 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion of Interest Segmentation and Morphological Analysis for Membranes in Cryo-Electron Tomography
Feb 24, 2026Cryo-electron tomography (cryo-ET) enables high resolution, three-dimensional reconstruction of biological structures, including membranes and membrane proteins. Identification of regions of interest (ROIs) is central to scientific imaging, as it enables isolation and quantitative analysis of specific structural features within complex datasets. In practice, however, ROIs are typically derived indirectly through full structure segmentation followed by post hoc analysis. This limitation is especially apparent for continuous and geometrically complex structures such as membranes, which are segmented as single entities. Here, we developed TomoROIS-SurfORA, a two step framework for direct, shape-agnostic ROI segmentation and morphological surface analysis. TomoROIS performs deep learning-based ROI segmentation and can be trained from scratch using small annotated datasets, enabling practical application across diverse imaging data. SurfORA processes segmented structures as point clouds and surface meshes to extract quantitative morphological features, including inter-membrane distances, curvature, and surface roughness. It supports both closed and open surfaces, with specific considerations for open surfaces, which are common in cryo-ET due to the missing wedge effect. We demonstrate both tools using in vitro reconstituted membrane systems containing deformable vesicles with complex geometries, enabling automatic quantitative analysis of membrane contact sites and remodeling events such as invagination. While demonstrated here on cryo-ET membrane data, the combined approach is applicable to ROI detection and surface analysis in broader scientific imaging contexts.
Training Compute-Optimal Protein Language Models
Nov 04, 2024We explore optimally training protein language models, an area of significant interest in biological research where guidance on best practices is limited. Most models are trained with extensive compute resources until performance gains plateau, focusing primarily on increasing model sizes rather than optimizing the efficient compute frontier that balances performance and compute budgets. Our investigation is grounded in a massive dataset consisting of 939 million protein sequences. We trained over 300 models ranging from 3.5 million to 10.7 billion parameters on 5 to 200 billion unique tokens, to investigate the relations between model sizes, training token numbers, and objectives. First, we observed the effect of diminishing returns for the Causal Language Model (CLM) and that of overfitting for the Masked Language Model~(MLM) when repeating the commonly used Uniref database. To address this, we included metagenomic protein sequences in the training set to increase the diversity and avoid the plateau or overfitting effects. Second, we obtained the scaling laws of CLM and MLM on Transformer, tailored to the specific characteristics of protein sequence data. Third, we observe a transfer scaling phenomenon from CLM to MLM, further demonstrating the effectiveness of transfer through scaling behaviors based on estimated Effectively Transferred Tokens. Finally, to validate our scaling laws, we compare the large-scale versions of ESM-2 and PROGEN2 on downstream tasks, encompassing evaluations of protein generation as well as structure- and function-related tasks, all within less or equivalent pre-training compute budgets.
MSAGPT: Neural Prompting Protein Structure Prediction via MSA Generative Pre-Training
Jun 11, 2024Multiple Sequence Alignment (MSA) plays a pivotal role in unveiling the evolutionary trajectories of protein families. The accuracy of protein structure predictions is often compromised for protein sequences that lack sufficient homologous information to construct high quality MSA. Although various methods have been proposed to generate virtual MSA under these conditions, they fall short in comprehensively capturing the intricate coevolutionary patterns within MSA or require guidance from external oracle models. Here we introduce MSAGPT, a novel approach to prompt protein structure predictions via MSA generative pretraining in the low MSA regime. MSAGPT employs a simple yet effective 2D evolutionary positional encoding scheme to model complex evolutionary patterns. Endowed by this, its flexible 1D MSA decoding framework facilitates zero or few shot learning. Moreover, we demonstrate that leveraging the feedback from AlphaFold2 can further enhance the model capacity via Rejective Fine tuning (RFT) and Reinforcement Learning from AF2 Feedback (RLAF). Extensive experiments confirm the efficacy of MSAGPT in generating faithful virtual MSA to enhance the structure prediction accuracy. The transfer learning capabilities also highlight its great potential for facilitating other protein tasks.
