 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion-Adaptive Learned Hierarchical Encoding for 3D Gaussian Splatting Data
Oct 26, 2025



We introduce Region-Adaptive Learned Hierarchical Encoding (RALHE) for 3D Gaussian Splatting (3DGS) data. While 3DGS has recently become popular for novel view synthesis, the size of trained models limits its deployment in bandwidth-constrained applications such as volumetric media streaming. To address this, we propose a learned hierarchical latent representation that builds upon the principles of "overfitted" learned image compression (e.g., Cool-Chic and C3) to efficiently encode 3DGS attributes. Unlike images, 3DGS data have irregular spatial distributions of Gaussians (geometry) and consist of multiple attributes (signals) defined on the irregular geometry. Our codec is designed to account for these differences between images and 3DGS. Specifically, we leverage the octree structure of the voxelized 3DGS geometry to obtain a hierarchical multi-resolution representation. Our approach overfits latents to each Gaussian attribute under a global rate constraint. These latents are decoded independently through a lightweight decoder network. To estimate the bitrate during training, we employ an autoregressive probability model that leverages octree-derived contexts from the 3D point structure. The multi-resolution latents, decoder, and autoregressive entropy coding networks are jointly optimized for each Gaussian attribute. Experiments demonstrate that the proposed RALHE compression framework achieves a rendering PSNR gain of up to 2dB at low bitrates (less than 1 MB) compared to the baseline 3DGS compression methods.
Generative Distribution Embeddings
May 23, 2025

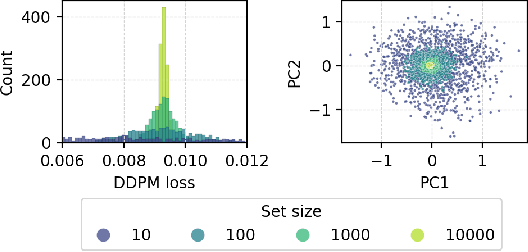
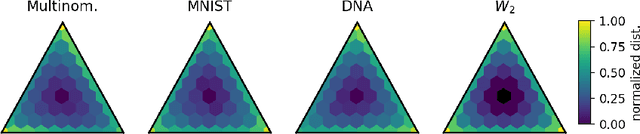
Many real-world problems require reasoning across multiple scales, demanding models which operate not on single data points, but on entire distributions. We introduce generative distribution embeddings (GDE), a framework that lifts autoencoders to the space of distributions. In GDEs, an encoder acts on sets of samples, and the decoder is replaced by a generator which aims to match the input distribution. This framework enables learning representations of distributions by coupling conditional generative models with encoder networks which satisfy a criterion we call distributional invariance. We show that GDEs learn predictive sufficient statistics embedded in the Wasserstein space, such that latent GDE distances approximately recover the $W_2$ distance, and latent interpolation approximately recovers optimal transport trajectories for Gaussian and Gaussian mixture distributions. We systematically benchmark GDEs against existing approaches on synthetic datasets, demonstrating consistently stronger performance. We then apply GDEs to six key problems in computational biology: learning representations of cell populations from lineage-tracing data (150K cells), predicting perturbation effects on single-cell transcriptomes (1M cells), predicting perturbation effects on cellular phenotypes (20M single-cell images), modeling tissue-specific DNA methylation patterns (253M sequences), designing synthetic yeast promoters (34M sequences), and spatiotemporal modeling of viral protein sequences (1M sequences).
GelFusion: Enhancing Robotic Manipulation under Visual Constraints via Visuotactile Fusion
May 12, 2025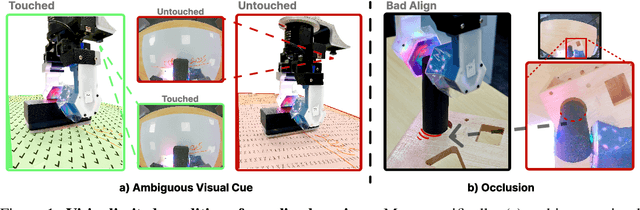



Visuotactile sensing offers rich contact information that can help mitigate performance bottlenecks in imitation learning, particularly under vision-limited conditions, such as ambiguous visual cues or occlusions. Effectively fusing visual and visuotactile modalities, however, presents ongoing challenges. We introduce GelFusion, a framework designed to enhance policies by integrating visuotactile feedback, specifically from high-resolution GelSight sensors. GelFusion using a vision-dominated cross-attention fusion mechanism incorporates visuotactile information into policy learning. To better provide rich contact information, the framework's core component is our dual-channel visuotactile feature representation, simultaneously leveraging both texture-geometric and dynamic interaction features. We evaluated GelFusion on three contact-rich tasks: surface wiping, peg insertion, and fragile object pick-and-place. Outperforming baselines, GelFusion shows the value of its structure in improving the success rate of policy learning.
