 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Shrinkage Bias in LLM FP4 Pretraining: Geometric Origin, Systemic Impact, and UFP4 Recipe
Jun 18, 2026FP4 training promises substantial reductions in memory and computation cost for LLM pretraining, yet current FP4 hardware paths and recipes, including NVIDIA Blackwell/Rubin-class systems and AMD MI350-series GPUs, remain centered on E2M1 data elements. In this study, we identify a fundamental limitation of that choice: non-uniform formats such as E2M1 inherently suffer from Shrinkage Bias, a systematic negative rounding error caused by the geometric asymmetry of their representable bins. We show that this bias accumulates multiplicatively across layers and is amplified by the Random Hadamard Transform (RHT), providing a unified explanation for the training instability observed in existing E2M1-based FP4 recipes. In contrast, uniform grids (E1M2/INT4) bypass this grid-geometry error and better convert the improved bucket utilization from RHT into higher quantization quality. Based on this finding, we propose UFP4, a uniform 4-bit training recipe that applies RHT to all three training GEMMs while restricting stochastic rounding to dY alone. On Dense 1.5B, MoE 7.9B, and MoE 124B long-run pretraining, UFP4 consistently achieves lower BF16-relative loss degradation than strong E2M1-based baselines, supported by scaling-law analysis and ablation studies. Our results suggest that future accelerators should support E1M2/INT4-style uniform 4-bit grids as first-class training primitives alongside E2M1.
Ling and Ring 2.6 Technical Report: Efficient and Instant Agentic Intelligence at Trillion-Parameter Scale
Jun 13, 2026Efficient and scalable agentic intelligence requires models that can deliver both low-latency responses and strong reasoning capabilities while remaining practical to train, serve, and deploy. In this report, we present Ling-2.6 and Ring-2.6, a family of models designed to address this challenge at scale. Ling-2.6 is optimized for instant response generation and high capability per output token, whereas Ring-2.6 is tailored for deeper reasoning and more advanced agentic workflows. Instead of training from scratch, we upgrade the Ling-2.0 base model through architectural migration pre-training and large-scale post-training. This upgrade is guided by a unified co-design of model architecture, optimization objectives, serving systems, and agent training environments, enabling improvements in both model capability and deployment efficiency. At the architectural level, we introduce a hybrid linear attention design that integrates Lightning Attention with MLA, improving the efficiency of long-context training and decoding. To further enhance token efficiency, we optimize capability per output token through Evolutionary Chain-of-Thought, Linguistic Unit Policy Optimization, bidirectional preference alignment, and shortest-correct-response distillation. For agentic capabilities, we propose KPop, a reinforcement learning framework designed to support stable training of Ring-2.6-1T on large-scale environment-grounded data. KPop improves training efficiency through asynchronous scheduling across coding, search, tool use, and workflow execution, enabling scalable learning from complex agent-environment interactions. Together, Ling-2.6 and Ring-2.6 provide a practical pathway toward efficient, scalable, and open agentic systems. We open-source all checkpoints in the 2.6 family to support further research and development in practical agentic intelligence.
SuperValid: Capability-Aligned OOD Validation for Generalizable Downstream Scaling
May 27, 2026Scaling laws guide large language model training by relating compute to cross-entropy loss, and recent work further extends them to predict downstream benchmark performance. However, prior approaches face generalization limitations from two aspects: focusing on benchmark-level performance introduces scenario-specific artifacts, while relying on IID validation loss fails to track capability improvements when training distributions vary. In this work, we argue that downstream scaling should be studied at the capability level, which captures shared skill factors across related tasks while abstracting away benchmark-specific noise. We propose SuperValid, a framework that synthesizes OOD (out-of-distribution), capability-aligned validation data by distilling core concepts from benchmarks within a capability domain and expanding them into diverse, knowledge-rich texts. Extensive experiments spanning 17 benchmarks grouped into 6 capability domains show that SuperValid loss exhibits strong and stable correlation with downstream performance across models of different architectures, scales, and training data distributions. As a training-free metric computable during training without benchmark evaluation, SuperValid enables effective model selection, early stopping, and scaling decisions.