xTrimoPGLM: Unified 100B-Scale Pre-trained Transformer for Deciphering the Language of Protein
Jan 11, 2024Protein language models have shown remarkable success in learning biological information from protein sequences. However, most existing models are limited by either autoencoding or autoregressive pre-training objectives, which makes them struggle to handle protein understanding and generation tasks concurrently. We propose a unified protein language model, xTrimoPGLM, to address these two types of tasks simultaneously through an innovative pre-training framework. Our key technical contribution is an exploration of the compatibility and the potential for joint optimization of the two types of objectives, which has led to a strategy for training xTrimoPGLM at an unprecedented scale of 100 billion parameters and 1 trillion training tokens. Our extensive experiments reveal that 1) xTrimoPGLM significantly outperforms other advanced baselines in 18 protein understanding benchmarks across four categories. The model also facilitates an atomic-resolution view of protein structures, leading to an advanced 3D structural prediction model that surpasses existing language model-based tools. 2) xTrimoPGLM not only can generate de novo protein sequences following the principles of natural ones, but also can perform programmable generation after supervised fine-tuning (SFT) on curated sequences. These results highlight the substantial capability and versatility of xTrimoPGLM in understanding and generating protein sequences, contributing to the evolving landscape of foundation models in protein science.
xTrimoGene: An Efficient and Scalable Representation Learner for Single-Cell RNA-Seq Data
Nov 26, 2023Advances in high-throughput sequencing technology have led to significant progress in measuring gene expressions at the single-cell level. The amount of publicly available single-cell RNA-seq (scRNA-seq) data is already surpassing 50M records for humans with each record measuring 20,000 genes. This highlights the need for unsupervised representation learning to fully ingest these data, yet classical transformer architectures are prohibitive to train on such data in terms of both computation and memory. To address this challenge, we propose a novel asymmetric encoder-decoder transformer for scRNA-seq data, called xTrimoGene$^\alpha$ (or xTrimoGene for short), which leverages the sparse characteristic of the data to scale up the pre-training. This scalable design of xTrimoGene reduces FLOPs by one to two orders of magnitude compared to classical transformers while maintaining high accuracy, enabling us to train the largest transformer models over the largest scRNA-seq dataset today. Our experiments also show that the performance of xTrimoGene improves as we scale up the model sizes, and it also leads to SOTA performance over various downstream tasks, such as cell type annotation, perturb-seq effect prediction, and drug combination prediction. xTrimoGene model is now available for use as a service via the following link: https://api.biomap.com/xTrimoGene/apply.
Won't Get Fooled Again: Answering Questions with False Premises
Jul 05, 2023



Pre-trained language models (PLMs) have shown unprecedented potential in various fields, especially as the backbones for question-answering (QA) systems. However, they tend to be easily deceived by tricky questions such as "How many eyes does the sun have?". Such frailties of PLMs often allude to the lack of knowledge within them. In this paper, we find that the PLMs already possess the knowledge required to rebut such questions, and the key is how to activate the knowledge. To systematize this observation, we investigate the PLMs' responses to one kind of tricky questions, i.e., the false premises questions (FPQs). We annotate a FalseQA dataset containing 2365 human-written FPQs, with the corresponding explanations for the false premises and the revised true premise questions. Using FalseQA, we discover that PLMs are capable of discriminating FPQs by fine-tuning on moderate numbers (e.g., 256) of examples. PLMs also generate reasonable explanations for the false premise, which serve as rebuttals. Further replaying a few general questions during training allows PLMs to excel on FPQs and general questions simultaneously. Our work suggests that once the rebuttal ability is stimulated, knowledge inside the PLMs can be effectively utilized to handle FPQs, which incentivizes the research on PLM-based QA systems.
Revisiting Out-of-distribution Robustness in NLP: Benchmark, Analysis, and LLMs Evaluations
Jun 07, 2023



This paper reexamines the research on out-of-distribution (OOD) robustness in the field of NLP. We find that the distribution shift settings in previous studies commonly lack adequate challenges, hindering the accurate evaluation of OOD robustness. To address these issues, we propose a benchmark construction protocol that ensures clear differentiation and challenging distribution shifts. Then we introduce BOSS, a Benchmark suite for Out-of-distribution robustneSS evaluation covering 5 tasks and 20 datasets. Based on BOSS, we conduct a series of experiments on pre-trained language models for analysis and evaluation of OOD robustness. First, for vanilla fine-tuning, we examine the relationship between in-distribution (ID) and OOD performance. We identify three typical types that unveil the inner learning mechanism, which could potentially facilitate the forecasting of OOD robustness, correlating with the advancements on ID datasets. Then, we evaluate 5 classic methods on BOSS and find that, despite exhibiting some effectiveness in specific cases, they do not offer significant improvement compared to vanilla fine-tuning. Further, we evaluate 5 LLMs with various adaptation paradigms and find that when sufficient ID data is available, fine-tuning domain-specific models outperform LLMs on ID examples significantly. However, in the case of OOD instances, prioritizing LLMs with in-context learning yields better results. We identify that both fine-tuned small models and LLMs face challenges in effectively addressing downstream tasks. The code is public at \url{https://github.com/lifan-yuan/OOD_NLP}.
