 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaSurf: Efficient View-Aware Implicit Textured Surface Reconstruction on Mobile Devices
Nov 18, 2023



Reconstructing real-world 3D objects has numerous applications in computer vision, such as virtual reality, video games, and animations. Ideally, 3D reconstruction methods should generate high-fidelity results with 3D consistency in real-time. Traditional methods match pixels between images using photo-consistency constraints or learned features, while differentiable rendering methods like Neural Radiance Fields (NeRF) use differentiable volume rendering or surface-based representation to generate high-fidelity scenes. However, these methods require excessive runtime for rendering, making them impractical for daily applications. To address these challenges, we present $\textbf{EvaSurf}$, an $\textbf{E}$fficient $\textbf{V}$iew-$\textbf{A}$ware implicit textured $\textbf{Surf}$ace reconstruction method on mobile devices. In our method, we first employ an efficient surface-based model with a multi-view supervision module to ensure accurate mesh reconstruction. To enable high-fidelity rendering, we learn an implicit texture embedded with a set of Gaussian lobes to capture view-dependent information. Furthermore, with the explicit geometry and the implicit texture, we can employ a lightweight neural shader to reduce the expense of computation and further support real-time rendering on common mobile devices. Extensive experiments demonstrate that our method can reconstruct high-quality appearance and accurate mesh on both synthetic and real-world datasets. Moreover, our method can be trained in just 1-2 hours using a single GPU and run on mobile devices at over 40 FPS (Frames Per Second), with a final package required for rendering taking up only 40-50 MB.
Deep Group Interest Modeling of Full Lifelong User Behaviors for CTR Prediction
Nov 15, 2023



Extracting users' interests from their lifelong behavior sequence is crucial for predicting Click-Through Rate (CTR). Most current methods employ a two-stage process for efficiency: they first select historical behaviors related to the candidate item and then deduce the user's interest from this narrowed-down behavior sub-sequence. This two-stage paradigm, though effective, leads to information loss. Solely using users' lifelong click behaviors doesn't provide a complete picture of their interests, leading to suboptimal performance. In our research, we introduce the Deep Group Interest Network (DGIN), an end-to-end method to model the user's entire behavior history. This includes all post-registration actions, such as clicks, cart additions, purchases, and more, providing a nuanced user understanding. We start by grouping the full range of behaviors using a relevant key (like item_id) to enhance efficiency. This process reduces the behavior length significantly, from O(10^4) to O(10^2). To mitigate the potential loss of information due to grouping, we incorporate two categories of group attributes. Within each group, we calculate statistical information on various heterogeneous behaviors (like behavior counts) and employ self-attention mechanisms to highlight unique behavior characteristics (like behavior type). Based on this reorganized behavior data, the user's interests are derived using the Transformer technique. Additionally, we identify a subset of behaviors that share the same item_id with the candidate item from the lifelong behavior sequence. The insights from this subset reveal the user's decision-making process related to the candidate item, improving prediction accuracy. Our comprehensive evaluation, both on industrial and public datasets, validates DGIN's efficacy and efficiency.
Uni-COAL: A Unified Framework for Cross-Modality Synthesis and Super-Resolution of MR Images
Nov 14, 2023