MergeMix: Optimizing Mid-Training Data Mixtures via Learnable Model Merging
Jan 25, 2026Optimizing data mixtures is essential for unlocking the full potential of large language models (LLMs), yet identifying the optimal composition remains computationally prohibitive due to reliance on heuristic trials or expensive proxy training. To address this, we introduce \textbf{MergeMix}, a novel approach that efficiently determines optimal data mixing ratios by repurposing model merging weights as a high-fidelity, low-cost performance proxy. By training domain-specific experts on minimal tokens and optimizing their merging weights against downstream benchmarks, MergeMix effectively optimizes the performance of data mixtures without incurring the cost of full-scale training. Extensive experiments on models with 8B and 16B parameters validate that MergeMix achieves performance comparable to or surpassing exhaustive manual tuning while drastically reducing search costs. Furthermore, MergeMix exhibits high rank consistency (Spearman $ρ> 0.9$) and strong cross-scale transferability, offering a scalable, automated solution for data mixture optimization.
Arrows of Math Reasoning Data Synthesis for Large Language Models: Diversity, Complexity and Correctness
Aug 26, 2025Enhancing the mathematical reasoning of large language models (LLMs) demands high-quality training data, yet conventional methods face critical challenges in scalability, cost, and data reliability. To address these limitations, we propose a novel program-assisted synthesis framework that systematically generates a high-quality mathematical corpus with guaranteed diversity, complexity, and correctness. This framework integrates mathematical knowledge systems and domain-specific tools to create executable programs. These programs are then translated into natural language problem-solution pairs and vetted by a bilateral validation mechanism that verifies solution correctness against program outputs and ensures program-problem consistency. We have generated 12.3 million such problem-solving triples. Experiments demonstrate that models fine-tuned on our data significantly improve their inference capabilities, achieving state-of-the-art performance on several benchmark datasets and showcasing the effectiveness of our synthesis approach.
Towards Greater Leverage: Scaling Laws for Efficient Mixture-of-Experts Language Models
Jul 24, 2025Mixture-of-Experts (MoE) has become a dominant architecture for scaling Large Language Models (LLMs) efficiently by decoupling total parameters from computational cost. However, this decoupling creates a critical challenge: predicting the model capacity of a given MoE configurations (e.g., expert activation ratio and granularity) remains an unresolved problem. To address this gap, we introduce Efficiency Leverage (EL), a metric quantifying the computational advantage of an MoE model over a dense equivalent. We conduct a large-scale empirical study, training over 300 models up to 28B parameters, to systematically investigate the relationship between MoE architectural configurations and EL. Our findings reveal that EL is primarily driven by the expert activation ratio and the total compute budget, both following predictable power laws, while expert granularity acts as a non-linear modulator with a clear optimal range. We integrate these discoveries into a unified scaling law that accurately predicts the EL of an MoE architecture based on its configuration. To validate our derived scaling laws, we designed and trained Ling-mini-beta, a pilot model for Ling-2.0 series with only 0.85B active parameters, alongside a 6.1B dense model for comparison. When trained on an identical 1T high-quality token dataset, Ling-mini-beta matched the performance of the 6.1B dense model while consuming over 7x fewer computational resources, thereby confirming the accuracy of our scaling laws. This work provides a principled and empirically-grounded foundation for the scaling of efficient MoE models.
WSM: Decay-Free Learning Rate Schedule via Checkpoint Merging for LLM Pre-training
Jul 23, 2025Recent advances in learning rate (LR) scheduling have demonstrated the effectiveness of decay-free approaches that eliminate the traditional decay phase while maintaining competitive performance. Model merging techniques have emerged as particularly promising solutions in this domain. We present Warmup-Stable and Merge (WSM), a general framework that establishes a formal connection between learning rate decay and model merging. WSM provides a unified theoretical foundation for emulating various decay strategies-including cosine decay, linear decay and inverse square root decay-as principled model averaging schemes, while remaining fully compatible with diverse optimization methods. Through extensive experiments, we identify merge duration-the training window for checkpoint aggregation-as the most critical factor influencing model performance, surpassing the importance of both checkpoint interval and merge quantity. Our framework consistently outperforms the widely-adopted Warmup-Stable-Decay (WSD) approach across multiple benchmarks, achieving significant improvements of +3.5% on MATH, +2.9% on HumanEval, and +5.5% on MMLU-Pro. The performance advantages extend to supervised fine-tuning scenarios, highlighting WSM's potential for long-term model refinement.
