 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
ICE-GRT: Instruction Context Enhancement by Generative Reinforcement based Transformers
Jan 04, 2024The emergence of Large Language Models (LLMs) such as ChatGPT and LLaMA encounter limitations in domain-specific tasks, with these models often lacking depth and accuracy in specialized areas, and exhibiting a decrease in general capabilities when fine-tuned, particularly analysis ability in small sized models. To address these gaps, we introduce ICE-GRT, utilizing Reinforcement Learning from Human Feedback (RLHF) grounded in Proximal Policy Optimization (PPO), demonstrating remarkable ability in in-domain scenarios without compromising general task performance. Our exploration of ICE-GRT highlights its understanding and reasoning ability to not only generate robust answers but also to provide detailed analyses of the reasons behind the answer. This capability marks a significant progression beyond the scope of Supervised Fine-Tuning models. The success of ICE-GRT is dependent on several crucial factors, including Appropriate Data, Reward Size Scaling, KL-Control, Advantage Normalization, etc. The ICE-GRT model exhibits state-of-the-art performance in domain-specific tasks and across 12 general Language tasks against equivalent size and even larger size LLMs, highlighting the effectiveness of our approach. We provide a comprehensive analysis of the ICE-GRT, underscoring the significant advancements it brings to the field of LLM.
Balancing Specialized and General Skills in LLMs: The Impact of Modern Tuning and Data Strategy
Oct 07, 2023



This paper introduces a multifaceted methodology for fine-tuning and evaluating large language models (LLMs) for specialized monetization tasks. The goal is to balance general language proficiency with domain-specific skills. The methodology has three main components: 1) Carefully blending in-domain and general-purpose data during fine-tuning to achieve an optimal balance between general and specialized capabilities; 2) Designing a comprehensive evaluation framework with 45 questions tailored to assess performance on functionally relevant dimensions like reliability, consistency, and business impact; 3) Analyzing how model size and continual training influence metrics to guide efficient resource allocation during fine-tuning. The paper details the design, data collection, analytical techniques, and results validating the proposed frameworks. It aims to provide businesses and researchers with actionable insights on effectively adapting LLMs for specialized contexts. We also intend to make public the comprehensive evaluation framework, which includes the 45 tailored questions and their respective scoring guidelines, to foster transparency and collaboration in adapting LLMs for specialized tasks.
Monolith: Real Time Recommendation System With Collisionless Embedding Table
Sep 27, 2022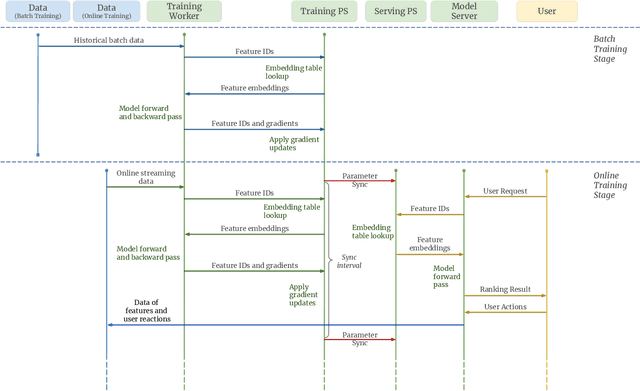

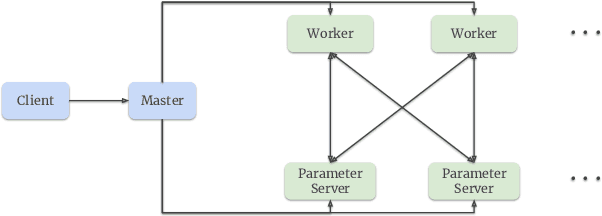
Building a scalable and real-time recommendation system is vital for many businesses driven by time-sensitive customer feedback, such as short-videos ranking or online ads. Despite the ubiquitous adoption of production-scale deep learning frameworks like TensorFlow or PyTorch, these general-purpose frameworks fall short of business demands in recommendation scenarios for various reasons: on one hand, tweaking systems based on static parameters and dense computations for recommendation with dynamic and sparse features is detrimental to model quality; on the other hand, such frameworks are designed with batch-training stage and serving stage completely separated, preventing the model from interacting with customer feedback in real-time. These issues led us to reexamine traditional approaches and explore radically different design choices. In this paper, we present Monolith, a system tailored for online training. Our design has been driven by observations of our application workloads and production environment that reflects a marked departure from other recommendations systems. Our contributions are manifold: first, we crafted a collisionless embedding table with optimizations such as expirable embeddings and frequency filtering to reduce its memory footprint; second, we provide an production-ready online training architecture with high fault-tolerance; finally, we proved that system reliability could be traded-off for real-time learning. Monolith has successfully landed in the BytePlus Recommend product.
