 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
May 07, 2025



Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference.
RITA: Boost Autonomous Driving Simulators with Realistic Interactive Traffic Flow
Nov 11, 2022



High-quality traffic flow generation is the core module in building simulators for autonomous driving. However, the majority of available simulators are incapable of replicating traffic patterns that accurately reflect the various features of real-world data while also simulating human-like reactive responses to the tested autopilot driving strategies. Taking one step forward to addressing such a problem, we propose Realistic Interactive TrAffic flow (RITA) as an integrated component of existing driving simulators to provide high-quality traffic flow for the evaluation and optimization of the tested driving strategies. RITA is developed with fidelity, diversity, and controllability in consideration, and consists of two core modules called RITABackend and RITAKit. RITABackend is built to support vehicle-wise control and provide traffic generation models from real-world datasets, while RITAKit is developed with easy-to-use interfaces for controllable traffic generation via RITABackend. We demonstrate RITA's capacity to create diversified and high-fidelity traffic simulations in several highly interactive highway scenarios. The experimental findings demonstrate that our produced RITA traffic flows meet all three design goals, hence enhancing the completeness of driving strategy evaluation. Moreover, we showcase the possibility for further improvement of baseline strategies through online fine-tuning with RITA traffic flows.
Reinforcement Learning based Negotiation-aware Motion Planning of Autonomous Vehicles
Jul 08, 2021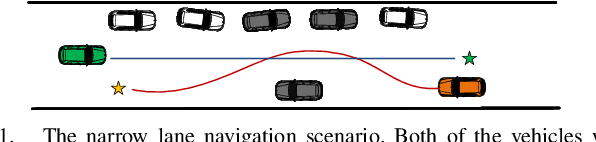
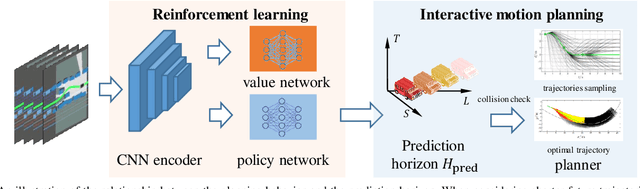
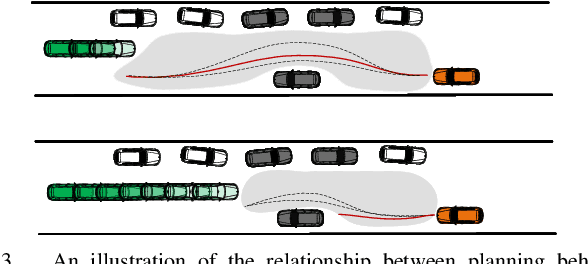
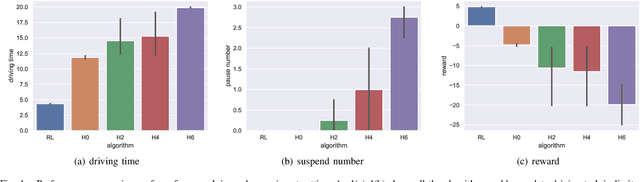
For autonomous vehicles integrating onto roadways with human traffic participants, it requires understanding and adapting to the participants' intention and driving styles by responding in predictable ways without explicit communication. This paper proposes a reinforcement learning based negotiation-aware motion planning framework, which adopts RL to adjust the driving style of the planner by dynamically modifying the prediction horizon length of the motion planner in real time adaptively w.r.t the event of a change in environment, typically triggered by traffic participants' switch of intents with different driving styles. The framework models the interaction between the autonomous vehicle and other traffic participants as a Markov Decision Process. A temporal sequence of occupancy grid maps are taken as inputs for RL module to embed an implicit intention reasoning. Curriculum learning is employed to enhance the training efficiency and the robustness of the algorithm. We applied our method to narrow lane navigation in both simulation and real world to demonstrate that the proposed method outperforms the common alternative due to its advantage in alleviating the social dilemma problem with proper negotiation skills.