 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCALE: Self-Correcting Visual Navigation for Mobile Robots via Anti-Novelty Estimation
Apr 16, 2024Although visual navigation has been extensively studied using deep reinforcement learning, online learning for real-world robots remains a challenging task. Recent work directly learned from offline dataset to achieve broader generalization in the real-world tasks, which, however, faces the out-of-distribution (OOD) issue and potential robot localization failures in a given map for unseen observation. This significantly drops the success rates and even induces collision. In this paper, we present a self-correcting visual navigation method, SCALE, that can autonomously prevent the robot from the OOD situations without human intervention. Specifically, we develop an image-goal conditioned offline reinforcement learning method based on implicit Q-learning (IQL). When facing OOD observation, our novel localization recovery method generates the potential future trajectories by learning from the navigation affordance, and estimates the future novelty via random network distillation (RND). A tailored cost function searches for the candidates with the least novelty that can lead the robot to the familiar places. We collect offline data and conduct evaluation experiments in three real-world urban scenarios. Experiment results show that SCALE outperforms the previous state-of-the-art methods for open-world navigation with a unique capability of localization recovery, significantly reducing the need for human intervention. Code is available at https://github.com/KubeEdge4Robotics/ScaleNav.
Articulated Object Manipulation with Coarse-to-fine Affordance for Mitigating the Effect of Point Cloud Noise
Mar 07, 2024



3D articulated objects are inherently challenging for manipulation due to the varied geometries and intricate functionalities associated with articulated objects.Point-level affordance, which predicts the per-point actionable score and thus proposes the best point to interact with, has demonstrated excellent performance and generalization capabilities in articulated object manipulation. However, a significant challenge remains: while previous works use perfect point cloud generated in simulation, the models cannot directly apply to the noisy point cloud in the real-world. To tackle this challenge, we leverage the property of real-world scanned point cloud that, the point cloud becomes less noisy when the camera is closer to the object. Therefore, we propose a novel coarse-to-fine affordance learning pipeline to mitigate the effect of point cloud noise in two stages. In the first stage, we learn the affordance on the noisy far point cloud which includes the whole object to propose the approximated place to manipulate. Then, we move the camera in front of the approximated place, scan a less noisy point cloud containing precise local geometries for manipulation, and learn affordance on such point cloud to propose fine-grained final actions. The proposed method is thoroughly evaluated both using large-scale simulated noisy point clouds mimicking real-world scans, and in the real world scenarios, with superiority over existing methods, demonstrating the effectiveness in tackling the noisy real-world point cloud problem.
VOLTA: Diverse and Controllable Question-Answer Pair Generation with Variational Mutual Information Maximizing Autoencoder
Jul 03, 2023



Previous question-answer pair generation methods aimed to produce fluent and meaningful question-answer pairs but tend to have poor diversity. Recent attempts addressing this issue suffer from either low model capacity or overcomplicated architecture. Furthermore, they overlooked the problem where the controllability of their models is highly dependent on the input. In this paper, we propose a model named VOLTA that enhances generative diversity by leveraging the Variational Autoencoder framework with a shared backbone network as its encoder and decoder. In addition, we propose adding InfoGAN-style latent codes to enable input-independent controllability over the generation process. We perform comprehensive experiments and the results show that our approach can significantly improve diversity and controllability over state-of-the-art models.
Learnable Behavior Control: Breaking Atari Human World Records via Sample-Efficient Behavior Selection
May 09, 2023



