 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedSapiens: Taking a Pose to Rethink Medical Imaging Landmark Detection
Nov 06, 2025This paper does not introduce a novel architecture; instead, it revisits a fundamental yet overlooked baseline: adapting human-centric foundation models for anatomical landmark detection in medical imaging. While landmark detection has traditionally relied on domain-specific models, the emergence of large-scale pre-trained vision models presents new opportunities. In this study, we investigate the adaptation of Sapiens, a human-centric foundation model designed for pose estimation, to medical imaging through multi-dataset pretraining, establishing a new state of the art across multiple datasets. Our proposed model, MedSapiens, demonstrates that human-centric foundation models, inherently optimized for spatial pose localization, provide strong priors for anatomical landmark detection, yet this potential has remained largely untapped. We benchmark MedSapiens against existing state-of-the-art models, achieving up to 5.26% improvement over generalist models and up to 21.81% improvement over specialist models in the average success detection rate (SDR). To further assess MedSapiens adaptability to novel downstream tasks with few annotations, we evaluate its performance in limited-data settings, achieving 2.69% improvement over the few-shot state of the art in SDR. Code and model weights are available at https://github.com/xmed-lab/MedSapiens .
Towards Better Dental AI: A Multimodal Benchmark and Instruction Dataset for Panoramic X-ray Analysis
Sep 11, 2025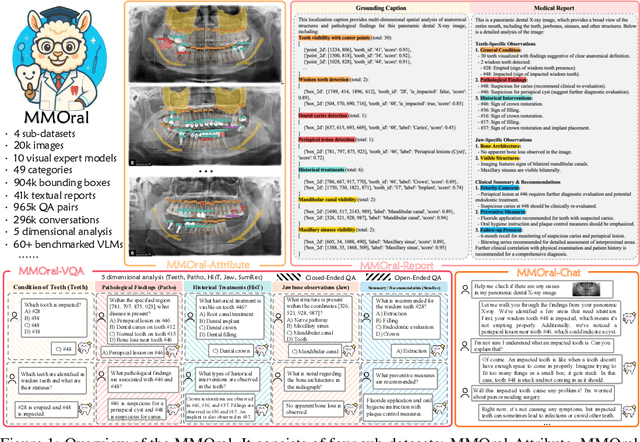
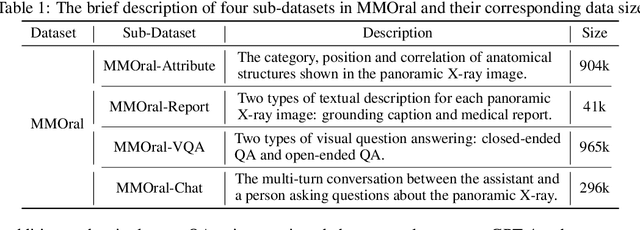
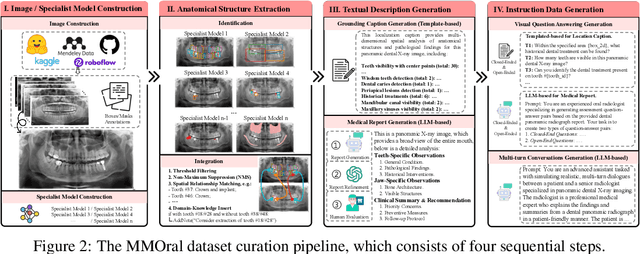
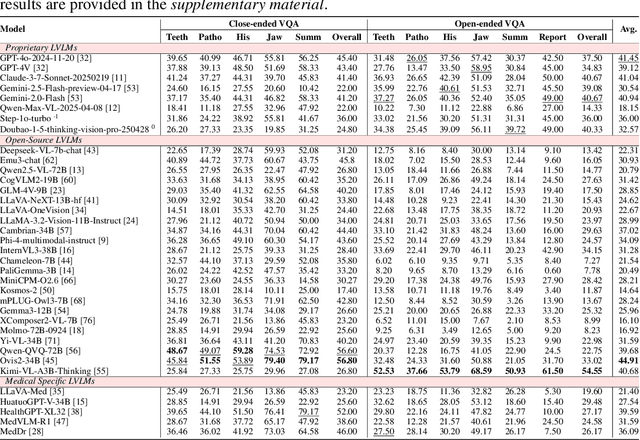
Recent advances in large vision-language models (LVLMs) have demonstrated strong performance on general-purpose medical tasks. However, their effectiveness in specialized domains such as dentistry remains underexplored. In particular, panoramic X-rays, a widely used imaging modality in oral radiology, pose interpretative challenges due to dense anatomical structures and subtle pathological cues, which are not captured by existing medical benchmarks or instruction datasets. To this end, we introduce MMOral, the first large-scale multimodal instruction dataset and benchmark tailored for panoramic X-ray interpretation. MMOral consists of 20,563 annotated images paired with 1.3 million instruction-following instances across diverse task types, including attribute extraction, report generation, visual question answering, and image-grounded dialogue. In addition, we present MMOral-Bench, a comprehensive evaluation suite covering five key diagnostic dimensions in dentistry. We evaluate 64 LVLMs on MMOral-Bench and find that even the best-performing model, i.e., GPT-4o, only achieves 41.45% accuracy, revealing significant limitations of current models in this domain. To promote the progress of this specific domain, we also propose OralGPT, which conducts supervised fine-tuning (SFT) upon Qwen2.5-VL-7B with our meticulously curated MMOral instruction dataset. Remarkably, a single epoch of SFT yields substantial performance enhancements for LVLMs, e.g., OralGPT demonstrates a 24.73% improvement. Both MMOral and OralGPT hold significant potential as a critical foundation for intelligent dentistry and enable more clinically impactful multimodal AI systems in the dental field. The dataset, model, benchmark, and evaluation suite are available at https://github.com/isbrycee/OralGPT.