 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Generative Model for Efficient 3D Airfoil Parameterization and Generation
Jan 07, 2021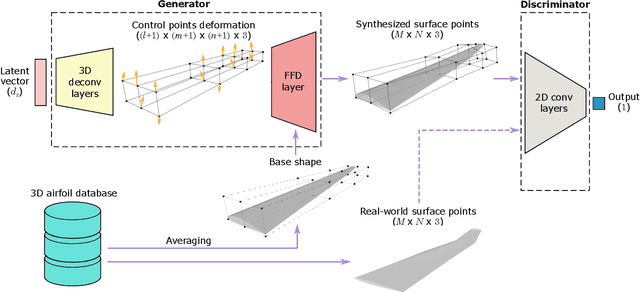
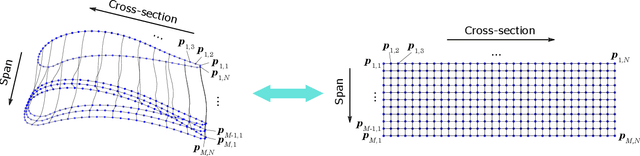
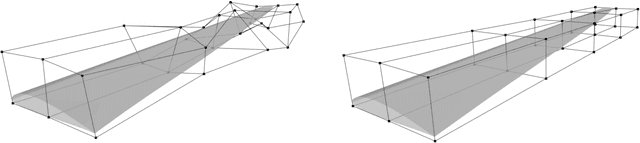

In aerodynamic shape optimization, the convergence and computational cost are greatly affected by the representation capacity and compactness of the design space. Previous research has demonstrated that using a deep generative model to parameterize two-dimensional (2D) airfoils achieves high representation capacity/compactness, which significantly benefits shape optimization. In this paper, we propose a deep generative model, Free-Form Deformation Generative Adversarial Networks (FFD-GAN), that provides an efficient parameterization for three-dimensional (3D) aerodynamic/hydrodynamic shapes like aircraft wings, turbine blades, car bodies, and hulls. The learned model maps a compact set of design variables to 3D surface points representing the shape. We ensure the surface smoothness and continuity of generated geometries by incorporating an FFD layer into the generative model. We demonstrate FFD-GAN's performance using a wing shape design example. The results show that FFD-GAN can generate realistic designs and form a reasonable parameterization. We further demonstrate FFD-GAN's high representation compactness and capacity by testing its design space coverage, the feasibility ratio of the design space, and its performance in design optimization. We demonstrate that over 94% feasibility ratio is achieved among wings randomly generated by the FFD-GAN, while FFD and B-spline only achieve less than 31%. We also show that the FFD-GAN leads to an order of magnitude faster convergence in a wing shape optimization problem, compared to the FFD and the B-spline parameterizations.
DDRQA: Dynamic Document Reranking for Open-domain Multi-hop Question Answering
Sep 16, 2020
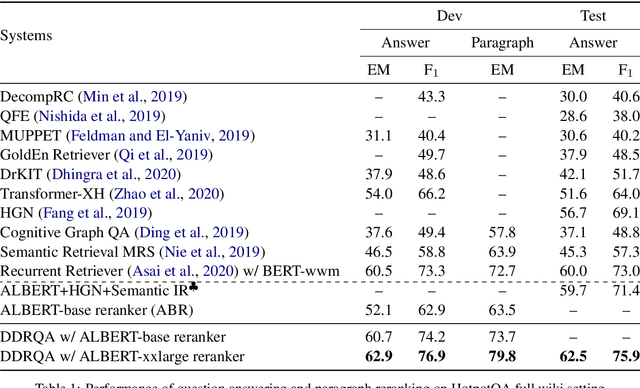
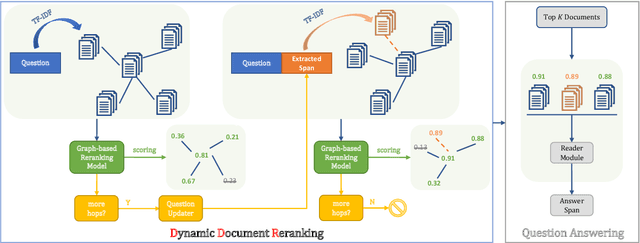
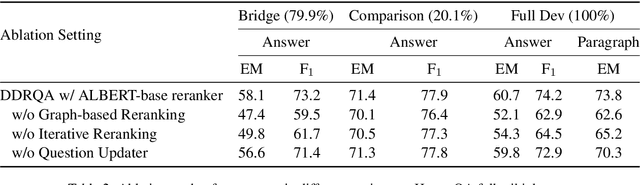
Open-domain multi-hop question answering (QA) requires to retrieve multiple supporting documents, some of which have little lexical overlap with the question and can only be located by iterative document retrieval. However, multi-step document retrieval often incurs more relevant but non-supporting documents, which dampens the downstream noise-sensitive reader module for answer extraction. To address this challenge, we propose Dynamic Document Reranking (DDR) to iteratively retrieve, rerank and filter documents, and adaptively determine when to stop the retrieval process. DDR employs an entity-linked document graph for multi-document interaction, which boosts up the retrieval performance. Experiments on HotpotQA full wiki setting show that our method achieves more than 7 points higher reranking performance over the previous best retrieval model, and also achieves state-of-the-art question answering performance on the official leaderboard.
