 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStaying In Character: Perspective-Bounded Memory For Book-Based Role-Playing Agents
Jun 24, 2026Recent LLM role-playing systems build character agents from novels by extracting characters, scenes, and relations. Yet long-narrative role-playing suffers from two failures: Factual Overreach, where shared retrieval or parametric memory lets a character use facts outside its perspective, and Stylistic Monotony, where profile descriptions flatten a character into a fixed voice. To address these failures, we propose REVERIEMEM, a three-layer memory architecture for book-based character agents. The episodic layer stores first-person scene memories; the semantic layer stores visibility-tagged facts; and the personality layer stores situation-dependent speech and behaviour patterns. For evaluation, we construct KBF-QA, a 4,386-question benchmark over eight novels for testing knowledge boundaries. REVERIEMEM improves Knowledge Boundary Fidelity by 34.6 percentage points over the strongest prior method. On BOOKWORLD's five-dimension pairwise narrative protocol, REVERIEMEM achieves a ~ 79% win rate, suggesting that perspective-bounded memory improves both boundary fidelity and character-grounded narrative generation.
SpecDB: LLM-Generated Customized Databases via Feature-Oriented Decomposition
May 29, 2026Mainstream relational databases ship a uniform feature set across deployments, although individual workloads exercise only a fraction of the available subsystems. We investigate whether a database can instead be generated on demand with a feature set matched to the target workload. We present SpecDB, a system that uses large language models (LLMs) to synthesize customized relational databases. We survey 9 production systems and decompose them into 10 functional modules, each further divided into implementation variants. To capture cross-module dependencies, including cases where implementations in disjoint subtrees must be co-designed, we adopt the FODA feature model and extend it with a cooperate edge, yielding a dependency graph DBGraph. SpecDB operationalizes DBGraph through a layered module-construction pipeline in which each module is generated, validated, and integrated by a dedicated subagent (driven by three inner agents: Main, Tester, Architect), and a Refining Agent that iteratively repairs and tunes the assembled database against a user-supplied refining harness with read-only access to existing database source code. A companion selection component translates a natural-language workload description into a set of implementation variants, providing an end-to-end pipeline from workload description to deployable database. We evaluate SpecDB on TPC-C with BenchmarkSQL. The generated database (23,779 lines of Rust) completes 60-minute TPC-C at 1 and 10 warehouses with zero errors. At 10 warehouses it reaches tpmC=130, compared to 128 for PostgreSQL and 127 for MySQL, with comparable latency at ~3% of their code size. Because the agent operates at module-specification level rather than product source, it can in principle combine techniques across system boundaries. Paired with falling LLM costs, generating a purpose-built database for a target workload is becoming straightforward.
OpenHospital: A Thing-in-itself Arena for Evolving and Benchmarking LLM-based Collective Intelligence
Mar 17, 2026Large Language Model (LLM)-based Collective Intelligence (CI) presents a promising approach to overcoming the data wall and continuously boosting the capabilities of LLM agents. However, there is currently no dedicated arena for evolving and benchmarking LLM-based CI. To address this gap, we introduce OpenHospital, an interactive arena where physician agents can evolve CI through interactions with patient agents. This arena employs a data-in-agent-self paradigm that rapidly enhances agent capabilities and provides robust evaluation metrics for benchmarking both medical proficiency and system efficiency. Experiments demonstrate the effectiveness of OpenHospital in both fostering and quantifying CI.
A Hypergraph-Based Framework for Exploratory Business Intelligence
Mar 11, 2026Business Intelligence (BI) analysis is evolving towards Exploratory BI, an iterative, multi-round exploration paradigm where analysts progressively refine their understanding. However, traditional BI systems impose critical limits for Exploratory BI: heavy reliance on expert knowledge, high computational costs, static schemas, and lack of reusability. We present ExBI, a novel system that introduces the hypergraph data model with operators, including Source, Join, and View, to enable dynamic schema evolution and materialized view reuse. Using sampling-based algorithms with provable estimation guarantees, ExBI addresses the computational bottlenecks, while maintaining analytical accuracy. Experiments on LDBC datasets demonstrate that ExBI achieves significant speedups over existing systems: on average 16.21x (up to 146.25x) compared to Neo4j and 46.67x (up to 230.53x) compared to MySQL, while maintaining high accuracy with an average error rate of only 0.27% for COUNT, enabling efficient and accurate large-scale exploratory BI workflows.
