 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHT-Bench: Benchmarking and Learning Dexterous Full-Hand Tactile Representations with Egocentric Vision
Jun 17, 2026Establishing a universal benchmark for tactile representation learning in robotic manipulation remains challenging due to the diversity of tactile sensor designs, data formats, and robot embodiments. Rather than seeking to establish such, we explore a scalable and promising direction for future development: egocentric vision paired with full-hand tactile data. To this end, we introduce \textbf{HT-Bench}, a large-scale multi-task benchmark for dexterous full-hand tactile sensing, comprising 10M RGB frames and 7.8M tactile frames collected across 226 tasks. HT-Bench evaluates tactile representations from three key perspectives: whether they encode meaningful contact geometry, whether they can align tactile observations with visual information, and whether they generalize to unseen tasks. To assess these capabilities, HT-Bench includes four tasks: fine-grained tactile similarity retrieval, masked tactile inpainting, vision-to-tactile synthesis, and multimodal tactile frame prediction. We further propose \textbf{HandTouch}, a vector-quantized vision--tactile encoder that learns tactile representations through progressive spatial, cross-modal, and temporal training. Across HT-Bench, HandTouch consistently outperforms representative tactile encoder baselines, improving Recall@5 on fine-grained tactile similarity retrieval from 74.65\% to 85.23\%, reducing RMSE on masked tactile inpainting from 0.022 to 0.010, and increasing OOD cIoU on vision-to-tactile synthesis from 0.628 to 0.705. These results demonstrate the effectiveness of HandTouch and suggest that large-scale egocentric full-hand tactile data provides a scalable basis for evaluating and advancing tactile representation learning in dexterous manipulation.
MusaCoder: Native GPU Kernel Generation with Full-Stack Training on Moore Threads GPU
Jun 03, 2026Native GPU kernel generation turns high-level tensor programs into executable, efficient low-level code. Existing Large Language Models (LLMs) struggle with this task, while execution-based reinforcement learning suffers from sparse rewards, reward hacking, and training instability. We present MusaCoder, a full-stack training framework for native GPU kernel generation on CUDA and MUSA backends. MusaCoder combines progressive kernel-oriented data synthesis, diversity-preserving rejection fine-tuning, and execution-feedback Reinforcement Learning (RL) through MooreEval, a distributed verifier and reward environment. To stabilize RL, MusaCoder introduces PrimeEcho for first-turn-anchored multi-turn rewards, Buffered Dynamic Retry for recovering signals from all-failed hard samples, and MirrorPop for off-policy sequence filtering. Experiments on KernelBench and a MUSA-ported variant show that MusaCoder outperforms strong open-source and proprietary baselines in both correctness and empirical speedup, with the 9B model matching or exceeding frontier closed-source models and the 27B model establishing a new state of the art. These results demonstrate not only the effectiveness of full-stack execution-feedback training for native kernel generation, but also the capability of Moore Threads GPUs to support the complete LLM post-training stack, providing a practical foundation for large-model training and optimization on emerging accelerators.
Agent-as-Peer-Debriefer: A Multi-Agent Framework with Perspective-Based Refinement for Qualitative Analysis
May 23, 2026Large language models (LLMs) are increasingly used for qualitative data analysis (QDA), yet their outputs often miss the depth and nuance of human analysis. We argue this gap reflects a missing credibility practice from human QDA: peer debriefing, in which an analyst seeks feedback from a disinterested peer and uses it to refine their coding. To bring this practice into LLM-assisted QDA, we propose Agent-as-Peer-Debriefer, a multi-agent QDA framework that builds peer debriefing into key coding steps. In our framework, a Hierarchical Coding Agent follows the standard QDA process to generate codes, sub-themes, and themes, along with self-explanations and reflection memos. It then shares these outputs with three Peer-Debriefing Agents, each applying a distinct analytical perspective (Theory-Driven, Data-Driven, or Applied) and refining the codes by keeping, renaming, reassigning, merging, or splitting them. These perspectives are drawn from established human QDA practices that generalize across domains and datasets. To evaluate the framework, we test it on three datasets across two domains with three LLMs, measuring semantic similarity to human-annotated codes. Across all settings, perspective-based, peer-debriefing refinement aligns more closely with human codes than a single-LLM baseline, and an ablation further shows the gain is not merely from additional refinement. The three perspectives also produce distinct trade-offs, showing that the choice of perspective is a meaningful and controllable design decision. More broadly, these findings suggest that simulating peer debriefing with explicit perspectives is a promising route to more credible LLM-assisted QDA.
