 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Better Dental AI: A Multimodal Benchmark and Instruction Dataset for Panoramic X-ray Analysis
Sep 11, 2025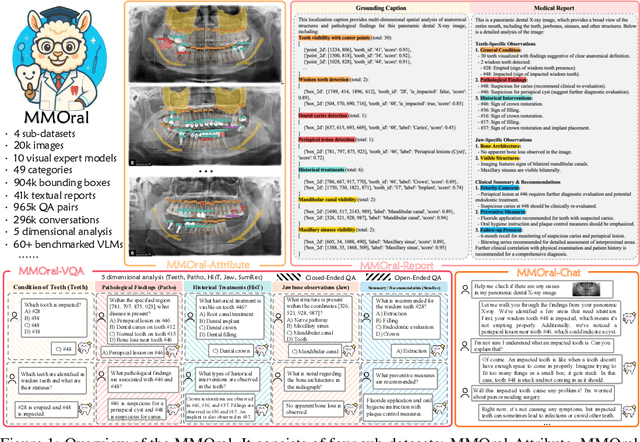
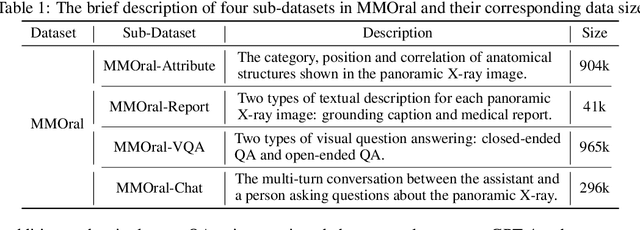
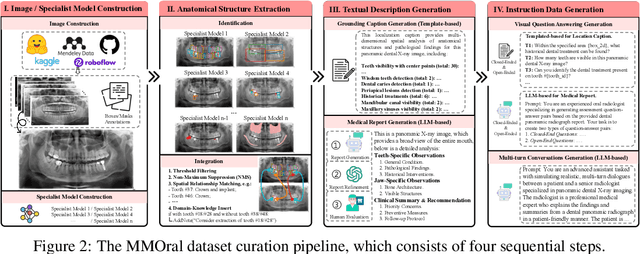
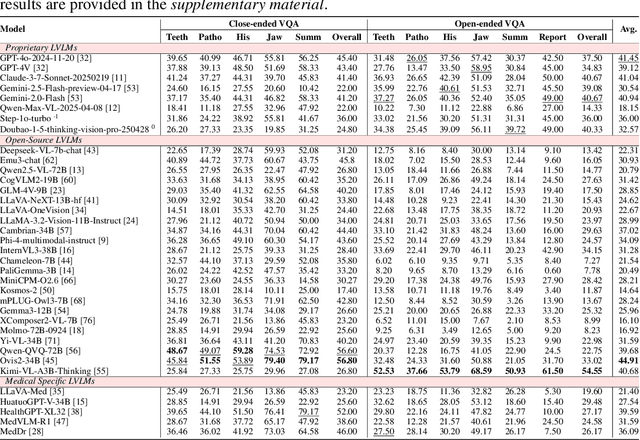
Recent advances in large vision-language models (LVLMs) have demonstrated strong performance on general-purpose medical tasks. However, their effectiveness in specialized domains such as dentistry remains underexplored. In particular, panoramic X-rays, a widely used imaging modality in oral radiology, pose interpretative challenges due to dense anatomical structures and subtle pathological cues, which are not captured by existing medical benchmarks or instruction datasets. To this end, we introduce MMOral, the first large-scale multimodal instruction dataset and benchmark tailored for panoramic X-ray interpretation. MMOral consists of 20,563 annotated images paired with 1.3 million instruction-following instances across diverse task types, including attribute extraction, report generation, visual question answering, and image-grounded dialogue. In addition, we present MMOral-Bench, a comprehensive evaluation suite covering five key diagnostic dimensions in dentistry. We evaluate 64 LVLMs on MMOral-Bench and find that even the best-performing model, i.e., GPT-4o, only achieves 41.45% accuracy, revealing significant limitations of current models in this domain. To promote the progress of this specific domain, we also propose OralGPT, which conducts supervised fine-tuning (SFT) upon Qwen2.5-VL-7B with our meticulously curated MMOral instruction dataset. Remarkably, a single epoch of SFT yields substantial performance enhancements for LVLMs, e.g., OralGPT demonstrates a 24.73% improvement. Both MMOral and OralGPT hold significant potential as a critical foundation for intelligent dentistry and enable more clinically impactful multimodal AI systems in the dental field. The dataset, model, benchmark, and evaluation suite are available at https://github.com/isbrycee/OralGPT.
T-Mamba: Frequency-Enhanced Gated Long-Range Dependency for Tooth 3D CBCT Segmentation
Apr 01, 2024Efficient tooth segmentation in three-dimensional (3D) imaging, critical for orthodontic diagnosis, remains challenging due to noise, low contrast, and artifacts in CBCT images. Both convolutional Neural Networks (CNNs) and transformers have emerged as popular architectures for image segmentation. However, their efficacy in handling long-range dependencies is limited due to inherent locality or computational complexity. To address this issue, we propose T-Mamba, integrating shared positional encoding and frequency-based features into vision mamba, to address limitations in spatial position preservation and feature enhancement in frequency domain. Besides, we also design a gate selection unit to integrate two features in spatial domain and one feature in frequency domain adaptively. T-Mamba is the first work to introduce frequency-based features into vision mamba. Extensive experiments demonstrate that T-Mamba achieves new SOTA results on the public Tooth CBCT dataset and outperforms previous SOTA methods by a large margin, i.e., IoU + 3.63%, SO + 2.43%, DSC +2.30%, HD -4.39mm, and ASSD -0.37mm. The code and models are publicly available at https://github.com/isbrycee/T-Mamba.
GEM: Boost Simple Network for Glass Surface Segmentation via Segment Anything Model and Data Synthesis
Jan 27, 2024Detecting glass regions is a challenging task due to the ambiguity of their transparency and reflection properties. These transparent glasses share the visual appearance of both transmitted arbitrary background scenes and reflected objects, thus having no fixed patterns.Recent visual foundation models, which are trained on vast amounts of data, have manifested stunning performance in terms of image perception and image generation. To segment glass surfaces with higher accuracy, we make full use of two visual foundation models: Segment Anything (SAM) and Stable Diffusion.Specifically, we devise a simple glass surface segmentor named GEM, which only consists of a SAM backbone, a simple feature pyramid, a discerning query selection module, and a mask decoder. The discerning query selection can adaptively identify glass surface features, assigning them as initialized queries in the mask decoder. We also propose a Synthetic but photorealistic large-scale Glass Surface Detection dataset dubbed S-GSD via diffusion model with four different scales, which contain 1x, 5x, 10x, and 20x of the original real data size. This dataset is a feasible source for transfer learning. The scale of synthetic data has positive impacts on transfer learning, while the improvement will gradually saturate as the amount of data increases. Extensive experiments demonstrate that GEM achieves a new state-of-the-art on the GSD-S validation set (IoU +2.1%). Codes and datasets are available at: https://github.com/isbrycee/GEM-Glass-Segmentor.