CowClip: Reducing CTR Prediction Model Training Time from 12 hours to 10 minutes on 1 GPU
Apr 22, 2022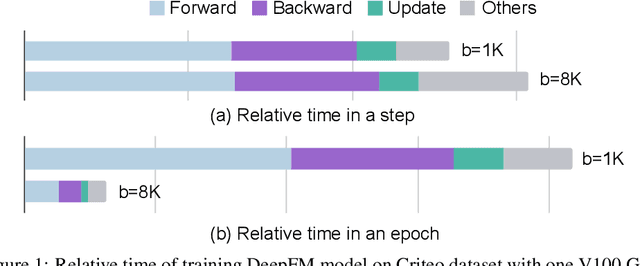
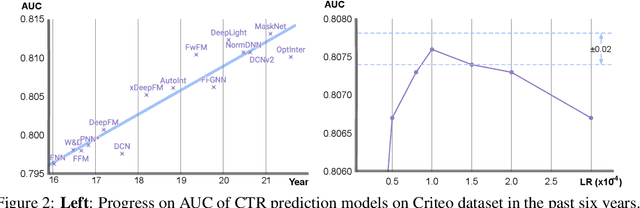
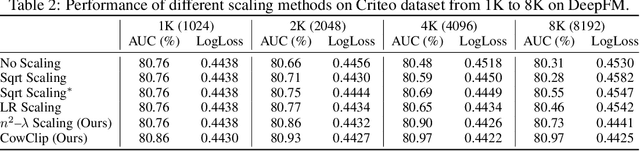
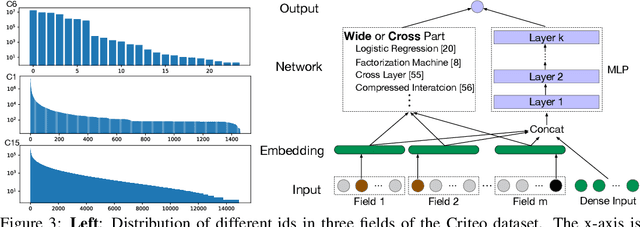
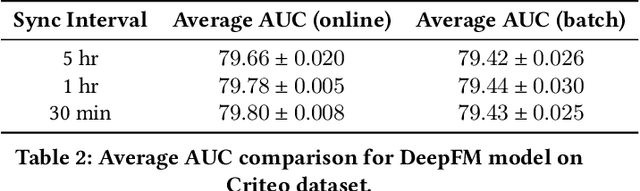
The click-through rate (CTR) prediction task is to predict whether a user will click on the recommended item. As mind-boggling amounts of data are produced online daily, accelerating CTR prediction model training is critical to ensuring an up-to-date model and reducing the training cost. One approach to increase the training speed is to apply large batch training. However, as shown in computer vision and natural language processing tasks, training with a large batch easily suffers from the loss of accuracy. Our experiments show that previous scaling rules fail in the training of CTR prediction neural networks. To tackle this problem, we first theoretically show that different frequencies of ids make it challenging to scale hyperparameters when scaling the batch size. To stabilize the training process in a large batch size setting, we develop the adaptive Column-wise Clipping (CowClip). It enables an easy and effective scaling rule for the embeddings, which keeps the learning rate unchanged and scales the L2 loss. We conduct extensive experiments with four CTR prediction networks on two real-world datasets and successfully scaled 128 times the original batch size without accuracy loss. In particular, for CTR prediction model DeepFM training on the Criteo dataset, our optimization framework enlarges the batch size from 1K to 128K with over 0.1% AUC improvement and reduces training time from 12 hours to 10 minutes on a single V100 GPU. Our code locates at https://github.com/bytedance/LargeBatchCTR.