Commercial Vehicle Braking Optimization: A Robust SIFT-Trajectory Approach
Dec 21, 2025



A vision-based trajectory analysis solution is proposed to address the "zero-speed braking" issue caused by inaccurate Controller Area Network (CAN) signals in commercial vehicle Automatic Emergency Braking (AEB) systems during low-speed operation. The algorithm utilizes the NVIDIA Jetson AGX Xavier platform to process sequential video frames from a blind spot camera, employing self-adaptive Contrast Limited Adaptive Histogram Equalization (CLAHE)-enhanced Scale-Invariant Feature Transform (SIFT) feature extraction and K-Nearest Neighbors (KNN)-Random Sample Consensus (RANSAC) matching. This allows for precise classification of the vehicle's motion state (static, vibration, moving). Key innovations include 1) multiframe trajectory displacement statistics (5-frame sliding window), 2) a dual-threshold state decision matrix, and 3) OBD-II driven dynamic Region of Interest (ROI) configuration. The system effectively suppresses environmental interference and false detection of dynamic objects, directly addressing the challenge of low-speed false activation in commercial vehicle safety systems. Evaluation in a real-world dataset (32,454 video segments from 1,852 vehicles) demonstrates an F1-score of 99.96% for static detection, 97.78% for moving state recognition, and a processing delay of 14.2 milliseconds (resolution 704x576). The deployment on-site shows an 89% reduction in false braking events, a 100% success rate in emergency braking, and a fault rate below 5%.
Round Attention: A Novel Round-Level Attention Mechanism to Accelerate LLM Inference
Feb 21, 2025



The increasing context window size in large language models (LLMs) has improved their ability to handle complex, long-text tasks. However, as the conversation rounds continue, it is required to store a large amount of KV cache in GPU memory, which significantly affects the efficiency and even availability of the model serving systems. This paper analyzes dialogue data from real users and discovers that the LLM inference manifests a watershed layer, after which the distribution of round-level attention shows notable similarity. We propose Round Attention, a novel round-level attention mechanism that only recalls and computes the KV cache of the most relevant rounds. The experiments show that our method saves 55\% memory usage without compromising model performance.
Effective Diffusion Transformer Architecture for Image Super-Resolution
Sep 29, 2024



Recent advances indicate that diffusion models hold great promise in image super-resolution. While the latest methods are primarily based on latent diffusion models with convolutional neural networks, there are few attempts to explore transformers, which have demonstrated remarkable performance in image generation. In this work, we design an effective diffusion transformer for image super-resolution (DiT-SR) that achieves the visual quality of prior-based methods, but through a training-from-scratch manner. In practice, DiT-SR leverages an overall U-shaped architecture, and adopts a uniform isotropic design for all the transformer blocks across different stages. The former facilitates multi-scale hierarchical feature extraction, while the latter reallocates the computational resources to critical layers to further enhance performance. Moreover, we thoroughly analyze the limitation of the widely used AdaLN, and present a frequency-adaptive time-step conditioning module, enhancing the model's capacity to process distinct frequency information at different time steps. Extensive experiments demonstrate that DiT-SR outperforms the existing training-from-scratch diffusion-based SR methods significantly, and even beats some of the prior-based methods on pretrained Stable Diffusion, proving the superiority of diffusion transformer in image super-resolution.
One Step Diffusion-based Super-Resolution with Time-Aware Distillation
Aug 14, 2024Diffusion-based image super-resolution (SR) methods have shown promise in reconstructing high-resolution images with fine details from low-resolution counterparts. However, these approaches typically require tens or even hundreds of iterative samplings, resulting in significant latency. Recently, techniques have been devised to enhance the sampling efficiency of diffusion-based SR models via knowledge distillation. Nonetheless, when aligning the knowledge of student and teacher models, these solutions either solely rely on pixel-level loss constraints or neglect the fact that diffusion models prioritize varying levels of information at different time steps. To accomplish effective and efficient image super-resolution, we propose a time-aware diffusion distillation method, named TAD-SR. Specifically, we introduce a novel score distillation strategy to align the data distribution between the outputs of the student and teacher models after minor noise perturbation. This distillation strategy enables the student network to concentrate more on the high-frequency details. Furthermore, to mitigate performance limitations stemming from distillation, we integrate a latent adversarial loss and devise a time-aware discriminator that leverages diffusion priors to effectively distinguish between real images and generated images. Extensive experiments conducted on synthetic and real-world datasets demonstrate that the proposed method achieves comparable or even superior performance compared to both previous state-of-the-art (SOTA) methods and the teacher model in just one sampling step. Codes are available at https://github.com/LearningHx/TAD-SR.