Conditional Neural Architecture Search
Jun 06, 2020



Designing resource-efficient Deep Neural Networks (DNNs) is critical to deploy deep learning solutions over edge platforms due to diverse performance, power, and memory budgets. Unfortunately, it is often the case a well-trained ML model does not fit to the constraint of deploying edge platforms, causing a long iteration of model reduction and retraining process. Moreover, a ML model optimized for platform-A often may not be suitable when we deploy it on another platform-B, causing another iteration of model retraining. We propose a conditional neural architecture search method using GAN, which produces feasible ML models for different platforms. We present a new workflow to generate constraint-optimized DNN models. This is the first work of bringing in condition and adversarial technique into Neural Architecture Search domain. We verify the method with regression problems and classification on CIFAR-10. The proposed workflow can successfully generate resource-optimized MLP or CNN-based networks.
Generative Design of Hardware-aware DNNs
Jun 06, 2020



To efficiently run DNNs on the edge/cloud, many new DNN inference accelerators are being designed and deployed frequently. To enhance the resource efficiency of DNNs, model quantization is a widely-used approach. However, different accelerator/HW has different resources leading to the need for specialized quantization strategy of each HW. Moreover, using the same quantization for every layer may be sub-optimal, increasing the designspace of possible quantization choices. This makes manual-tuning infeasible. Recent work in automatically determining quantization for each layer is driven by optimization methods such as reinforcement learning. However, these approaches need re-training the RL for every new HW platform. We propose a new way for autonomous quantization and HW-aware tuning. We propose a generative model, AQGAN, which takes a target accuracy as the condition and generates a suite of quantization configurations. With the conditional generative model, the user can autonomously generate different configurations with different targets in inference time. Moreover, we propose a simplified HW-tuning flow, which uses the generative model to generate proposals and execute simple selection based on the HW resource budget, whose process is fast and interactive. We evaluate our model on five of the widely-used efficient models on the ImageNet dataset. We compare with existing uniform quantization and state-of-the-art autonomous quantization methods. Our generative model shows competitive achieved accuracy, however, with around two degrees less search cost for each design point. Our generative model shows the generated quantization configuration can lead to less than 3.5% error across all experiments.