Standardizing Generative Face Video Compression using Supplemental Enhancement Information
Oct 19, 2024



This paper proposes a Generative Face Video Compression (GFVC) approach using Supplemental Enhancement Information (SEI), where a series of compact spatial and temporal representations of a face video signal (i.e., 2D/3D key-points, facial semantics and compact features) can be coded using SEI message and inserted into the coded video bitstream. At the time of writing, the proposed GFVC approach is an official "technology under consideration" (TuC) for standardization by the Joint Video Experts Team (JVET) of ISO/IEC JVT 1/SC 29 and ITU-T SG16. To the best of the authors' knowledge, the JVET work on the proposed SEI-based GFVC approach is the first standardization activity for generative video compression. The proposed SEI approach has not only advanced the reconstruction quality of early-day Model-Based Coding (MBC) via the state-of-the-art generative technique, but also established a new SEI definition for future GFVC applications and deployment. Experimental results illustrate that the proposed SEI-based GFVC approach can achieve remarkable rate-distortion performance compared with the latest Versatile Video Coding (VVC) standard, whilst also potentially enabling a wide variety of functionalities including user-specified animation/filtering and metaverse-related applications.
Approximating mutual information of high-dimensional variables using learned representations
Sep 03, 2024Mutual information (MI) is a general measure of statistical dependence with widespread application across the sciences. However, estimating MI between multi-dimensional variables is challenging because the number of samples necessary to converge to an accurate estimate scales unfavorably with dimensionality. In practice, existing techniques can reliably estimate MI in up to tens of dimensions, but fail in higher dimensions, where sufficient sample sizes are infeasible. Here, we explore the idea that underlying low-dimensional structure in high-dimensional data can be exploited to faithfully approximate MI in high-dimensional settings with realistic sample sizes. We develop a method that we call latent MI (LMI) approximation, which applies a nonparametric MI estimator to low-dimensional representations learned by a simple, theoretically-motivated model architecture. Using several benchmarks, we show that unlike existing techniques, LMI can approximate MI well for variables with $> 10^3$ dimensions if their dependence structure has low intrinsic dimensionality. Finally, we showcase LMI on two open problems in biology. First, we approximate MI between protein language model (pLM) representations of interacting proteins, and find that pLMs encode non-trivial information about protein-protein interactions. Second, we quantify cell fate information contained in single-cell RNA-seq (scRNA-seq) measurements of hematopoietic stem cells, and find a sharp transition during neutrophil differentiation when fate information captured by scRNA-seq increases dramatically.
LF-3PM: a LiDAR-based Framework for Perception-aware Planning with Perturbation-induced Metric
Aug 03, 2024



Just as humans can become disoriented in featureless deserts or thick fogs, not all environments are conducive to the Localization Accuracy and Stability (LAS) of autonomous robots. This paper introduces an efficient framework designed to enhance LiDAR-based LAS through strategic trajectory generation, known as Perception-aware Planning. Unlike vision-based frameworks, the LiDAR-based requires different considerations due to unique sensor attributes. Our approach focuses on two main aspects: firstly, assessing the impact of LiDAR observations on LAS. We introduce a perturbation-induced metric to provide a comprehensive and reliable evaluation of LiDAR observations. Secondly, we aim to improve motion planning efficiency. By creating a Static Observation Loss Map (SOLM) as an intermediary, we logically separate the time-intensive evaluation and motion planning phases, significantly boosting the planning process. In the experimental section, we demonstrate the effectiveness of the proposed metrics across various scenes and the feature of trajectories guided by different metrics. Ultimately, our framework is tested in a real-world scenario, enabling the robot to actively choose topologies and orientations preferable for localization. The source code is accessible at https://github.com/ZJU-FAST-Lab/LF-3PM.
