 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Action Segmentation with Self-supervised Feature Learning and Co-occurrence Parsing
Paper and Code
Jun 02, 2021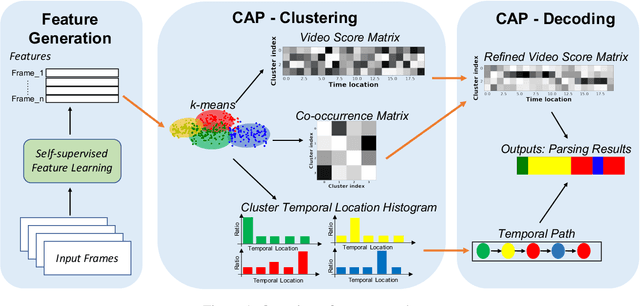
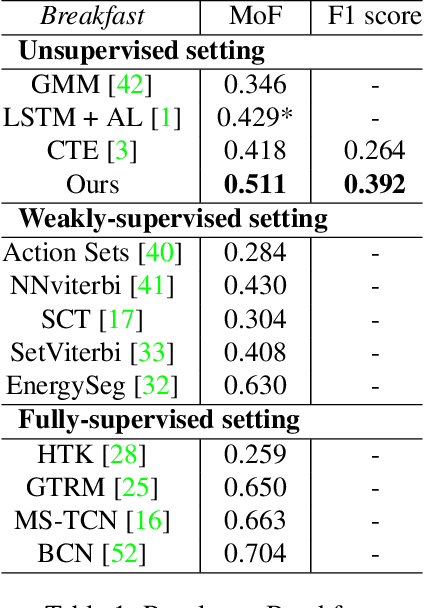
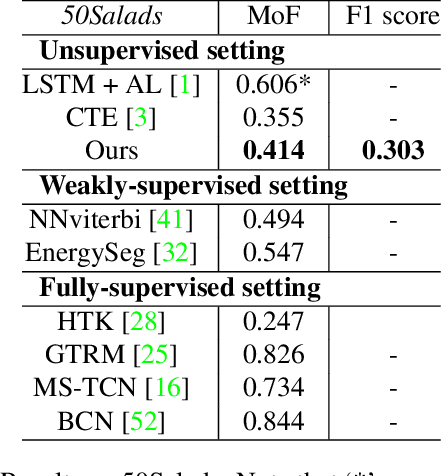
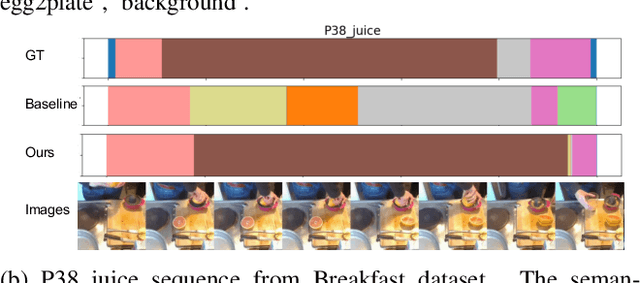
Temporal action segmentation is a task to classify each frame in the video with an action label. However, it is quite expensive to annotate every frame in a large corpus of videos to construct a comprehensive supervised training dataset. Thus in this work we explore a self-supervised method that operates on a corpus of unlabeled videos and predicts a likely set of temporal segments across the videos. To do this we leverage self-supervised video classification approaches to perform unsupervised feature extraction. On top of these features we develop CAP, a novel co-occurrence action parsing algorithm that can not only capture the correlation among sub-actions underlying the structure of activities, but also estimate the temporal trajectory of the sub-actions in an accurate and general way. We evaluate on both classic datasets (Breakfast, 50Salads) and emerging fine-grained action datasets (FineGym) with more complex activity structures and similar sub-actions. Results show that our method achieves state-of-the-art performance on all three datasets with up to 22\% improvement, and can even outperform some weakly-supervised approaches, demonstrating its effectiveness and generalizability.