 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Data Selection for LLM Reasoning
May 21, 2026Effectively training Large Language Models (LLMs) for complex, long-CoT reasoning is often bottlenecked by the need for massive high-quality reasoning data. Existing methods are either computationally expensive or fail to reliably distinguish high- from low-quality reasoning samples. To address this, we propose High-Entropy Sum (HES), a training-free metric that quantifies reasoning quality by summing only the entropy of the top (e.g., 0.5\%) highest-entropy tokens in each reasoning sample. We validate HES across three mainstream training paradigms: Supervised Fine-tuning (SFT), Rejection Fine-tuning (RFT), and Reinforcement Learning (RL), with extensive results demonstrating its consistent effectiveness and significantly reduced computational overhead. In SFT, training on the top 20\% HES-ranked data matches full-dataset performance, while using the lowest-HES data degrades it. In RFT, our HES-based training approach significantly outperforms baseline methods. In RL, HES-selected successful trajectories enable the model to learn strong reasoning patterns, significantly surpassing other compared methods. Our findings establish HES as a robust, training-free metric that enables a unified, effective, and efficient method for developing advanced reasoning in LLMs.
On Predicting the Post-training Potential of Pre-trained LLMs
May 12, 2026The performance of Large Language Models (LLMs) on downstream tasks is fundamentally constrained by the capabilities acquired during pre-training. However, traditional benchmarks like MMLU often fail to reflect a base model's plasticity in complex open-ended scenarios, leading to inefficient model selection. We address this by introducing a new task of predicting post-training potential - forecasting a base model's performance before post-training. We propose RuDE (Rubric-based Discriminative Evaluation), a unified framework that bypasses the generation gap of base models by leveraging response discrimination. Guided by our systematic 4C Taxonomy, RuDE constructs controlled contrastive pairs across diverse domains by fine-grained rubric violations. Extensive experiments demonstrate a correlation greater than 90% with post-training performance. Crucially, validation via Reinforcement Learning (RL) confirms that RuDE effectively identifies high-potential smaller models that outperform larger counterparts, offering a compute-efficient mechanism for foundation model development.
SkillGraph: Skill-Augmented Reinforcement Learning for Agents via Evolving Skill Graphs
May 12, 2026Skill libraries enable large language model agents to reuse experience from past interactions, but most existing libraries store skills as isolated entries and retrieve them only by semantic similarity. This leads to two key challenges for compositional tasks. Firstly, an agent must identify not only relevant skills but also how they depend on and build upon each other. Secondly, it also makes library maintenance difficult, since the system lacks structural cues for deciding when skills should be merged, split, or removed. We propose SKILLGRAPH, a framework that represents reusable skills as nodes in a directed graph, with typed edges encoding prerequisite, enhancement, and co-occurrence relations. Given a new task, SKILLGRAPH retrieves not just individual skills, but an ordered skill subgraph that can guide multi-step decision making. The graph is continuously updated from agent trajectories and reinforcement learning feedback, allowing both the skill library and the agent policy to improve together. Experiments on ALFWorld, WebShop, and seven search-augmented QA tasks show that SKILLGRAPH achieves state-of-the-art performance against memory-augmented RL methods, with especially large gains on complex tasks that require composing multiple skills.
SAGE: Scalable Automated Robustness Augmentation for LLM Knowledge Evaluation
May 12, 2026Large Language Models (LLMs) achieve strong performance on standard knowledge evaluation benchmarks, yet recent work shows that their knowledge capabilities remain brittle under question variants that test the same knowledge in different forms. Robustness augmentation of existing knowledge evaluation benchmarks is therefore necessary, but current LLM-assisted generate-then-verify pipelines are costly and difficult to scale due to low-yield variant generation and unreliable variant verification. We propose SAGE (Scalable Automated Generation of Robustness BEnchmarks), a framework for scalable robustness augmentation of knowledge evaluation benchmarks using fine-tuned smaller models. SAGE consists of VariantQual, a rubric-based verifier trained on human-labeled seed data, and VariantGen, a variant generator initialized with supervised fine-tuning and further optimized with reinforcement learning using VariantQual as the reward model. Experiments on HellaSwag show that SAGE constructs a large-scale robustness-augmented benchmark with quality comparable to the human-annotated HellaSwag-Pro at substantially lower cost, while the fine-tuned models further generalize to MMLU without benchmark-specific fine-tuning.
Towards Sample-Efficient and Stable Reinforcement Learning for LLM-based Recommendation
Jan 31, 2026While Long Chain-of-Thought (Long CoT) reasoning has shown promise in Large Language Models (LLMs), its adoption for enhancing recommendation quality is growing rapidly. In this work, we critically examine this trend and argue that Long CoT is inherently ill-suited for the sequential recommendation domain. We attribute this misalignment to two primary factors: excessive inference latency and the lack of explicit cognitive reasoning patterns in user behavioral data. Driven by these observations, we propose pivoting away from the CoT structure to directly leverage its underlying mechanism: Reinforcement Learning (RL), to explore the item space. However, applying RL directly faces significant obstacles, notably low sample efficiency-where most actions fail to provide learning signals-and training instability. To overcome these limitations, we propose RISER, a novel Reinforced Item Space Exploration framework for Recommendation. RISER is designed to transform non-learnable trajectories into effective pairwise preference data for optimization. Furthermore, it incorporates specific strategies to ensure stability, including the prevention of redundant rollouts and the constraint of token-level update magnitudes. Extensive experiments on three real-world datasets show that RISER significantly outperforms competitive baselines, establishing a robust paradigm for RL-enhanced LLM recommendation. Our code will be available at https://anonymous.4open.science/r/RISER/.