General Place Recognition Survey: Towards Real-World Autonomy
May 08, 2024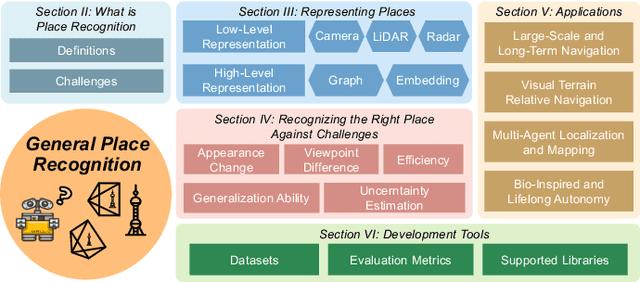
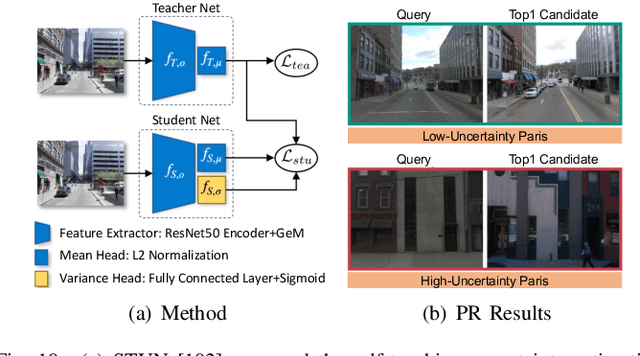
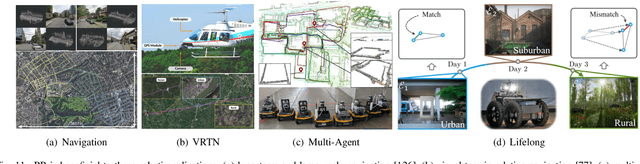
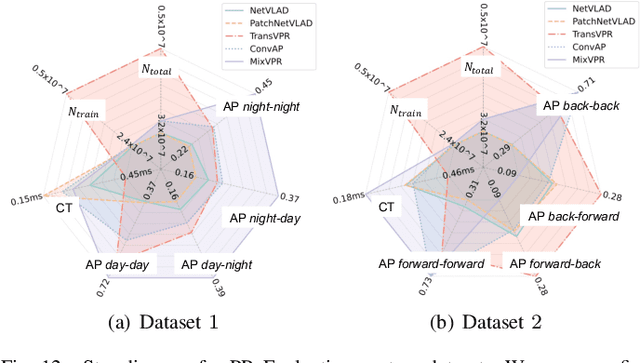
In the realm of robotics, the quest for achieving real-world autonomy, capable of executing large-scale and long-term operations, has positioned place recognition (PR) as a cornerstone technology. Despite the PR community's remarkable strides over the past two decades, garnering attention from fields like computer vision and robotics, the development of PR methods that sufficiently support real-world robotic systems remains a challenge. This paper aims to bridge this gap by highlighting the crucial role of PR within the framework of Simultaneous Localization and Mapping (SLAM) 2.0. This new phase in robotic navigation calls for scalable, adaptable, and efficient PR solutions by integrating advanced artificial intelligence (AI) technologies. For this goal, we provide a comprehensive review of the current state-of-the-art (SOTA) advancements in PR, alongside the remaining challenges, and underscore its broad applications in robotics. This paper begins with an exploration of PR's formulation and key research challenges. We extensively review literature, focusing on related methods on place representation and solutions to various PR challenges. Applications showcasing PR's potential in robotics, key PR datasets, and open-source libraries are discussed. We also emphasizes our open-source package, aimed at new development and benchmark for general PR. We conclude with a discussion on PR's future directions, accompanied by a summary of the literature covered and access to our open-source library, available to the robotics community at: https://github.com/MetaSLAM/GPRS.