Cross-modality synthesis (CMS), super-resolution (SR), and their combination (CMSR) have been extensively studied for magnetic resonance imaging (MRI). Their primary goals are to enhance the imaging quality by synthesizing the desired modality and reducing the slice thickness. Despite the promising synthetic results, these techniques are often tailored to specific tasks, thereby limiting their adaptability to complex clinical scenarios. Therefore, it is crucial to build a unified network that can handle various image synthesis tasks with arbitrary requirements of modality and resolution settings, so that the resources for training and deploying the models can be greatly reduced. However, none of the previous works is capable of performing CMS, SR, and CMSR using a unified network. Moreover, these MRI reconstruction methods often treat alias frequencies improperly, resulting in suboptimal detail restoration. In this paper, we propose a Unified Co-Modulated Alias-free framework (Uni-COAL) to accomplish the aforementioned tasks with a single network. The co-modulation design of the image-conditioned and stochastic attribute representations ensures the consistency between CMS and SR, while simultaneously accommodating arbitrary combinations of input/output modalities and thickness. The generator of Uni-COAL is also designed to be alias-free based on the Shannon-Nyquist signal processing framework, ensuring effective suppression of alias frequencies. Additionally, we leverage the semantic prior of Segment Anything Model (SAM) to guide Uni-COAL, ensuring a more authentic preservation of anatomical structures during synthesis. Experiments on three datasets demonstrate that Uni-COAL outperforms the alternatives in CMS, SR, and CMSR tasks for MR images, which highlights its generalizability to wide-range applications.
Resource Allocation for Near-Field Communications: Fundamentals, Tools, and Outlooks
Oct 27, 2023Extremely large-scale multiple-input-multiple output (XL-MIMO) is a promising technology to achieve high spectral efficiency (SE) and energy efficiency (EE) in future wireless systems. The larger array aperture of XL-MIMO makes communication scenarios closer to the near-field region. Therefore, near-field resource allocation is essential in realizing the above key performance indicators (KPIs). Moreover, the overall performance of XL-MIMO systems heavily depends on the channel characteristics of the selected users, eliminating interference between users through beamforming, power control, etc. The above resource allocation issue constitutes a complex joint multi-objective optimization problem since many variables and parameters must be optimized, including the spatial degree of freedom, rate, power allocation, and transmission technique. In this article, we review the basic properties of near-field communications and focus on the corresponding "resource allocation" problems. First, we identify available resources in near-field communication systems and highlight their distinctions from far-field communications. Then, we summarize optimization tools, such as numerical techniques and machine learning methods, for addressing near-field resource allocation, emphasizing their strengths and limitations. Finally, several important research directions of near-field communications are pointed out for further investigation.
Self-Supervised 3D Scene Flow Estimation and Motion Prediction using Local Rigidity Prior
Oct 17, 2023



In this article, we investigate self-supervised 3D scene flow estimation and class-agnostic motion prediction on point clouds. A realistic scene can be well modeled as a collection of rigidly moving parts, therefore its scene flow can be represented as a combination of the rigid motion of these individual parts. Building upon this observation, we propose to generate pseudo scene flow labels for self-supervised learning through piecewise rigid motion estimation, in which the source point cloud is decomposed into local regions and each region is treated as rigid. By rigidly aligning each region with its potential counterpart in the target point cloud, we obtain a region-specific rigid transformation to generate its pseudo flow labels. To mitigate the impact of potential outliers on label generation, when solving the rigid registration for each region, we alternately perform three steps: establishing point correspondences, measuring the confidence for the correspondences, and updating the rigid transformation based on the correspondences and their confidence. As a result, confident correspondences will dominate label generation and a validity mask will be derived for the generated pseudo labels. By using the pseudo labels together with their validity mask for supervision, models can be trained in a self-supervised manner. Extensive experiments on FlyingThings3D and KITTI datasets demonstrate that our method achieves new state-of-the-art performance in self-supervised scene flow learning, without any ground truth scene flow for supervision, even performing better than some supervised counterparts. Additionally, our method is further extended to class-agnostic motion prediction and significantly outperforms previous state-of-the-art self-supervised methods on nuScenes dataset.
A Tutorial on Near-Field XL-MIMO Communications Towards 6G
Oct 17, 2023