OSS-UAgent: An Agent-based Usability Evaluation Framework for Open Source Software
May 29, 2025Usability evaluation is critical to the impact and adoption of open source software (OSS), yet traditional methods relying on human evaluators suffer from high costs and limited scalability. To address these limitations, we introduce OSS-UAgent, an automated, configurable, and interactive agent-based usability evaluation framework specifically designed for open source software. Our framework employs intelligent agents powered by large language models (LLMs) to simulate developers performing programming tasks across various experience levels (from Junior to Expert). By dynamically constructing platform-specific knowledge bases, OSS-UAgent ensures accurate and context-aware code generation. The generated code is automatically evaluated across multiple dimensions, including compliance, correctness, and readability, providing a comprehensive measure of the software's usability. Additionally, our demonstration showcases OSS-UAgent's practical application in evaluating graph analytics platforms, highlighting its effectiveness in automating usability evaluation.
G-Boost: Boosting Private SLMs with General LLMs
Mar 13, 2025Due to the limited computational resources, most Large Language Models (LLMs) developers can only fine-tune Small Language Models (SLMs) on their own data. These private SLMs typically have limited effectiveness. To boost the performance of private SLMs, this paper proposes to ask general LLMs for help. The general LLMs can be APIs or larger LLMs whose inference cost the developers can afford. Specifically, we propose the G-Boost framework where a private SLM adaptively performs collaborative inference with a general LLM under the guide of process reward. Experiments demonstrate that our framework can significantly boost the performance of private SLMs.
Graphy'our Data: Towards End-to-End Modeling, Exploring and Generating Report from Raw Data
Feb 24, 2025


Large Language Models (LLMs) have recently demonstrated remarkable performance in tasks such as Retrieval-Augmented Generation (RAG) and autonomous AI agent workflows. Yet, when faced with large sets of unstructured documents requiring progressive exploration, analysis, and synthesis, such as conducting literature survey, existing approaches often fall short. We address this challenge -- termed Progressive Document Investigation -- by introducing Graphy, an end-to-end platform that automates data modeling, exploration and high-quality report generation in a user-friendly manner. Graphy comprises an offline Scrapper that transforms raw documents into a structured graph of Fact and Dimension nodes, and an online Surveyor that enables iterative exploration and LLM-driven report generation. We showcase a pre-scrapped graph of over 50,000 papers -- complete with their references -- demonstrating how Graphy facilitates the literature-survey scenario. The demonstration video can be found at https://youtu.be/uM4nzkAdGlM.
Taming the Expressiveness and Programmability of Graph Analytical Queries
Apr 20, 2020
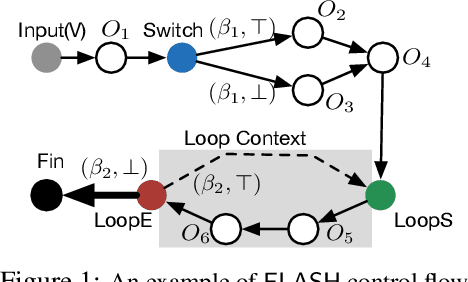
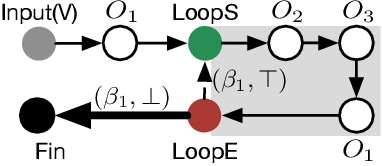
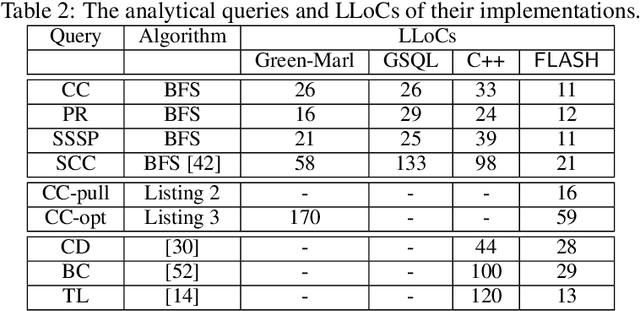
Graph database has enjoyed a boom in the last decade, and graph queries accordingly gain a lot of attentions from both the academia and industry. We focus on analytical queries in this paper. While analyzing existing domain-specific languages (DSLs) for analytical queries regarding the perspectives of completeness, expressiveness and programmability, we find out that none of existing work has achieved a satisfactory coverage of these perspectives. Motivated by this, we propose the \flash DSL, which is named after the three primitive operators Filter, LocAl and PuSH. We prove that \flash is Turing complete (completeness), and show that it achieves both good expressiveness and programmability for analytical queries. We provide an implementation of \flash based on code generation, and compare it with native C++ codes and existing DSL using representative queries. The experiment results demonstrate \flash's expressiveness, and its capability of programming complex algorithms that achieve satisfactory runtime.