 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffectAgent: Collaborative Multi-Agent Reasoning for Retrieval-Augmented Multimodal Emotion Recognition
Apr 14, 2026LLM-based multimodal emotion recognition relies on static parametric memory and often hallucinates when interpreting nuanced affective states. In this paper, given that single-round retrieval-augmented generation is highly susceptible to modal ambiguity and therefore struggles to capture complex affective dependencies across modalities, we introduce AffectAgent, an affect-oriented multi-agent retrieval-augmented generation framework that leverages collaborative decision-making among agents for fine-grained affective understanding. Specifically, AffectAgent comprises three jointly optimized specialized agents, namely a query planner, an evidence filter, and an emotion generator, which collaboratively perform analytical reasoning to retrieve cross-modal samples, assess evidence, and generate predictions. These agents are optimized end-to-end using Multi-Agent Proximal Policy Optimization (MAPPO) with a shared affective reward to ensure consistent emotion understanding. Furthermore, we introduce Modality-Balancing Mixture of Experts (MB-MoE) and Retrieval-Augmented Adaptive Fusion (RAAF), where MB-MoE dynamically regulates the contributions of different modalities to mitigate representation mismatch caused by cross-modal heterogeneity, while RAAF enhances semantic completion under missing-modality conditions by incorporating retrieved audiovisual embeddings. Extensive experiments on MER-UniBench demonstrate that AffectAgent achieves superior performance across complex scenarios. Our code will be released at: https://github.com/Wz1h1NG/AffectAgent.
When Identities Collapse: A Stress-Test Benchmark for Multi-Subject Personalization
Mar 27, 2026Subject-driven text-to-image diffusion models have achieved remarkable success in preserving single identities, yet their ability to compose multiple interacting subjects remains largely unexplored and highly challenging. Existing evaluation protocols typically rely on global CLIP metrics, which are insensitive to local identity collapse and fail to capture the severity of multi-subject entanglement. In this paper, we identify a pervasive "Illusion of Scalability" in current models: while they excel at synthesizing 2-4 subjects in simple layouts, they suffer from catastrophic identity collapse when scaled to 6-10 subjects or tasked with complex physical interactions. To systematically expose this failure mode, we construct a rigorous stress-test benchmark comprising 75 prompts distributed across varying subject counts and interaction difficulties (Neutral, Occlusion, Interaction). Furthermore, we demonstrate that standard CLIP-based metrics are fundamentally flawed for this task, as they often assign high scores to semantically correct but identity-collapsed images (e.g., generating generic clones). To address this, we introduce the Subject Collapse Rate (SCR), a novel evaluation metric grounded in DINOv2's structural priors, which strictly penalizes local attention leakage and homogenization. Our extensive evaluation of state-of-the-art models (MOSAIC, XVerse, PSR) reveals a precipitous drop in identity fidelity as scene complexity grows, with SCR approaching 100% at 10 subjects. We trace this collapse to the semantic shortcuts inherent in global attention routing, underscoring the urgent need for explicit physical disentanglement in future generative architectures.
$Δ$VLA: Prior-Guided Vision-Language-Action Models via World Knowledge Variation
Mar 09, 2026Recent vision-language-action (VLA) models have significantly advanced robotic manipulation by unifying perception, reasoning, and control. To achieve such integration, recent studies adopt a predictive paradigm that models future visual states or world knowledge to guide action generation. However, these models emphasize forecasting outcomes rather than reasoning about the underlying process of change, which is essential for determining how to act. To address this, we propose $Δ$VLA, a prior-guided framework that models world-knowledge variations relative to an explicit current-world knowledge prior for action generation, rather than regressing absolute future world states. Specifically, 1) to construct the current world knowledge prior, we propose the Prior-Guided WorldKnowledge Extractor (PWKE). It extracts manipulable regions, spatial relations, and semantic cues from the visual input, guided by auxiliary heads and prior pseudo labels, thus reducing redundancy. 2) Building upon this, to represent how world knowledge evolves under actions, we introduce the Latent World Variation Quantization (LWVQ). It learns a discrete latent space via a VQ-VAE objective to encode world knowledge variations, shifting prediction from full modalities to compact latent. 3)Moreover, to mitigate interference during variation modeling, we design the Conditional Variation Attention (CV-Atten), whichpromotes disentangled learning and preserves the independence of knowledge representations. Extensive experiments on both simulated benchmarks and real-world robotic tasks demonstrate $Δ$VLA achieves state-of-the-art performance while improving efficiency. Code and real-world execution videos are available at https://github.com/JiuTian-VL/DeltaVLA.