Extremely large-scale multiple-input multiple-output (XL-MIMO) is a promising technology for the sixth-generation (6G) mobile communication networks. By significantly boosting the antenna number or size to at least an order of magnitude beyond current massive MIMO systems, XL-MIMO is expected to unprecedentedly enhance the spectral efficiency and spatial resolution for wireless communication. The evolution from massive MIMO to XL-MIMO is not simply an increase in the array size, but faces new design challenges, in terms of near-field channel modelling, performance analysis, channel estimation, and practical implementation. In this article, we give a comprehensive tutorial overview on near-field XL-MIMO communications, aiming to provide useful guidance for tackling the above challenges. First, the basic near-field modelling for XL-MIMO is established, by considering the new characteristics of non-uniform spherical wave (NUSW) and spatial non-stationarity. Next, based on the near-field modelling, the performance analysis of XL-MIMO is presented, including the near-field signal-to-noise ratio (SNR) scaling laws, beam focusing pattern, achievable rate, and degrees-of-freedom (DoF). Furthermore, various XL-MIMO design issues such as near-field beam codebook, beam training, channel estimation, and delay alignment modulation (DAM) transmission are elaborated. Finally, we point out promising directions to inspire future research on near-field XL-MIMO communications.
TacticAI: an AI assistant for football tactics
Oct 17, 2023Identifying key patterns of tactics implemented by rival teams, and developing effective responses, lies at the heart of modern football. However, doing so algorithmically remains an open research challenge. To address this unmet need, we propose TacticAI, an AI football tactics assistant developed and evaluated in close collaboration with domain experts from Liverpool FC. We focus on analysing corner kicks, as they offer coaches the most direct opportunities for interventions and improvements. TacticAI incorporates both a predictive and a generative component, allowing the coaches to effectively sample and explore alternative player setups for each corner kick routine and to select those with the highest predicted likelihood of success. We validate TacticAI on a number of relevant benchmark tasks: predicting receivers and shot attempts and recommending player position adjustments. The utility of TacticAI is validated by a qualitative study conducted with football domain experts at Liverpool FC. We show that TacticAI's model suggestions are not only indistinguishable from real tactics, but also favoured over existing tactics 90% of the time, and that TacticAI offers an effective corner kick retrieval system. TacticAI achieves these results despite the limited availability of gold-standard data, achieving data efficiency through geometric deep learning.
Improving Few-shot Image Generation by Structural Discrimination and Textural Modulation
Aug 30, 2023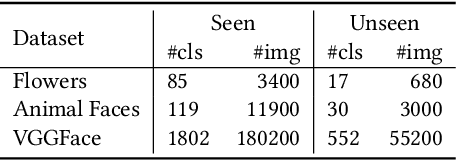
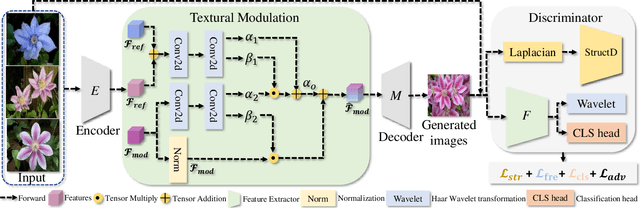
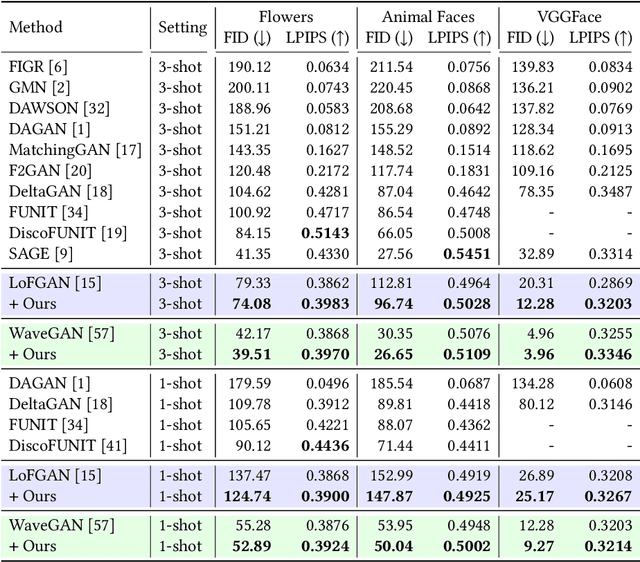