DC-BERT: Decoupling Question and Document for Efficient Contextual Encoding
Feb 28, 2020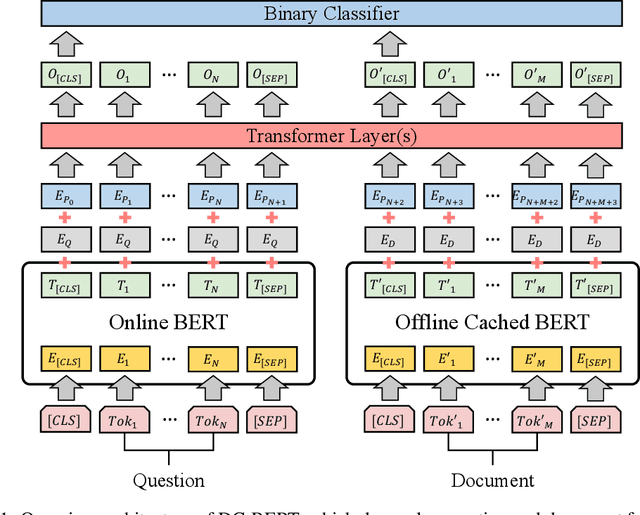
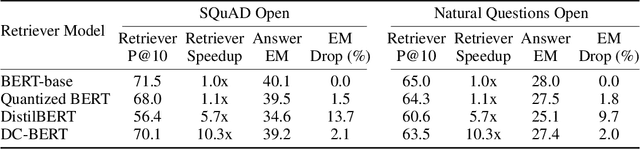
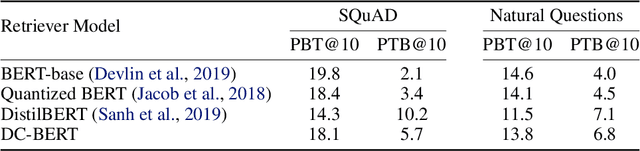
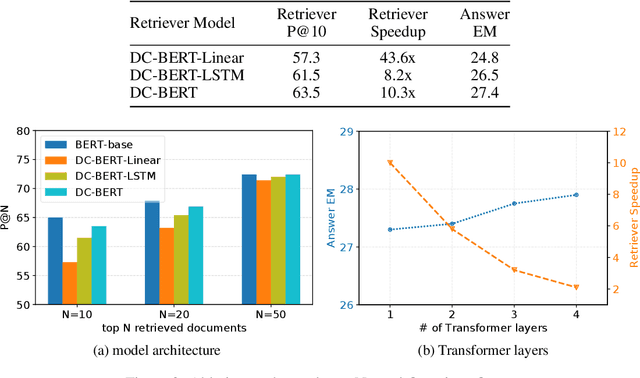
Recent studies on open-domain question answering have achieved prominent performance improvement using pre-trained language models such as BERT. State-of-the-art approaches typically follow the "retrieve and read" pipeline and employ BERT-based reranker to filter retrieved documents before feeding them into the reader module. The BERT retriever takes as input the concatenation of question and each retrieved document. Despite the success of these approaches in terms of QA accuracy, due to the concatenation, they can barely handle high-throughput of incoming questions each with a large collection of retrieved documents. To address the efficiency problem, we propose DC-BERT, a decoupled contextual encoding framework that has dual BERT models: an online BERT which encodes the question only once, and an offline BERT which pre-encodes all the documents and caches their encodings. On SQuAD Open and Natural Questions Open datasets, DC-BERT achieves 10x speedup on document retrieval, while retaining most (about 98%) of the QA performance compared to state-of-the-art approaches for open-domain question answering.
