 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Vertical-Domain Reasoning Capabilities of Large Language Models
Dec 27, 2025Large Language Models (LLMs) are reshaping learning paradigms, cognitive processes, and research methodologies across a wide range of domains. Integrating LLMs with professional fields and redefining the relationship between LLMs and domain-specific applications has become a critical challenge for promoting enterprise digital transformation and broader social development. To effectively integrate LLMs into the accounting domain, it is essential to understand their domain-specific reasoning capabilities. This study introduces the concept of vertical-domain accounting reasoning and establishes evaluation criteria by analyzing the training data characteristics of representative GLM-series models. These criteria provide a foundation for subsequent research on reasoning paradigms and offer benchmarks for improving accounting reasoning performance. Based on this framework, we evaluate several representative models, including GLM-6B, GLM-130B, GLM-4, and OpenAI GPT-4, on a set of accounting reasoning tasks. Experimental results show that different prompt engineering strategies lead to varying degrees of performance improvement across models, with GPT-4 achieving the strongest accounting reasoning capability. However, current LLMs still fall short of real-world application requirements. In particular, further optimization is needed for deployment in enterprise-level accounting scenarios to fully realize the potential value of LLMs in this domain.
Commercial Vehicle Braking Optimization: A Robust SIFT-Trajectory Approach
Dec 21, 2025



A vision-based trajectory analysis solution is proposed to address the "zero-speed braking" issue caused by inaccurate Controller Area Network (CAN) signals in commercial vehicle Automatic Emergency Braking (AEB) systems during low-speed operation. The algorithm utilizes the NVIDIA Jetson AGX Xavier platform to process sequential video frames from a blind spot camera, employing self-adaptive Contrast Limited Adaptive Histogram Equalization (CLAHE)-enhanced Scale-Invariant Feature Transform (SIFT) feature extraction and K-Nearest Neighbors (KNN)-Random Sample Consensus (RANSAC) matching. This allows for precise classification of the vehicle's motion state (static, vibration, moving). Key innovations include 1) multiframe trajectory displacement statistics (5-frame sliding window), 2) a dual-threshold state decision matrix, and 3) OBD-II driven dynamic Region of Interest (ROI) configuration. The system effectively suppresses environmental interference and false detection of dynamic objects, directly addressing the challenge of low-speed false activation in commercial vehicle safety systems. Evaluation in a real-world dataset (32,454 video segments from 1,852 vehicles) demonstrates an F1-score of 99.96% for static detection, 97.78% for moving state recognition, and a processing delay of 14.2 milliseconds (resolution 704x576). The deployment on-site shows an 89% reduction in false braking events, a 100% success rate in emergency braking, and a fault rate below 5%.
DeX-Portrait: Disentangled and Expressive Portrait Animation via Explicit and Latent Motion Representations
Dec 17, 2025Portrait animation from a single source image and a driving video is a long-standing problem. Recent approaches tend to adopt diffusion-based image/video generation models for realistic and expressive animation. However, none of these diffusion models realizes high-fidelity disentangled control between the head pose and facial expression, hindering applications like expression-only or pose-only editing and animation. To address this, we propose DeX-Portrait, a novel approach capable of generating expressive portrait animation driven by disentangled pose and expression signals. Specifically, we represent the pose as an explicit global transformation and the expression as an implicit latent code. First, we design a powerful motion trainer to learn both pose and expression encoders for extracting precise and decomposed driving signals. Then we propose to inject the pose transformation into the diffusion model through a dual-branch conditioning mechanism, and the expression latent through cross attention. Finally, we design a progressive hybrid classifier-free guidance for more faithful identity consistency. Experiments show that our method outperforms state-of-the-art baselines on both animation quality and disentangled controllability.
ViRC: Enhancing Visual Interleaved Mathematical CoT with Reason Chunking
Dec 17, 2025CoT has significantly enhanced the reasoning ability of LLMs while it faces challenges when extended to multimodal domains, particularly in mathematical tasks. Existing MLLMs typically perform textual reasoning solely from a single static mathematical image, overlooking dynamic visual acquisition during reasoning. In contrast, humans repeatedly examine visual image and employ step-by-step reasoning to prove intermediate propositions. This strategy of decomposing the problem-solving process into key logical nodes adheres to Miller's Law in cognitive science. Inspired by this insight, we propose a ViRC framework for multimodal mathematical tasks, introducing a Reason Chunking mechanism that structures multimodal mathematical CoT into consecutive Critical Reasoning Units (CRUs) to simulate human expert problem-solving patterns. CRUs ensure intra-unit textual coherence for intermediate proposition verification while integrating visual information across units to generate subsequent propositions and support structured reasoning. To this end, we present CRUX dataset by using three visual tools and four reasoning patterns to provide explicitly annotated CRUs across multiple reasoning paths for each mathematical problem. Leveraging the CRUX dataset, we propose a progressive training strategy inspired by human cognitive learning, which includes Instructional SFT, Practice SFT, and Strategic RL, aimed at further strengthening the Reason Chunking ability of the model. The resulting ViRC-7B model achieves a 18.8% average improvement over baselines across multiple mathematical benchmarks. Code is available at https://github.com/Leon-LihongWang/ViRC.