REAP: Enhancing RAG with Recursive Evaluation and Adaptive Planning for Multi-Hop Question Answering
Nov 13, 2025



Retrieval-augmented generation (RAG) has been extensively employed to mitigate hallucinations in large language models (LLMs). However, existing methods for multi-hop reasoning tasks often lack global planning, increasing the risk of falling into local reasoning impasses. Insufficient exploitation of retrieved content and the neglect of latent clues fail to ensure the accuracy of reasoning outcomes. To overcome these limitations, we propose Recursive Evaluation and Adaptive Planning (REAP), whose core idea is to explicitly maintain structured sub-tasks and facts related to the current task through the Sub-task Planner (SP) and Fact Extractor (FE) modules. SP maintains a global perspective, guiding the overall reasoning direction and evaluating the task state based on the outcomes of FE, enabling dynamic optimization of the task-solving trajectory. FE performs fine-grained analysis over retrieved content to extract reliable answers and clues. These two modules incrementally enrich a logically coherent representation of global knowledge, enhancing the reliability and the traceability of the reasoning process. Furthermore, we propose a unified task paradigm design that enables effective multi-task fine-tuning, significantly enhancing SP's performance on complex, data-scarce tasks. We conduct extensive experiments on multiple public multi-hop datasets, and the results demonstrate that our method significantly outperforms existing RAG methods in both in-domain and out-of-domain settings, validating its effectiveness in complex multi-hop reasoning tasks.
Gland Segmentation Using SAM With Cancer Grade as a Prompt
Jan 27, 2025Cancer grade is a critical clinical criterion that can be used to determine the degree of cancer malignancy. Revealing the condition of the glands, a precise gland segmentation can assist in a more effective cancer grade classification. In machine learning, binary classification information about glands (i.e., benign and malignant) can be utilized as a prompt for gland segmentation and cancer grade classification. By incorporating prior knowledge of the benign or malignant classification of the gland, the model can anticipate the likely appearance of the target, leading to better segmentation performance. We utilize Segment Anything Model to solve the segmentation task, by taking advantage of its prompt function and applying appropriate modifications to the model structure and training strategies. We improve the results from fine-tuned Segment Anything Model and produce SOTA results using this approach.
TrafficGPT: Towards Multi-Scale Traffic Analysis and Generation with Spatial-Temporal Agent Framework
May 08, 2024The precise prediction of multi-scale traffic is a ubiquitous challenge in the urbanization process for car owners, road administrators, and governments. In the case of complex road networks, current and past traffic information from both upstream and downstream roads are crucial since various road networks have different semantic information about traffic. Rationalizing the utilization of semantic information can realize short-term, long-term, and unseen road traffic prediction. As the demands of multi-scale traffic analysis increase, on-demand interactions and visualizations are expected to be available for transportation participants. We have designed a multi-scale traffic generation system, namely TrafficGPT, using three AI agents to process multi-scale traffic data, conduct multi-scale traffic analysis, and present multi-scale visualization results. TrafficGPT consists of three essential AI agents: 1) a text-to-demand agent that is employed with Question & Answer AI to interact with users and extract prediction tasks through texts; 2) a traffic prediction agent that leverages multi-scale traffic data to generate temporal features and similarity, and fuse them with limited spatial features and similarity, to achieve accurate prediction of three tasks; and 3) a suggestion and visualization agent that uses the prediction results to generate suggestions and visualizations, providing users with a comprehensive understanding of traffic conditions. Our TrafficGPT system focuses on addressing concerns about traffic prediction from transportation participants, and conducted extensive experiments on five real-world road datasets to demonstrate its superior predictive and interactive performance
ZSL-RPPO: Zero-Shot Learning for Quadrupedal Locomotion in Challenging Terrains using Recurrent Proximal Policy Optimization
Mar 04, 2024



We present ZSL-RPPO, an improved zero-shot learning architecture that overcomes the limitations of teacher-student neural networks and enables generating robust, reliable, and versatile locomotion for quadrupedal robots in challenging terrains. We propose a new algorithm RPPO (Recurrent Proximal Policy Optimization) that directly trains recurrent neural network in partially observable environments and results in more robust training using domain randomization. Our locomotion controller supports extensive perturbation across simulation-to-reality transfer for both intrinsic and extrinsic physical parameters without further fine-tuning. This can avoid the significant decline of student's performance during simulation-to-reality transfer and therefore enhance the robustness and generalization of the locomotion controller. We deployed our controller on the Unitree A1 and Aliengo robots in real environment and exteroceptive perception is provided by either a solid-state Lidar or a depth camera. Our locomotion controller was tested in various challenging terrains like slippery surfaces, Grassy Terrain, and stairs. Our experiment results and comparison show that our approach significantly outperforms the state-of-the-art.