Efficient Probabilistic Logic Reasoning with Graph Neural Networks
Feb 04, 2020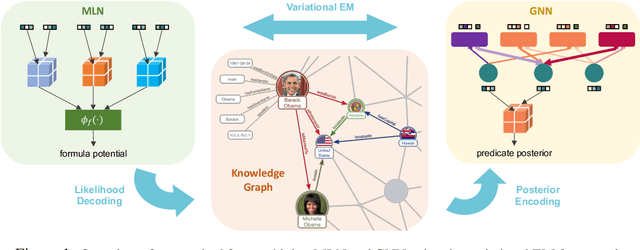
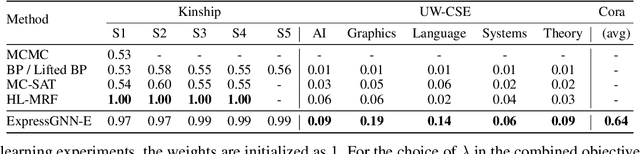
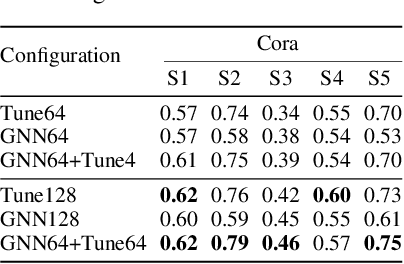
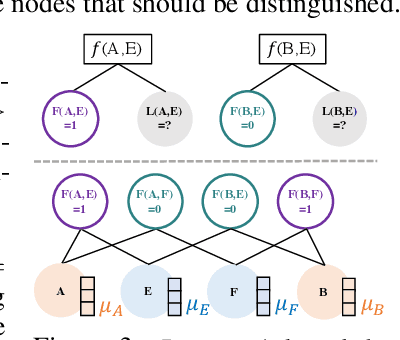
Markov Logic Networks (MLNs), which elegantly combine logic rules and probabilistic graphical models, can be used to address many knowledge graph problems. However, inference in MLN is computationally intensive, making the industrial-scale application of MLN very difficult. In recent years, graph neural networks (GNNs) have emerged as efficient and effective tools for large-scale graph problems. Nevertheless, GNNs do not explicitly incorporate prior logic rules into the models, and may require many labeled examples for a target task. In this paper, we explore the combination of MLNs and GNNs, and use graph neural networks for variational inference in MLN. We propose a GNN variant, named ExpressGNN, which strikes a nice balance between the representation power and the simplicity of the model. Our extensive experiments on several benchmark datasets demonstrate that ExpressGNN leads to effective and efficient probabilistic logic reasoning.
Can Graph Neural Networks Help Logic Reasoning?
Jun 27, 2019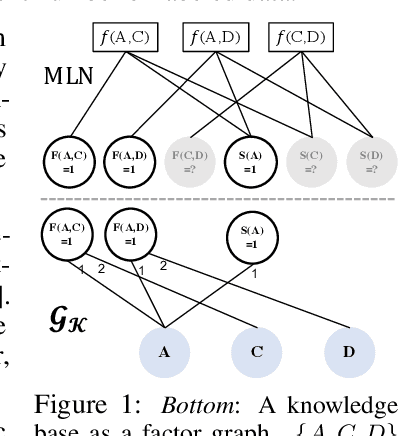
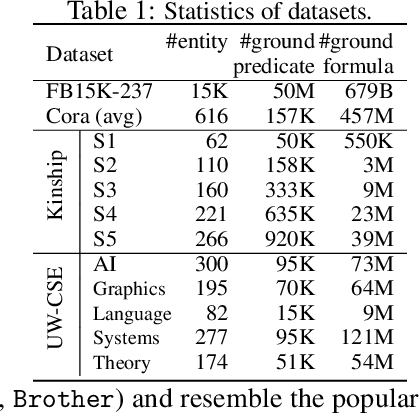

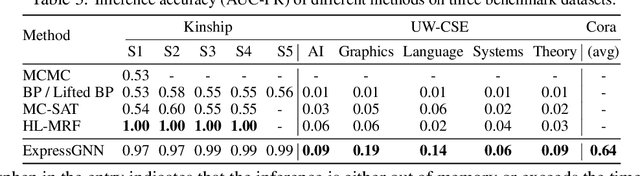
Effectively combining logic reasoning and probabilistic inference has been a long-standing goal of machine learning: the former has the ability to generalize with small training data, while the latter provides a principled framework for dealing with noisy data. However, existing methods for combining the best of both worlds are typically computationally intensive. In this paper, we focus on Markov Logic Networks and explore the use of graph neural networks (GNNs) for representing probabilistic logic inference. It is revealed from our analysis that the representation power of GNN alone is not enough for such a task. We instead propose a more expressive variant, called ExpressGNN, which can perform effective probabilistic logic inference while being able to scale to a large number of entities. We demonstrate by several benchmark datasets that ExpressGNN has the potential to advance probabilistic logic reasoning to the next stage.