360FusionNeRF: Panoramic Neural Radiance Fields with Joint Guidance
Oct 03, 2022
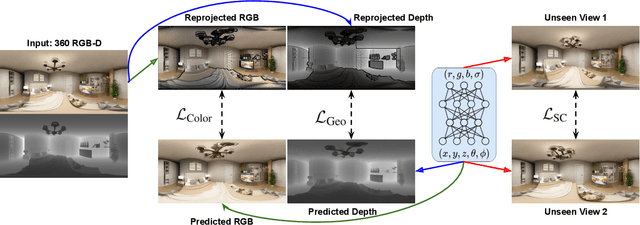

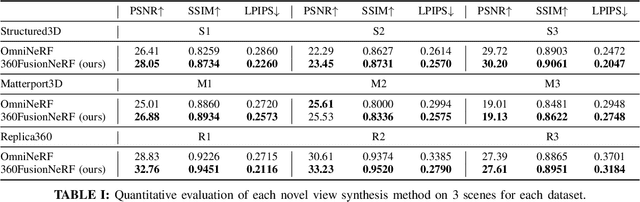
We present a method to synthesize novel views from a single $360^\circ$ panorama image based on the neural radiance field (NeRF). Prior studies in a similar setting rely on the neighborhood interpolation capability of multi-layer perceptions to complete missing regions caused by occlusion, which leads to artifacts in their predictions. We propose 360FusionNeRF, a semi-supervised learning framework where we introduce geometric supervision and semantic consistency to guide the progressive training process. Firstly, the input image is re-projected to $360^\circ$ images, and auxiliary depth maps are extracted at other camera positions. The depth supervision, in addition to the NeRF color guidance, improves the geometry of the synthesized views. Additionally, we introduce a semantic consistency loss that encourages realistic renderings of novel views. We extract these semantic features using a pre-trained visual encoder such as CLIP, a Vision Transformer trained on hundreds of millions of diverse 2D photographs mined from the web with natural language supervision. Experiments indicate that our proposed method can produce plausible completions of unobserved regions while preserving the features of the scene. When trained across various scenes, 360FusionNeRF consistently achieves the state-of-the-art performance when transferring to synthetic Structured3D dataset (PSNR~5%, SSIM~3% LPIPS~13%), real-world Matterport3D dataset (PSNR~3%, SSIM~3% LPIPS~9%) and Replica360 dataset (PSNR~8%, SSIM~2% LPIPS~18%).
MUI-TARE: Multi-Agent Cooperative Exploration with Unknown Initial Position
Sep 22, 2022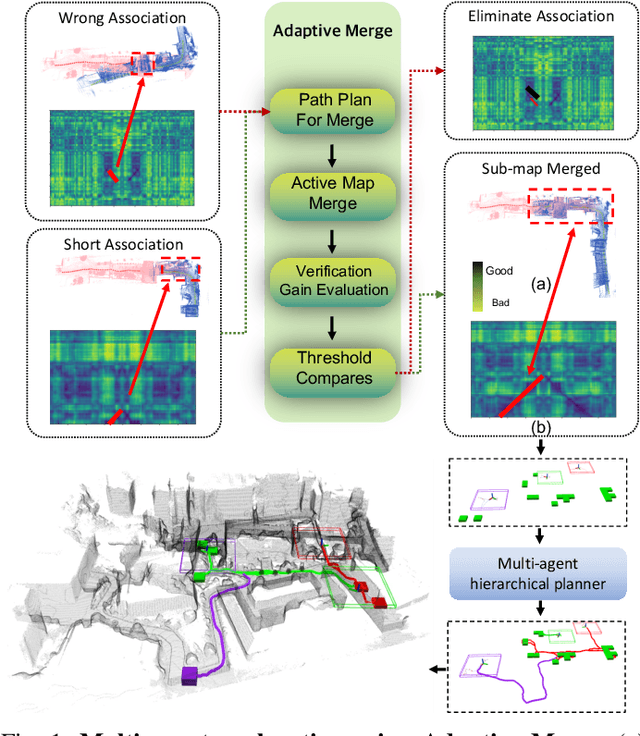
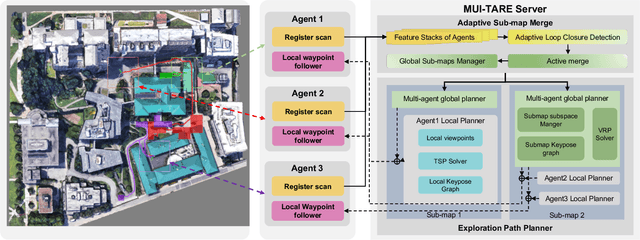
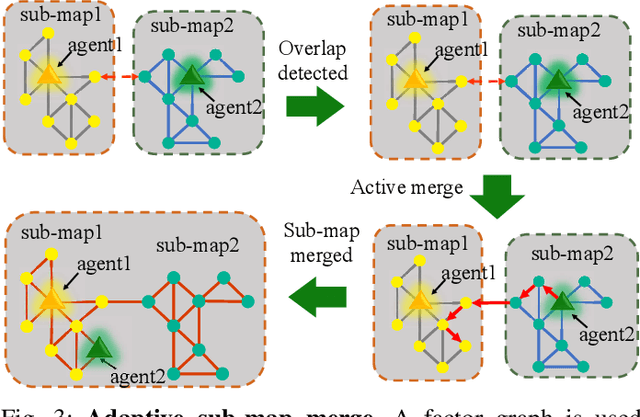
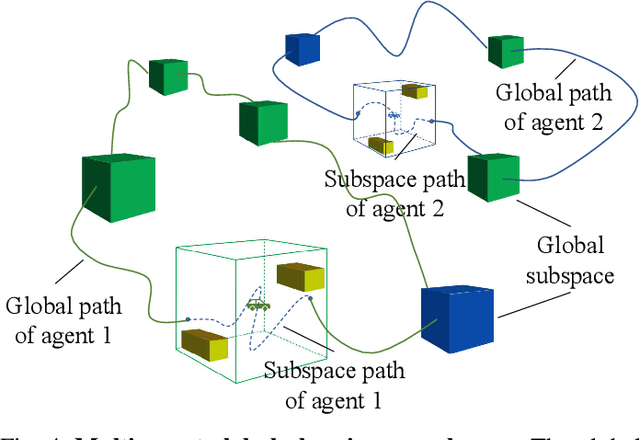
Multi-agent exploration of a bounded 3D environment with unknown initial positions of agents is a challenging problem. It requires quickly exploring the environments as well as robustly merging the sub-maps built by the agents. We take the view that the existing approaches are either aggressive or conservative: Aggressive strategies merge two sub-maps built by different agents together when overlap is detected, which