InfoMotion: A Graph-Based Approach to Video Dataset Distillation for Echocardiography
Dec 13, 2025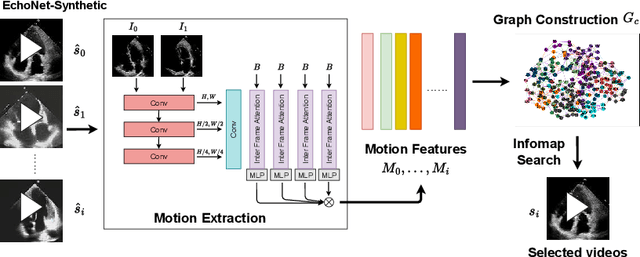
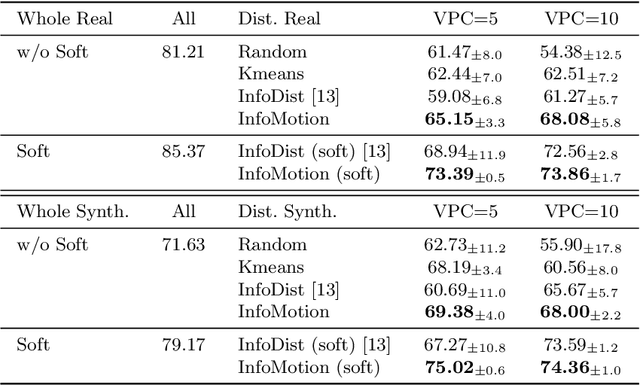
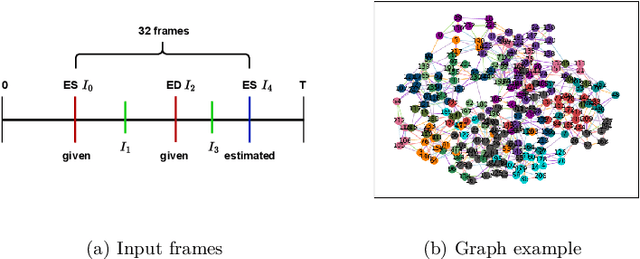
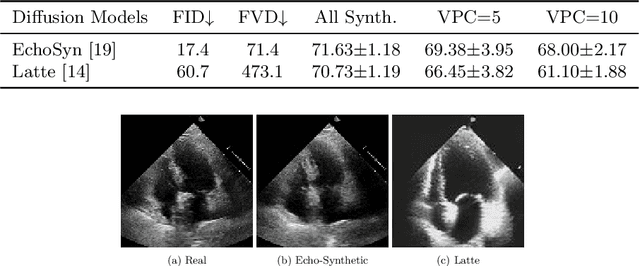
Echocardiography plays a critical role in the diagnosis and monitoring of cardiovascular diseases as a non-invasive real-time assessment of cardiac structure and function. However, the growing scale of echocardiographic video data presents significant challenges in terms of storage, computation, and model training efficiency. Dataset distillation offers a promising solution by synthesizing a compact, informative subset of data that retains the key clinical features of the original dataset. In this work, we propose a novel approach for distilling a compact synthetic echocardiographic video dataset. Our method leverages motion feature extraction to capture temporal dynamics, followed by class-wise graph construction and representative sample selection using the Infomap algorithm. This enables us to select a diverse and informative subset of synthetic videos that preserves the essential characteristics of the original dataset. We evaluate our approach on the EchoNet-Dynamic datasets and achieve a test accuracy of \(69.38\%\) using only \(25\) synthetic videos. These results demonstrate the effectiveness and scalability of our method for medical video dataset distillation.
Label-free Motion-Conditioned Diffusion Model for Cardiac Ultrasound Synthesis
Dec 10, 2025Ultrasound echocardiography is essential for the non-invasive, real-time assessment of cardiac function, but the scarcity of labelled data, driven by privacy restrictions and the complexity of expert annotation, remains a major obstacle for deep learning methods. We propose the Motion Conditioned Diffusion Model (MCDM), a label-free latent diffusion framework that synthesises realistic echocardiography videos conditioned on self-supervised motion features. To extract these features, we design the Motion and Appearance Feature Extractor (MAFE), which disentangles motion and appearance representations from videos. Feature learning is further enhanced by two auxiliary objectives: a re-identification loss guided by pseudo appearance features and an optical flow loss guided by pseudo flow fields. Evaluated on the EchoNet-Dynamic dataset, MCDM achieves competitive video generation performance, producing temporally coherent and clinically realistic sequences without reliance on manual labels. These results demonstrate the potential of self-supervised conditioning for scalable echocardiography synthesis. Our code is available at https://github.com/ZheLi2020/LabelfreeMCDM.