Toward Annotator Group Bias in Crowdsourcing
Oct 08, 2021
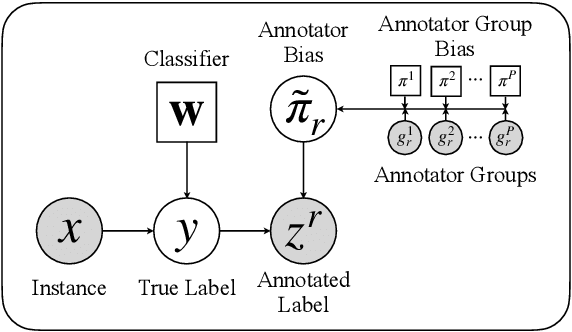

Crowdsourcing has emerged as a popular approach for collecting annotated data to train supervised machine learning models. However, annotator bias can lead to defective annotations. Though there are a few works investigating individual annotator bias, the group effects in annotators are largely overlooked. In this work, we reveal that annotators within the same demographic group tend to show consistent group bias in annotation tasks and thus we conduct an initial study on annotator group bias. We first empirically verify the existence of annotator group bias in various real-world crowdsourcing datasets. Then, we develop a novel probabilistic graphical framework GroupAnno to capture annotator group bias with a new extended Expectation Maximization (EM) training algorithm. We conduct experiments on both synthetic and real-world datasets. Experimental results demonstrate the effectiveness of our model in modeling annotator group bias in label aggregation and model learning over competitive baselines.
Active Multitask Learning with Committees
Mar 24, 2021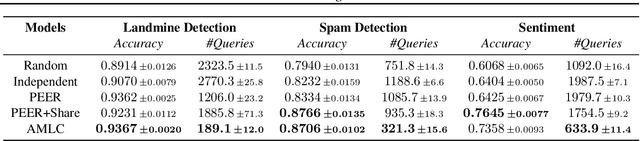
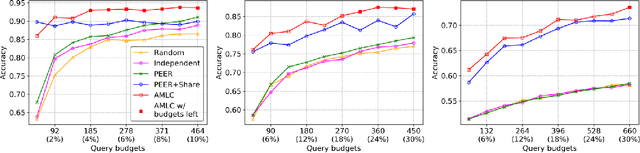
The cost of annotating training data has traditionally been a bottleneck for supervised learning approaches. The problem is further exacerbated when supervised learning is applied to a number of correlated tasks simultaneously since the amount of labels required scales with the number of tasks. To mitigate this concern, we propose an active multitask learning algorithm that achieves knowledge transfer between tasks. The approach forms a so-called committee for each task that jointly makes decisions and directly shares data across similar tasks. Our approach reduces the number of queries needed during training while maintaining high accuracy on test data. Empirical results on benchmark datasets show significant improvements on both accuracy and number of query requests.
Learning Correlated Latent Representations with Adaptive Priors
Jul 16, 2019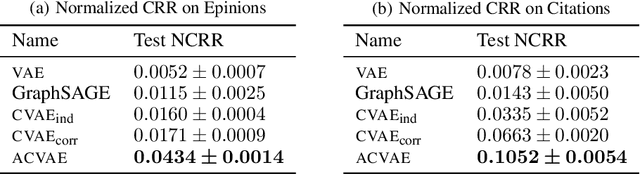
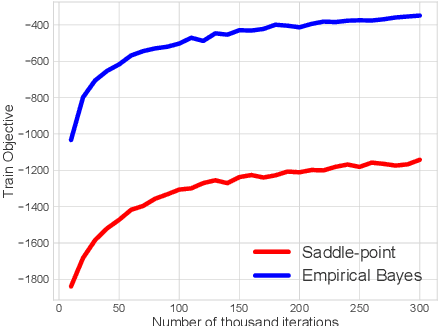
Variational Auto-Encoders (VAEs) have been widely applied for learning compact low-dimensional latent representations for high-dimensional data. When the correlation structure among data points is available, previous work proposed Correlated Variational Auto-Encoders (CVAEs) which employ a structured mixture model as prior and a structured variational posterior for each mixture component to enforce the learned latent representations to follow the same correlation structure. However, as we demonstrate in this paper, such a choice can not guarantee that CVAEs can capture all of the correlations. Furthermore, it prevents us from obtaining a tractable joint and marginal variational distribution. To address these issues, we propose Adaptive Correlated Variational Auto-Encoders (ACVAEs), which apply an adaptive prior distribution that can be adjusted during training, and learn a tractable joint distribution via a saddle-point optimization procedure. Its tractable form also enables further refinement with belief propagation. Experimental results on two real datasets show that ACVAEs outperform other benchmarks significantly.