The exploration problem is one of the main challenges in deep reinforcement learning (RL). Recent promising works tried to handle the problem with population-based methods, which collect samples with diverse behaviors derived from a population of different exploratory policies. Adaptive policy selection has been adopted for behavior control. However, the behavior selection space is largely limited by the predefined policy population, which further limits behavior diversity. In this paper, we propose a general framework called Learnable Behavioral Control (LBC) to address the limitation, which a) enables a significantly enlarged behavior selection space via formulating a hybrid behavior mapping from all policies; b) constructs a unified learnable process for behavior selection. We introduce LBC into distributed off-policy actor-critic methods and achieve behavior control via optimizing the selection of the behavior mappings with bandit-based meta-controllers. Our agents have achieved 10077.52% mean human normalized score and surpassed 24 human world records within 1B training frames in the Arcade Learning Environment, which demonstrates our significant state-of-the-art (SOTA) performance without degrading the sample efficiency.
Planning Immediate Landmarks of Targets for Model-Free Skill Transfer across Agents
Dec 18, 2022In reinforcement learning applications like robotics, agents usually need to deal with various input/output features when specified with different state/action spaces by their developers or physical restrictions. This indicates unnecessary re-training from scratch and considerable sample inefficiency, especially when agents follow similar solution steps to achieve tasks. In this paper, we aim to transfer similar high-level goal-transition knowledge to alleviate the challenge. Specifically, we propose PILoT, i.e., Planning Immediate Landmarks of Targets. PILoT utilizes the universal decoupled policy optimization to learn a goal-conditioned state planner; then, distills a goal-planner to plan immediate landmarks in a model-free style that can be shared among different agents. In our experiments, we show the power of PILoT on various transferring challenges, including few-shot transferring across action spaces and dynamics, from low-dimensional vector states to image inputs, from simple robot to complicated morphology; and we also illustrate a zero-shot transfer solution from a simple 2D navigation task to the harder Ant-Maze task.
Prototypical context-aware dynamics generalization for high-dimensional model-based reinforcement learning
Nov 23, 2022The latent world model provides a promising way to learn policies in a compact latent space for tasks with high-dimensional observations, however, its generalization across diverse environments with unseen dynamics remains challenging. Although the recurrent structure utilized in current advances helps to capture local dynamics, modeling only state transitions without an explicit understanding of environmental context limits the generalization ability of the dynamics model. To address this issue, we propose a Prototypical Context-Aware Dynamics (ProtoCAD) model, which captures the local dynamics by time consistent latent context and enables dynamics generalization in high-dimensional control tasks. ProtoCAD extracts useful contextual information with the help of the prototypes clustered over batch and benefits model-based RL in two folds: 1) It utilizes a temporally consistent prototypical regularizer that encourages the prototype assignments produced for different time parts of the same latent trajectory to be temporally consistent instead of comparing the features; 2) A context representation is designed which combines both the projection embedding of latent states and aggregated prototypes and can significantly improve the dynamics generalization ability. Extensive experiments show that ProtoCAD surpasses existing methods in terms of dynamics generalization. Compared with the recurrent-based model RSSM, ProtoCAD delivers 13.2% and 26.7% better mean and median performance across all dynamics generalization tasks.
NeurIPS 2022 Competition: Driving SMARTS
Nov 14, 2022

Driving SMARTS is a regular competition designed to tackle problems caused by the distribution shift in dynamic interaction contexts that are prevalent in real-world autonomous driving (AD). The proposed competition supports methodologically diverse solutions, such as reinforcement learning (RL) and offline learning methods, trained on a combination of naturalistic AD data and open-source simulation platform SMARTS. The two-track structure allows focusing on different aspects of the distribution shift. Track 1 is open to any method and will give ML researchers with different backgrounds an opportunity to solve a real-world autonomous driving challenge. Track 2 is designed for strictly offline learning methods. Therefore, direct comparisons can be made between different methods with the aim to identify new promising research directions. The proposed setup consists of 1) realistic traffic generated using real-world data and micro simulators to ensure fidelity of the scenarios, 2) framework accommodating diverse methods for solving the problem, and 3) baseline method. As such it provides a unique opportunity for the principled investigation into various aspects of autonomous vehicle deployment.
RITA: Boost Autonomous Driving Simulators with Realistic Interactive Traffic Flow
Nov 11, 2022