Lightweight Ac Arc Fault Diagnosis via Fourier Transform Inspired Multi-frequency Neural Network
Oct 30, 2025



Lightweight online detection of series arc faults is critically needed in residential and industrial power systems to prevent electrical fires. Existing diagnostic methods struggle to achieve both rapid response and robust accuracy under resource-constrained conditions. To overcome the challenge, this work suggests leveraging a multi-frequency neural network named MFNN, embedding prior physical knowledge into the network. Inspired by arcing current curve and the Fourier decomposition analysis, we create an adaptive activation function with super-expressiveness, termed EAS, and a novel network architecture with branch networks to help MFNN extract features with multiple frequencies. In our experiments, eight advanced arc fault diagnosis models across an experimental dataset with multiple sampling times and multi-level noise are used to demonstrate the superiority of MFNN. The corresponding experiments show: 1) The MFNN outperforms other models in arc fault location, befitting from signal decomposition of branch networks. 2) The noise immunity of MFNN is much better than that of other models, achieving 14.51% over LCNN and 16.3% over BLS in test accuracy when SNR=-9. 3) EAS and the network architecture contribute to the excellent performance of MFNN.
Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
OmniMotion: Multimodal Motion Generation with Continuous Masked Autoregression
Oct 16, 2025


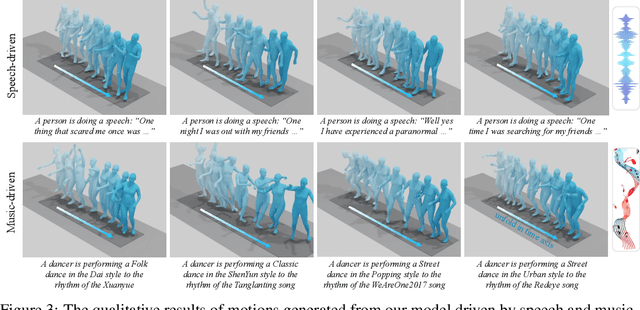
Whole-body multi-modal human motion generation poses two primary challenges: creating an effective motion generation mechanism and integrating various modalities, such as text, speech, and music, into a cohesive framework. Unlike previous methods that usually employ discrete masked modeling or autoregressive modeling, we develop a continuous masked autoregressive motion transformer, where a causal attention is performed considering the sequential nature within the human motion. Within this transformer, we introduce a gated linear attention and an RMSNorm module, which drive the transformer to pay attention to the key actions and suppress the instability caused by either the abnormal movements or the heterogeneous distributions within multi-modalities. To further enhance both the motion generation and the multimodal generalization, we employ the DiT structure to diffuse the conditions from the transformer towards the targets. To fuse different modalities, AdaLN and cross-attention are leveraged to inject the text, speech, and music signals. Experimental results demonstrate that our framework outperforms previous methods across all modalities, including text-to-motion, speech-to-gesture, and music-to-dance. The code of our method will be made public.
From Language to Locomotion: Retargeting-free Humanoid Control via Motion Latent Guidance
Oct 16, 2025Natural language offers a natural interface for humanoid robots, but existing language-guided humanoid locomotion pipelines remain cumbersome and unreliable. They typically decode human motion, retarget it to robot morphology, and then track it with a physics-based controller. However, this multi-stage process is prone to cumulative errors, introduces high latency, and yields weak coupling between semantics and control. These limitations call for a more direct pathway from language to action, one that eliminates fragile intermediate stages. Therefore, we present RoboGhost, a retargeting-free framework that directly conditions humanoid policies on language-grounded motion latents. By bypassing explicit motion decoding and retargeting, RoboGhost enables a diffusion-based policy to denoise executable actions directly from noise, preserving semantic intent and supporting fast, reactive control. A hybrid causal transformer-diffusion motion generator further ensures long-horizon consistency while maintaining stability and diversity, yielding rich latent representations for precise humanoid behavior. Extensive experiments demonstrate that RoboGhost substantially reduces deployment latency, improves success rates and tracking accuracy, and produces smooth, semantically aligned locomotion on real humanoids. Beyond text, the framework naturally extends to other modalities such as images, audio, and music, providing a general foundation for vision-language-action humanoid systems.