Correlated Variational Auto-Encoders
May 16, 2019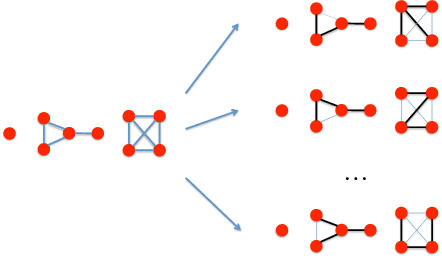
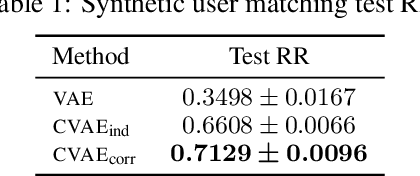

Variational Auto-Encoders (VAEs) are capable of learning latent representations for high dimensional data. However, due to the i.i.d. assumption, VAEs only optimize the singleton variational distributions and fail to account for the correlations between data points, which might be crucial for learning latent representations from dataset where a priori we know correlations exist. We propose Correlated Variational Auto-Encoders (CVAEs) that can take the correlation structure into consideration when learning latent representations with VAEs. CVAEs apply a prior based on the correlation structure. To address the intractability introduced by the correlated prior, we develop an approximation by average of a set of tractable lower bounds over all maximal acyclic subgraphs of the undirected correlation graph. Experimental results on matching and link prediction on public benchmark rating datasets and spectral clustering on a synthetic dataset show the effectiveness of the proposed method over baseline algorithms.
The Variational Predictive Natural Gradient
Mar 07, 2019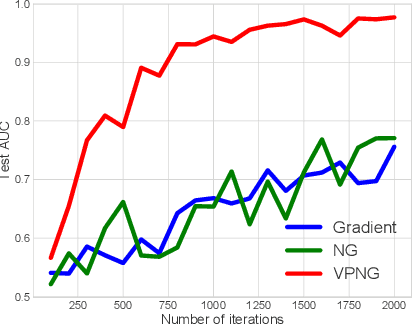
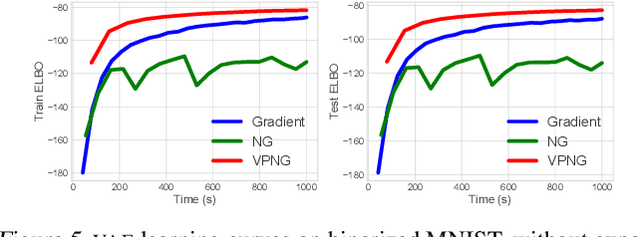
Variational inference transforms posterior inference into parametric optimization thereby enabling the use of latent variable models where otherwise impractical. However, variational inference can be finicky when different variational parameters control variables that are strongly correlated under the model. Traditional natural gradients based on the variational approximation fail to correct for correlations when the approximation is not the true posterior. To address this, we construct a new natural gradient called the variational predictive natural gradient. It is constructed as an average of the Fisher information of the reparameterized predictive model distribution. Unlike traditional natural gradients for variational inference, this natural gradient accounts for the relationship between model parameters and variational parameters. We also show the variational predictive natural gradient relates to the negative Hessian of the expected log-likelihood. A simple example shows the insight. We demonstrate the empirical value of our method on a classification task, a deep generative model of images, and probabilistic matrix factorization for recommendation.