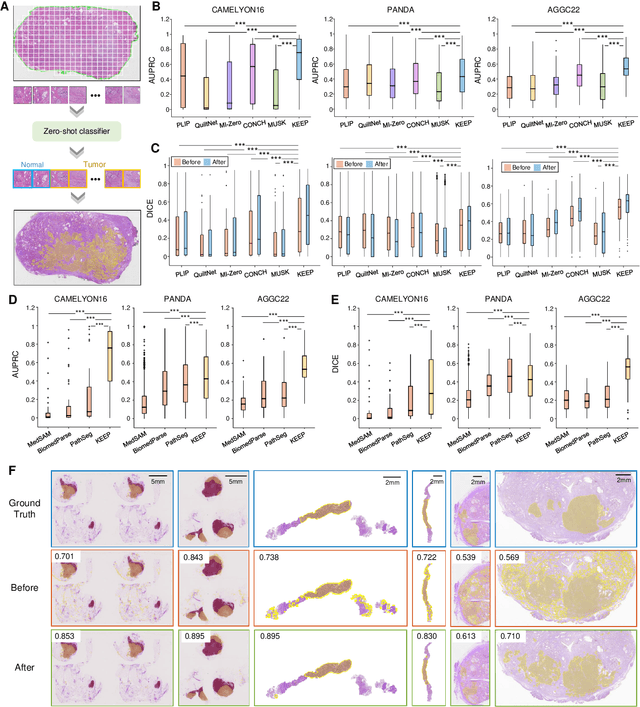

Deep learning has enabled the development of highly robust foundation models for various pathological tasks across diverse diseases and patient cohorts. Among these models, vision-language pre-training, which leverages large-scale paired data to align pathology image and text embedding spaces, and provides a novel zero-shot paradigm for downstream tasks. However, existing models have been primarily data-driven and lack the incorporation of domain-specific knowledge, which limits their performance in cancer diagnosis, especially for rare tumor subtypes. To address this limitation, we establish a Knowledge-enhanced Pathology (KEEP) foundation model that harnesses disease knowledge to facilitate vision-language pre-training. Specifically, we first construct a disease knowledge graph (KG) that covers 11,454 human diseases with 139,143 disease attributes, including synonyms, definitions, and hypernym relations. We then systematically reorganize the millions of publicly available noisy pathology image-text pairs, into 143K well-structured semantic groups linked through the hierarchical relations of the disease KG. To derive more nuanced image and text representations, we propose a novel knowledge-enhanced vision-language pre-training approach that integrates disease knowledge into the alignment within hierarchical semantic groups instead of unstructured image-text pairs. Validated on 18 diverse benchmarks with more than 14,000 whole slide images (WSIs), KEEP achieves state-of-the-art performance in zero-shot cancer diagnostic tasks. Notably, for cancer detection, KEEP demonstrates an average sensitivity of 89.8% at a specificity of 95.0% across 7 cancer types. For cancer subtyping, KEEP achieves a median balanced accuracy of 0.456 in subtyping 30 rare brain cancers, indicating strong generalizability for diagnosing rare tumors.
Dspy-based Neural-Symbolic Pipeline to Enhance Spatial Reasoning in LLMs
Dec 12, 2024



Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks, yet they often struggle with spatial reasoning. This paper presents a novel neural-symbolic framework that enhances LLMs' spatial reasoning abilities through iterative feedback between LLMs and Answer Set Programming (ASP). We evaluate our approach on two benchmark datasets: StepGame and SparQA, implementing three distinct strategies: (1) direct prompting baseline, (2) Facts+Rules prompting, and (3) DSPy-based LLM+ASP pipeline with iterative refinement. Our experimental results demonstrate that the LLM+ASP pipeline significantly outperforms baseline methods, achieving an average 82% accuracy on StepGame and 69% on SparQA, marking improvements of 40-50% and 8-15% respectively over direct prompting. The success stems from three key innovations: (1) effective separation of semantic parsing and logical reasoning through a modular pipeline, (2) iterative feedback mechanism between LLMs and ASP solvers that improves program rate, and (3) robust error handling that addresses parsing, grounding, and solving failures. Additionally, we propose Facts+Rules as a lightweight alternative that achieves comparable performance on complex SparQA dataset, while reducing computational overhead.Our analysis across different LLM architectures (Deepseek, Llama3-70B, GPT-4.0 mini) demonstrates the framework's generalizability and provides insights into the trade-offs between implementation complexity and reasoning capability, contributing to the development of more interpretable and reliable AI systems.
A Pipeline of Neural-Symbolic Integration to Enhance Spatial Reasoning in Large Language Models
Nov 27, 2024Large Language Models (LLMs) have demonstrated impressive capabilities across various tasks. However, LLMs often struggle with spatial reasoning which is one essential part of reasoning and inference and requires understanding complex relationships between objects in space. This paper proposes a novel neural-symbolic framework that enhances LLMs' spatial reasoning abilities. We evaluate our approach on two benchmark datasets: StepGame and SparQA, implementing three distinct strategies: (1) ASP (Answer Set Programming)-based symbolic reasoning, (2) LLM + ASP pipeline using DSPy, and (3) Fact + Logical rules. Our experiments demonstrate significant improvements over the baseline prompting methods, with accuracy increases of 40-50% on StepGame} dataset and 3-13% on the more complex SparQA dataset. The "LLM + ASP" pipeline achieves particularly strong results on the tasks of Finding Relations (FR) and Finding Block (FB) questions, though performance varies across different question types. The impressive results suggest that while neural-symbolic approaches offer promising directions for enhancing spatial reasoning in LLMs, their effectiveness depends heavily on the specific task characteristics and implementation strategies. We propose an integrated, simple yet effective set of strategies using a neural-symbolic pipeline to boost spatial reasoning abilities in LLMs. This pipeline and its strategies demonstrate strong and broader applicability to other reasoning domains in LLMs, such as temporal reasoning, deductive inference etc.
AuscultaBase: A Foundational Step Towards AI-Powered Body Sound Diagnostics
Nov 12, 2024



Auscultation of internal body sounds is essential for diagnosing a range of health conditions, yet its effectiveness is often limited by clinicians' expertise and the acoustic constraints of human hearing, restricting its use across various clinical scenarios. To address these challenges, we introduce AuscultaBase, a foundational framework aimed at advancing body sound diagnostics through innovative data integration and contrastive learning techniques. Our contributions include the following: First, we compile AuscultaBase-Corpus, a large-scale, multi-source body sound database encompassing 11 datasets with 40,317 audio recordings and totaling 322.4 hours of heart, lung, and bowel sounds. Second, we develop AuscultaBase-Model, a foundational diagnostic model for body sounds, utilizing contrastive learning on the compiled corpus. Third, we establish AuscultaBase-Bench, a comprehensive benchmark containing 16 sub-tasks, assessing the performance of various open-source acoustic pre-trained models. Evaluation results indicate that our model outperforms all other open-source models in 12 out of 16 tasks, demonstrating the efficacy of our approach in advancing diagnostic capabilities for body sound analysis.