Few-shot image generation, which aims to produce plausible and diverse images for one category given a few images from this category, has drawn extensive attention. Existing approaches either globally interpolate different images or fuse local representations with pre-defined coefficients. However, such an intuitive combination of images/features only exploits the most relevant information for generation, leading to poor diversity and coarse-grained semantic fusion. To remedy this, this paper proposes a novel textural modulation (TexMod) mechanism to inject external semantic signals into internal local representations. Parameterized by the feedback from the discriminator, our TexMod enables more fined-grained semantic injection while maintaining the synthesis fidelity. Moreover, a global structural discriminator (StructD) is developed to explicitly guide the model to generate images with reasonable layout and outline. Furthermore, the frequency awareness of the model is reinforced by encouraging the model to distinguish frequency signals. Together with these techniques, we build a novel and effective model for few-shot image generation. The effectiveness of our model is identified by extensive experiments on three popular datasets and various settings. Besides achieving state-of-the-art synthesis performance on these datasets, our proposed techniques could be seamlessly integrated into existing models for a further performance boost.
Interactive segmentation in aerial images: a new benchmark and an open access web-based tool
Aug 25, 2023



In recent years, deep learning has emerged as a powerful approach in remote sensing applications, particularly in segmentation and classification techniques that play a crucial role in extracting significant land features from satellite and aerial imagery. However, only a limited number of papers have discussed the use of deep learning for interactive segmentation in land cover classification tasks. In this study, we aim to bridge the gap between interactive segmentation and remote sensing image analysis by conducting a benchmark study on various deep learning-based interactive segmentation models. We assessed the performance of five state-of-the-art interactive segmentation methods (SimpleClick, FocalClick, Iterative Click Loss (ICL), Reviving Iterative Training with Mask Guidance for Interactive Segmentation (RITM), and Segment Anything (SAM)) on two high-resolution aerial imagery datasets. To enhance the segmentation results without requiring multiple models, we introduced the Cascade-Forward Refinement (CFR) approach, an innovative inference strategy for interactive segmentation. We evaluated these interactive segmentation methods on various land cover types, object sizes, and band combinations in remote sensing. Surprisingly, the popularly discussed method, SAM, proved to be ineffective for remote sensing images. Conversely, the point-based approach used in the SimpleClick models consistently outperformed the other methods in all experiments. Building upon these findings, we developed a dedicated online tool called RSISeg for interactive segmentation of remote sensing data. RSISeg incorporates a well-performing interactive model, fine-tuned with remote sensing data. Additionally, we integrated the SAM model into this tool. Compared to existing interactive segmentation tools, RSISeg offers strong interactivity, modifiability, and adaptability to remote sensing data.
Efficient Joint Optimization of Layer-Adaptive Weight Pruning in Deep Neural Networks
Aug 24, 2023In this paper, we propose a novel layer-adaptive weight-pruning approach for Deep Neural Networks (DNNs) that addresses the challenge of optimizing the output distortion minimization while adhering to a target pruning ratio constraint. Our approach takes into account the collective influence of all layers to design a layer-adaptive pruning scheme. We discover and utilize a very important additivity property of output distortion caused by pruning weights on multiple layers. This property enables us to formulate the pruning as a combinatorial optimization problem and efficiently solve it through dynamic programming. By decomposing the problem into sub-problems, we achieve linear time complexity, making our optimization algorithm fast and feasible to run on CPUs. Our extensive experiments demonstrate the superiority of our approach over existing methods on the ImageNet and CIFAR-10 datasets. On CIFAR-10, our method achieves remarkable improvements, outperforming others by up to 1.0% for ResNet-32, 0.5% for VGG-16, and 0.7% for DenseNet-121 in terms of top-1 accuracy. On ImageNet, we achieve up to 4.7% and 4.6% higher top-1 accuracy compared to other methods for VGG-16 and ResNet-50, respectively. These results highlight the effectiveness and practicality of our approach for enhancing DNN performance through layer-adaptive weight pruning. Code will be available on https://github.com/Akimoto-Cris/RD_VIT_PRUNE.