High-quality traffic flow generation is the core module in building simulators for autonomous driving. However, the majority of available simulators are incapable of replicating traffic patterns that accurately reflect the various features of real-world data while also simulating human-like reactive responses to the tested autopilot driving strategies. Taking one step forward to addressing such a problem, we propose Realistic Interactive TrAffic flow (RITA) as an integrated component of existing driving simulators to provide high-quality traffic flow for the evaluation and optimization of the tested driving strategies. RITA is developed with fidelity, diversity, and controllability in consideration, and consists of two core modules called RITABackend and RITAKit. RITABackend is built to support vehicle-wise control and provide traffic generation models from real-world datasets, while RITAKit is developed with easy-to-use interfaces for controllable traffic generation via RITABackend. We demonstrate RITA's capacity to create diversified and high-fidelity traffic simulations in several highly interactive highway scenarios. The experimental findings demonstrate that our produced RITA traffic flows meet all three design goals, hence enhancing the completeness of driving strategy evaluation. Moreover, we showcase the possibility for further improvement of baseline strategies through online fine-tuning with RITA traffic flows.
Decomposed Mutual Information Optimization for Generalized Context in Meta-Reinforcement Learning
Oct 09, 2022
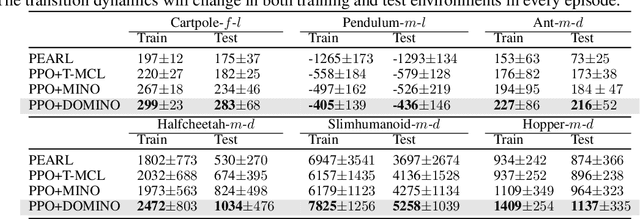
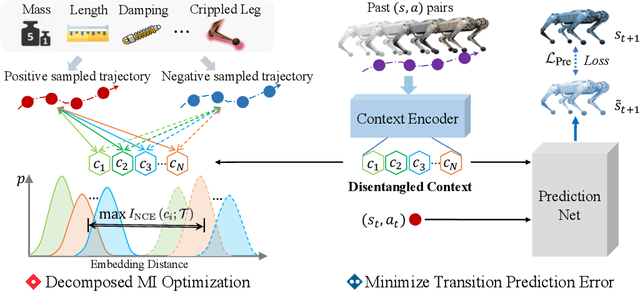
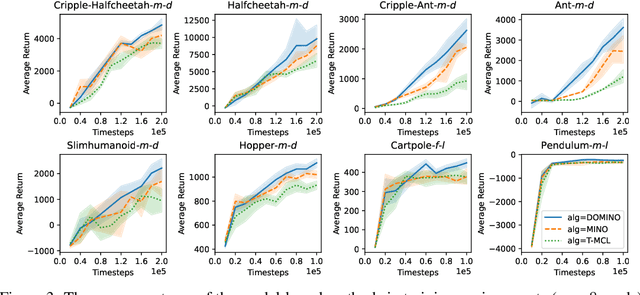
Adapting to the changes in transition dynamics is essential in robotic applications. By learning a conditional policy with a compact context, context-aware meta-reinforcement learning provides a flexible way to adjust behavior according to dynamics changes. However, in real-world applications, the agent may encounter complex dynamics changes. Multiple confounders can influence the transition dynamics, making it challenging to infer accurate context for decision-making. This paper addresses such a challenge by Decomposed Mutual INformation Optimization (DOMINO) for context learning, which explicitly learns a disentangled context to maximize the mutual information between the context and historical trajectories, while minimizing the state transition prediction error. Our theoretical analysis shows that DOMINO can overcome the underestimation of the mutual information caused by multi-confounded challenges via learning disentangled context and reduce the demand for the number of samples collected in various environments. Extensive experiments show that the context learned by DOMINO benefits both model-based and model-free reinforcement learning algorithms for dynamics generalization in terms of sample efficiency and performance in unseen environments.
Plan Your Target and Learn Your Skills: Transferable State-Only Imitation Learning via Decoupled Policy Optimization
Mar 04, 2022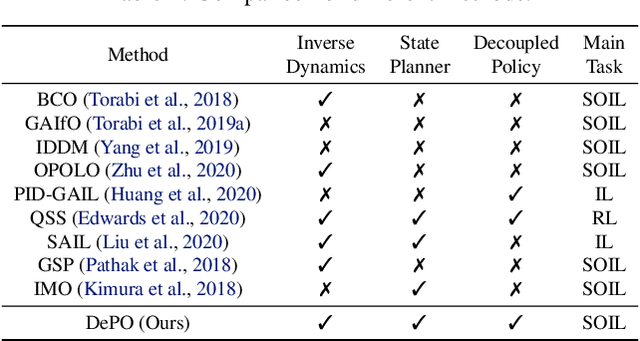
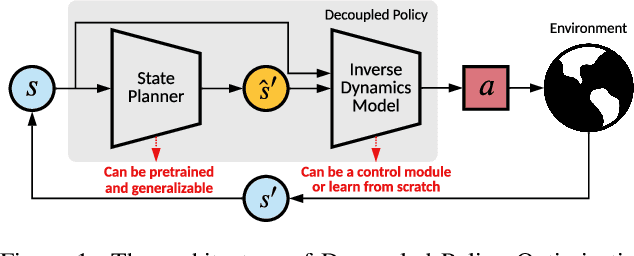
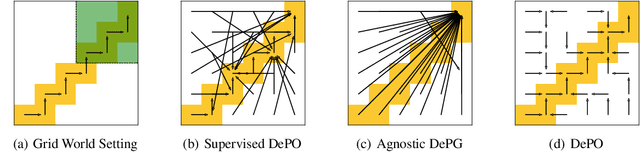
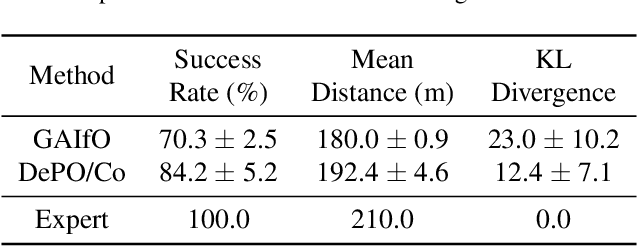
Recent progress in state-only imitation learning extends the scope of applicability of imitation learning to real-world settings by relieving the need for observing expert actions. However, existing solutions only learn to extract a state-to-action mapping policy from the data, without considering how the expert plans to the target. This hinders the ability to leverage demonstrations and limits the flexibility of the policy. In this paper, we introduce Decoupled Policy Optimization (DePO), which explicitly decouples the policy as a high-level state planner and an inverse dynamics model. With embedded decoupled policy gradient and generative adversarial training, DePO enables knowledge transfer to different action spaces or state transition dynamics, and can generalize the planner to out-of-demonstration state regions. Our in-depth experimental analysis shows the effectiveness of DePO on learning a generalized target state planner while achieving the best imitation performance. We demonstrate the appealing usage of DePO for transferring across different tasks by pre-training, and the potential for co-training agents with various skills.