Teaching LLM to Reason: Reinforcement Learning from Algorithmic Problems without Code
Jul 10, 2025
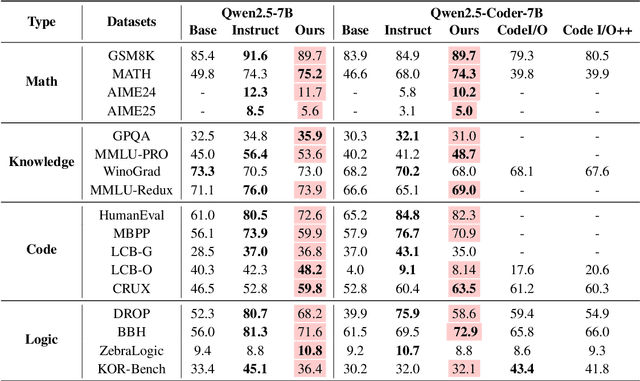

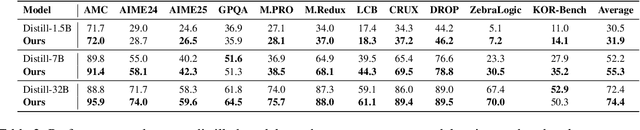
Enhancing reasoning capabilities remains a central focus in the LLM reasearch community. A promising direction involves requiring models to simulate code execution step-by-step to derive outputs for given inputs. However, as code is often designed for large-scale systems, direct application leads to over-reliance on complex data structures and algorithms, even for simple cases, resulting in overfitting to algorithmic patterns rather than core reasoning structures. To address this, we propose TeaR, which aims at teaching LLMs to reason better. TeaR leverages careful data curation and reinforcement learning to guide models in discovering optimal reasoning paths through code-related tasks, thereby improving general reasoning abilities. We conduct extensive experiments using two base models and three long-CoT distillation models, with model sizes ranging from 1.5 billion to 32 billion parameters, and across 17 benchmarks spanning Math, Knowledge, Code, and Logical Reasoning. The results consistently show significant performance improvements. Notably, TeaR achieves a 35.9% improvement on Qwen2.5-7B and 5.9% on R1-Distilled-7B.
Boosting Parameter Efficiency in LLM-Based Recommendation through Sophisticated Pruning
Jul 09, 2025LLM-based recommender systems have made significant progress; however, the deployment cost associated with the large parameter volume of LLMs still hinders their real-world applications. This work explores parameter pruning to improve parameter efficiency while maintaining recommendation quality, thereby enabling easier deployment. Unlike existing approaches that focus primarily on inter-layer redundancy, we uncover intra-layer redundancy within components such as self-attention and MLP modules. Building on this analysis, we propose a more fine-grained pruning approach that integrates both intra-layer and layer-wise pruning. Specifically, we introduce a three-stage pruning strategy that progressively prunes parameters at different levels and parts of the model, moving from intra-layer to layer-wise pruning, or from width to depth. Each stage also includes a performance restoration step using distillation techniques, helping to strike a balance between performance and parameter efficiency. Empirical results demonstrate the effectiveness of our approach: across three datasets, our models achieve an average of 88% of the original model's performance while pruning more than 95% of the non-embedding parameters. This underscores the potential of our method to significantly reduce resource requirements without greatly compromising recommendation quality. Our code will be available at: https://github.com/zheng-sl/PruneRec
CoRT: Code-integrated Reasoning within Thinking
Jun 12, 2025Large Reasoning Models (LRMs) like o1 and DeepSeek-R1 have shown remarkable progress in natural language reasoning with long chain-of-thought (CoT), yet they remain inefficient or inaccurate when handling complex mathematical operations. Addressing these limitations through computational tools (e.g., computation libraries and symbolic solvers) is promising, but it introduces a technical challenge: Code Interpreter (CI) brings external knowledge beyond the model's internal text representations, thus the direct combination is not efficient. This paper introduces CoRT, a post-training framework for teaching LRMs to leverage CI effectively and efficiently. As a first step, we address the data scarcity issue by synthesizing code-integrated reasoning data through Hint-Engineering, which strategically inserts different hints at appropriate positions to optimize LRM-CI interaction. We manually create 30 high-quality samples, upon which we post-train models ranging from 1.5B to 32B parameters, with supervised fine-tuning, rejection fine-tuning and reinforcement learning. Our experimental results demonstrate that Hint-Engineering models achieve 4\% and 8\% absolute improvements on DeepSeek-R1-Distill-Qwen-32B and DeepSeek-R1-Distill-Qwen-1.5B respectively, across five challenging mathematical reasoning datasets. Furthermore, Hint-Engineering models use about 30\% fewer tokens for the 32B model and 50\% fewer tokens for the 1.5B model compared with the natural language models. The models and code are available at https://github.com/ChengpengLi1003/CoRT.
MTR-Bench: A Comprehensive Benchmark for Multi-Turn Reasoning Evaluation
May 26, 2025Recent advances in Large Language Models (LLMs) have shown promising results in complex reasoning tasks. However, current evaluations predominantly focus on single-turn reasoning scenarios, leaving interactive tasks largely unexplored. We attribute it to the absence of comprehensive datasets and scalable automatic evaluation protocols. To fill these gaps, we present MTR-Bench for LLMs' Multi-Turn Reasoning evaluation. Comprising 4 classes, 40 tasks, and 3600 instances, MTR-Bench covers diverse reasoning capabilities, fine-grained difficulty granularity, and necessitates multi-turn interactions with the environments. Moreover, MTR-Bench features fully-automated framework spanning both dataset constructions and model evaluations, which enables scalable assessment without human interventions. Extensive experiments reveal that even the cutting-edge reasoning models fall short of multi-turn, interactive reasoning tasks. And the further analysis upon these results brings valuable insights for future research in interactive AI systems.
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.