K-AID: Enhancing Pre-trained Language Models with Domain Knowledge for Question Answering
Sep 22, 2021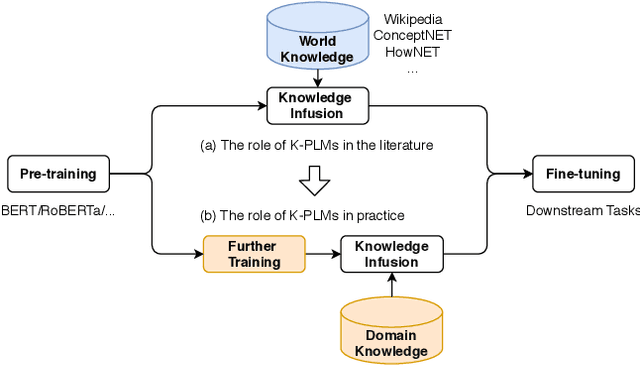

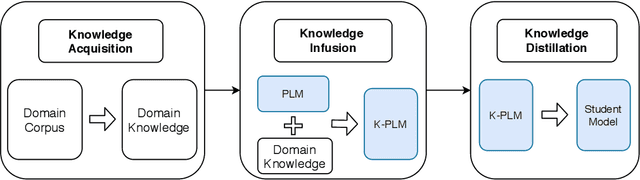
Knowledge enhanced pre-trained language models (K-PLMs) are shown to be effective for many public tasks in the literature but few of them have been successfully applied in practice. To address this problem, we propose K-AID, a systematic approach that includes a low-cost knowledge acquisition process for acquiring domain knowledge, an effective knowledge infusion module for improving model performance, and a knowledge distillation component for reducing the model size and deploying K-PLMs on resource-restricted devices (e.g., CPU) for real-world application. Importantly, instead of capturing entity knowledge like the majority of existing K-PLMs, our approach captures relational knowledge, which contributes to better-improving sentence-level text classification and text matching tasks that play a key role in question answering (QA). We conducted a set of experiments on five text classification tasks and three text matching tasks from three domains, namely E-commerce, Government, and Film&TV, and performed online A/B tests in E-commerce. Experimental results show that our approach is able to achieve substantial improvement on sentence-level question answering tasks and bring beneficial business value in industrial settings.
Dual-View Distilled BERT for Sentence Embedding
Apr 18, 2021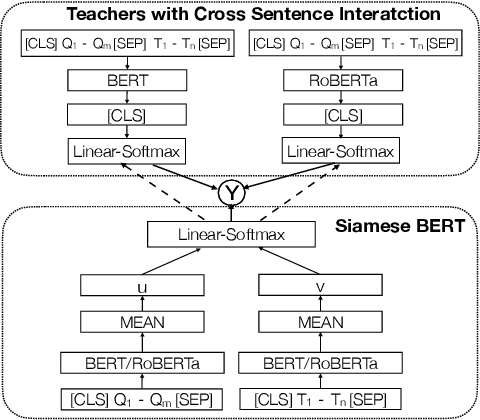
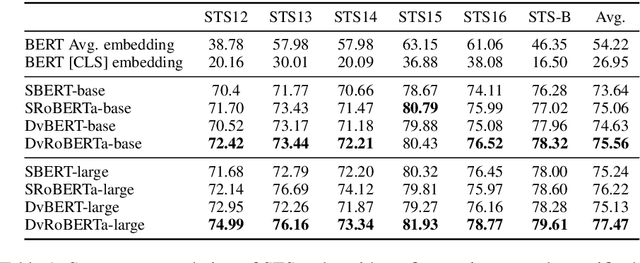
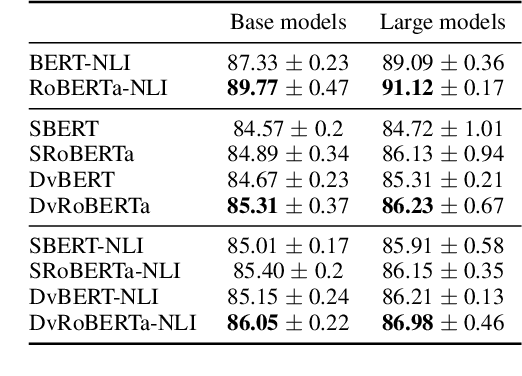