GPT-Fathom: Benchmarking Large Language Models to Decipher the Evolutionary Path towards GPT-4 and Beyond
Oct 10, 2023With the rapid advancement of large language models (LLMs), there is a pressing need for a comprehensive evaluation suite to assess their capabilities and limitations. Existing LLM leaderboards often reference scores reported in other papers without consistent settings and prompts, which may inadvertently encourage cherry-picking favored settings and prompts for better results. In this work, we introduce GPT-Fathom, an open-source and reproducible LLM evaluation suite built on top of OpenAI Evals. We systematically evaluate 10+ leading LLMs as well as OpenAI's legacy models on 20+ curated benchmarks across 7 capability categories, all under aligned settings. Our retrospective study on OpenAI's earlier models offers valuable insights into the evolutionary path from GPT-3 to GPT-4. Currently, the community is eager to know how GPT-3 progressively improves to GPT-4, including technical details like whether adding code data improves LLM's reasoning capability, which aspects of LLM capability can be improved by SFT and RLHF, how much is the alignment tax, etc. Our analysis sheds light on many of these questions, aiming to improve the transparency of advanced LLMs.
Marine Debris Detection in Satellite Surveillance using Attention Mechanisms
Jul 09, 2023Marine debris is an important issue for environmental protection, but current methods for locating marine debris are yet limited. In order to achieve higher efficiency and wider applicability in the localization of Marine debris, this study tries to combine the instance segmentation of YOLOv7 with different attention mechanisms and explores the best model. By utilizing a labelled dataset consisting of satellite images containing ocean debris, we examined three attentional models including lightweight coordinate attention, CBAM (combining spatial and channel focus), and bottleneck transformer (based on self-attention). Box detection assessment revealed that CBAM achieved the best outcome (F1 score of 77%) compared to coordinate attention (F1 score of 71%) and YOLOv7/bottleneck transformer (both F1 scores around 66%). Mask evaluation showed CBAM again leading with an F1 score of 73%, whereas coordinate attention and YOLOv7 had comparable performances (around F1 score of 68%/69%) and bottleneck transformer lagged behind at F1 score of 56%. These findings suggest that CBAM offers optimal suitability for detecting marine debris. However, it should be noted that the bottleneck transformer detected some areas missed by manual annotation and displayed better mask precision for larger debris pieces, signifying potentially superior practical performance.
Monolith: Real Time Recommendation System With Collisionless Embedding Table
Sep 27, 2022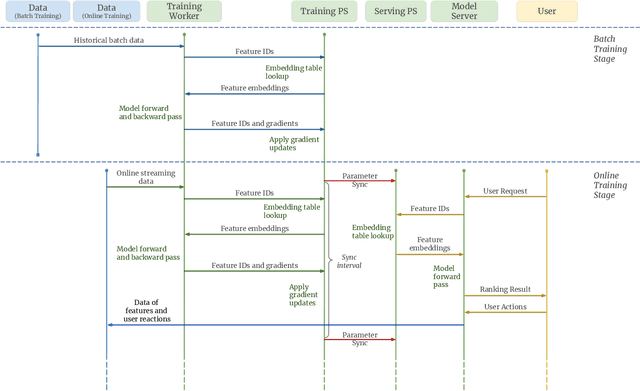

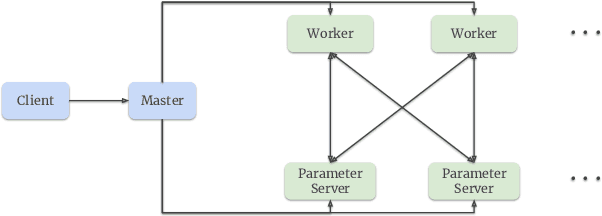
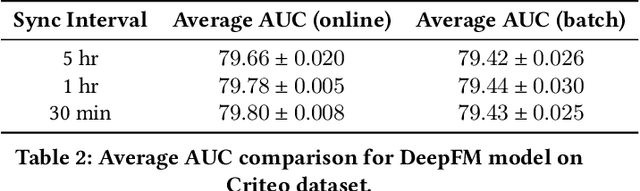
Building a scalable and real-time recommendation system is vital for many businesses driven by time-sensitive customer feedback, such as short-videos ranking or online ads. Despite the ubiquitous adoption of production-scale deep learning frameworks like TensorFlow or PyTorch, these general-purpose frameworks fall short of business demands in recommendation scenarios for various reasons: on one hand, tweaking systems based on static parameters and dense computations for recommendation with dynamic and sparse features is detrimental to model quality; on the other hand, such frameworks are designed with batch-training stage and serving stage completely separated, preventing the model from interacting with customer feedback in real-time. These issues led us to reexamine traditional approaches and explore radically different design choices. In this paper, we present Monolith, a system tailored for online training. Our design has been driven by observations of our application workloads and production environment that reflects a marked departure from other recommendations systems. Our contributions are manifold: first, we crafted a collisionless embedding table with optimizations such as expirable embeddings and frequency filtering to reduce its memory footprint; second, we provide an production-ready online training architecture with high fault-tolerance; finally, we proved that system reliability could be traded-off for real-time learning. Monolith has successfully landed in the BytePlus Recommend product.