can lead to incorrect merging due to the false-positive detection of the overlap and is thus not robust. Conservative strategies direct one agent to revisit an excessive amount of the historical trajectory of another agent for verification before merging, which can lower the exploration efficiency due to the repeated exploration of the same space. To intelligently balance the robustness of sub-map merging and exploration efficiency, we develop a new approach for lidar-based multi-agent exploration, which can direct one agent to repeat another agent's trajectory in an \emph{adaptive} manner based on the quality indicator of the sub-map merging process. Additionally, our approach extends the recent single-agent hierarchical exploration strategy to multiple agents in a \emph{cooperative} manner by planning for agents with merged sub-maps together to further improve exploration efficiency. Our experiments show that our approach is up to 50\% more efficient than the baselines on average while merging sub-maps robustly.
iSimLoc: Visual Global Localization for Previously Unseen Environments with Simulated Images
Sep 14, 2022


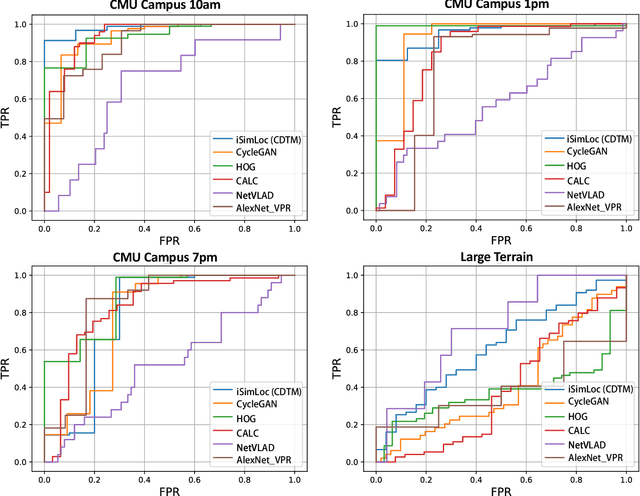
The visual camera is an attractive device in beyond visual line of sight (B-VLOS) drone operation, since they are low in size, weight, power, and cost, and can provide redundant modality to GPS failures. However, state-of-the-art visual localization algorithms are unable to match visual data that have a significantly different appearance due to illuminations or viewpoints. This paper presents iSimLoc, a condition/viewpoint consistent hierarchical global re-localization approach. The place features of iSimLoc can be utilized to search target images under changing appearances and viewpoints. Additionally, our hierarchical global re-localization module refines in a coarse-to-fine manner, allowing iSimLoc to perform a fast and accurate estimation. We evaluate our method on one dataset with appearance variations and one dataset that focuses on demonstrating large-scale matching over a long flight in complicated environments. On our two datasets, iSimLoc achieves 88.7\% and 83.8\% successful retrieval rates with 1.5s inferencing time, compared to 45.8% and 39.7% using the next best method. These results demonstrate robust localization in a range of environments.