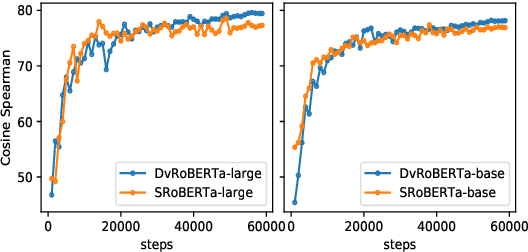
Recently, BERT realized significant progress for sentence matching via word-level cross sentence attention. However, the performance significantly drops when using siamese BERT-networks to derive two sentence embeddings, which fall short in capturing the global semantic since the word-level attention between two sentences is absent. In this paper, we propose a Dual-view distilled BERT~(DvBERT) for sentence matching with sentence embeddings. Our method deals with a sentence pair from two distinct views, i.e., Siamese View and Interaction View. Siamese View is the backbone where we generate sentence embeddings. Interaction View integrates the cross sentence interaction as multiple teachers to boost the representation ability of sentence embeddings. Experiments on six STS tasks show that our method outperforms the state-of-the-art sentence embedding methods significantly.
Question Directed Graph Attention Network for Numerical Reasoning over Text
Sep 16, 2020
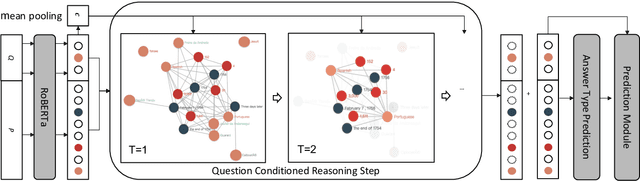
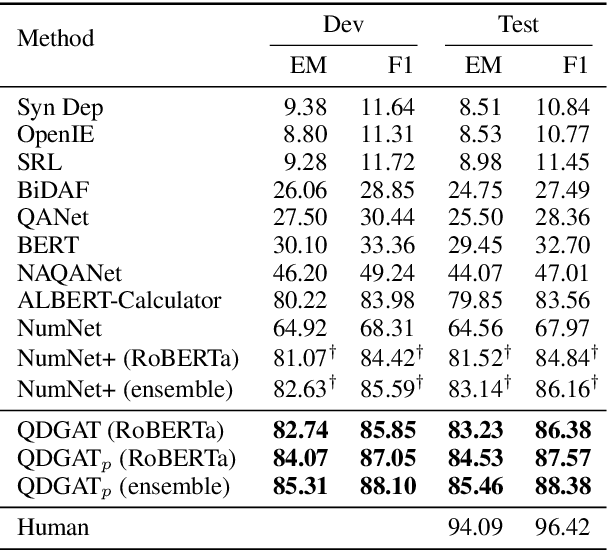
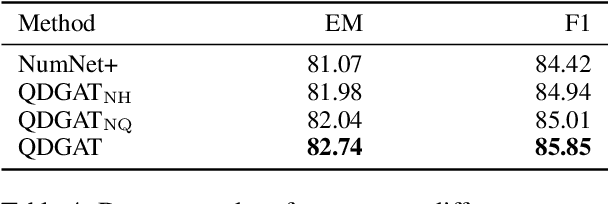
Numerical reasoning over texts, such as addition, subtraction, sorting and counting, is a challenging machine reading comprehension task, since it requires both natural language understanding and arithmetic computation. To address this challenge, we propose a heterogeneous graph representation for the context of the passage and question needed for such reasoning, and design a question directed graph attention network to drive multi-step numerical reasoning over this context graph.