LLM-Powered Ensemble Learning for Paper Source Tracing: A GPU-Free Approach
Sep 17, 2024


We participated in the KDD CUP 2024 paper source tracing competition and achieved the 3rd place. This competition tasked participants with identifying the reference sources (i.e., ref-sources, as referred to by the organizers of the competition) of given academic papers. Unlike most teams that addressed this challenge by fine-tuning pre-trained neural language models such as BERT or ChatGLM, our primary approach utilized closed-source large language models (LLMs). With recent advancements in LLM technology, closed-source LLMs have demonstrated the capability to tackle complex reasoning tasks in zero-shot or few-shot scenarios. Consequently, in the absence of GPUs, we employed closed-source LLMs to directly generate predicted reference sources from the provided papers. We further refined these predictions through ensemble learning. Notably, our method was the only one among the award-winning approaches that did not require the use of GPUs for model training. Code available at https://github.com/Cklwanfifa/KDDCUP2024-PST.
GP-NAS-ensemble: a model for NAS Performance Prediction
Jan 23, 2023



It is of great significance to estimate the performance of a given model architecture without training in the application of Neural Architecture Search (NAS) as it may take a lot of time to evaluate the performance of an architecture. In this paper, a novel NAS framework called GP-NAS-ensemble is proposed to predict the performance of a neural network architecture with a small training dataset. We make several improvements on the GP-NAS model to make it share the advantage of ensemble learning methods. Our method ranks second in the CVPR2022 second lightweight NAS challenge performance prediction track.
DQN Control Solution for KDD Cup 2021 City Brain Challenge
Aug 14, 2021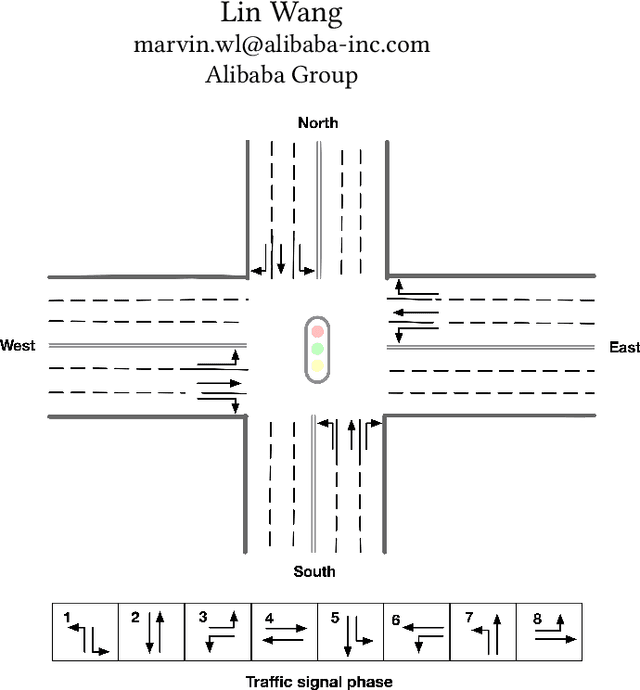

We took part in the city brain challenge competition and achieved the 8th place. In this competition, the players are provided with a real-world city-scale road network and its traffic demand derived from real traffic data. The players are asked to coordinate the traffic signals with a self-designed agent to maximize the number of vehicles served while maintaining an acceptable delay. In this abstract paper, we present an overall analysis and our detailed solution to this competition. Our approach is mainly based on the adaptation of the deep Q-network (DQN) for real-time traffic signal control. From our perspective, the major challenge of this competition is how to extend the classical DQN framework to traffic signals control in real-world complex road network and traffic flow situation. After trying and implementing several classical reward functions, we finally chose to apply our newly-designed reward in our agent. By applying our newly-proposed reward function and carefully tuning the control scheme, an agent based on a single DQN model can rank among the top 15 teams. We hope this paper could serve, to some extent, as a baseline solution to traffic signal control of real-world road network and inspire further attempts and researches.