Bridging Generative and Discriminative Models for Unified Visual Perception with Diffusion Priors
Jan 29, 2024



The remarkable prowess of diffusion models in image generation has spurred efforts to extend their application beyond generative tasks. However, a persistent challenge exists in lacking a unified approach to apply diffusion models to visual perception tasks with diverse semantic granularity requirements. Our purpose is to establish a unified visual perception framework, capitalizing on the potential synergies between generative and discriminative models. In this paper, we propose Vermouth, a simple yet effective framework comprising a pre-trained Stable Diffusion (SD) model containing rich generative priors, a unified head (U-head) capable of integrating hierarchical representations, and an adapted expert providing discriminative priors. Comprehensive investigations unveil potential characteristics of Vermouth, such as varying granularity of perception concealed in latent variables at distinct time steps and various U-net stages. We emphasize that there is no necessity for incorporating a heavyweight or intricate decoder to transform diffusion models into potent representation learners. Extensive comparative evaluations against tailored discriminative models showcase the efficacy of our approach on zero-shot sketch-based image retrieval (ZS-SBIR), few-shot classification, and open-vocabulary semantic segmentation tasks. The promising results demonstrate the potential of diffusion models as formidable learners, establishing their significance in furnishing informative and robust visual representations.
VideoReTalking: Audio-based Lip Synchronization for Talking Head Video Editing In the Wild
Nov 27, 2022We present VideoReTalking, a new system to edit the faces of a real-world talking head video according to input audio, producing a high-quality and lip-syncing output video even with a different emotion. Our system disentangles this objective into three sequential tasks: (1) face video generation with a canonical expression; (2) audio-driven lip-sync; and (3) face enhancement for improving photo-realism. Given a talking-head video, we first modify the expression of each frame according to the same expression template using the expression editing network, resulting in a video with the canonical expression. This video, together with the given audio, is then fed into the lip-sync network to generate a lip-syncing video. Finally, we improve the photo-realism of the synthesized faces through an identity-aware face enhancement network and post-processing. We use learning-based approaches for all three steps and all our modules can be tackled in a sequential pipeline without any user intervention. Furthermore, our system is a generic approach that does not need to be retrained to a specific person. Evaluations on two widely-used datasets and in-the-wild examples demonstrate the superiority of our framework over other state-of-the-art methods in terms of lip-sync accuracy and visual quality.
Multi-Frame Content Integration with a Spatio-Temporal Attention Mechanism for Person Video Motion Transfer
Aug 12, 2019
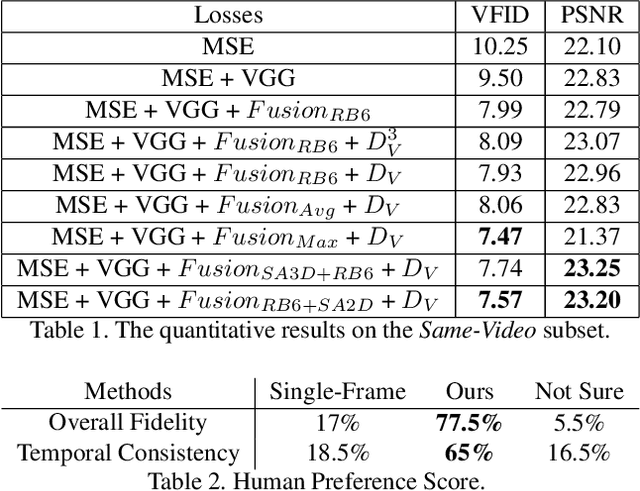
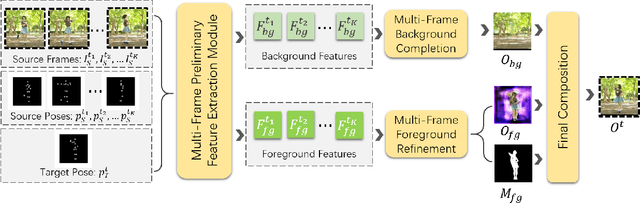
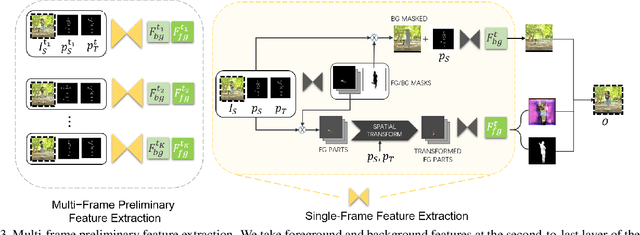
Existing person video generation methods either lack the flexibility in controlling both the appearance and motion, or fail to preserve detailed appearance and temporal consistency. In this paper, we tackle the problem of motion transfer for generating person videos, which provides controls on both the appearance and the motion. Specifically, we transfer the motion of one person in a target video to another person in a source video, while preserving the appearance of the source person. Besides only relying on one source frame as the existing state-of-the-art methods, our proposed method integrates information from multiple source frames based on a spatio-temporal attention mechanism to preserve rich appearance details. In addition to a spatial discriminator employed for encouraging the frame-level fidelity, a multi-range temporal discriminator is adopted to enforce the generated video to resemble temporal dynamics of a real video in various time ranges. A challenging real-world dataset, which contains about 500 dancing video clips with complex and unpredictable motions, is collected for the training and testing. Extensive experiments show that the proposed method can produce more photo-realistic and temporally consistent person videos than previous methods. As our method decomposes the syntheses of the foreground and background into two branches, a flexible background substitution application can also be achieved.