 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Pre-training with Symmetric Superimposition Modeling for Scene Text Recognition
May 11, 2024



In text recognition, self-supervised pre-training emerges as a good solution to reduce dependence on expansive annotated real data. Previous studies primarily focus on local visual representation by leveraging mask image modeling or sequence contrastive learning. However, they omit modeling the linguistic information in text images, which is crucial for recognizing text. To simultaneously capture local character features and linguistic information in visual space, we propose Symmetric Superimposition Modeling (SSM). The objective of SSM is to reconstruct the direction-specific pixel and feature signals from the symmetrically superimposed input. Specifically, we add the original image with its inverted views to create the symmetrically superimposed inputs. At the pixel level, we reconstruct the original and inverted images to capture character shapes and texture-level linguistic context. At the feature level, we reconstruct the feature of the same original image and inverted image with different augmentations to model the semantic-level linguistic context and the local character discrimination. In our design, we disrupt the character shape and linguistic rules. Consequently, the dual-level reconstruction facilitates understanding character shapes and linguistic information from the perspective of visual texture and feature semantics. Experiments on various text recognition benchmarks demonstrate the effectiveness and generality of SSM, with 4.1% average performance gains and 86.6% new state-of-the-art average word accuracy on Union14M benchmarks. The code is available at https://github.com/FaltingsA/SSM.
Choose What You Need: Disentangled Representation Learning for Scene Text Recognition, Removal and Editing
May 07, 2024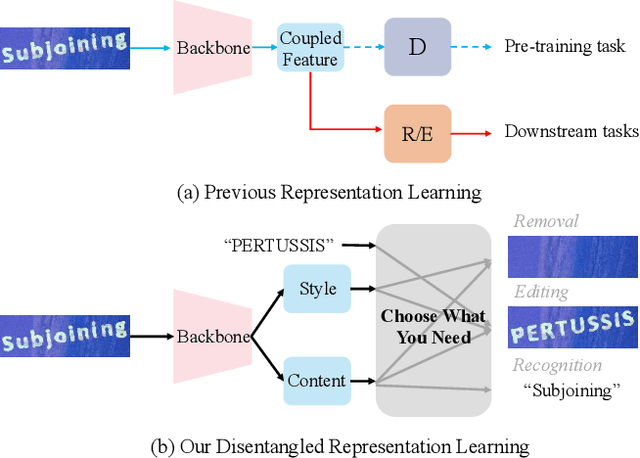
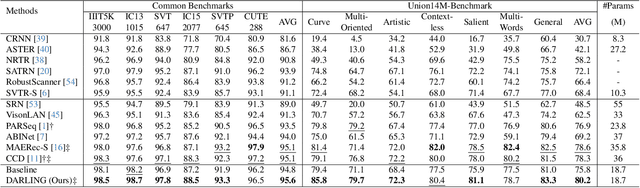
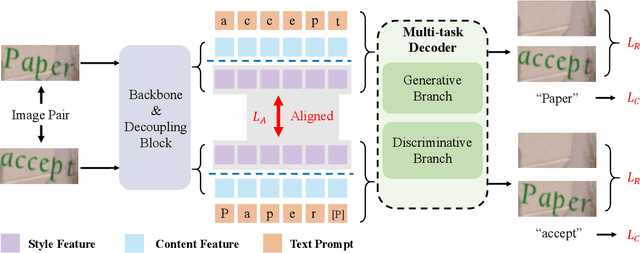
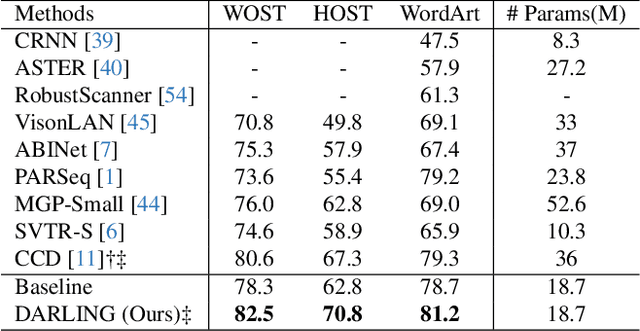
Scene text images contain not only style information (font, background) but also content information (character, texture). Different scene text tasks need different information, but previous representation learning methods use tightly coupled features for all tasks, resulting in sub-optimal performance. We propose a Disentangled Representation Learning framework (DARLING) aimed at disentangling these two types of features for improved adaptability in better addressing various downstream tasks (choose what you really need). Specifically, we synthesize a dataset of image pairs with identical style but different content. Based on the dataset, we decouple the two types of features by the supervision design. Clearly, we directly split the visual representation into style and content features, the content features are supervised by a text recognition loss, while an alignment loss aligns the style features in the image pairs. Then, style features are employed in reconstructing the counterpart image via an image decoder with a prompt that indicates the counterpart's content. Such an operation effectively decouples the features based on their distinctive properties. To the best of our knowledge, this is the first time in the field of scene text that disentangles the inherent properties of the text images. Our method achieves state-of-the-art performance in Scene Text Recognition, Removal, and Editing.
GScream: Learning 3D Geometry and Feature Consistent Gaussian Splatting for Object Removal
Apr 21, 2024This paper tackles the intricate challenge of object removal to update the radiance field using the 3D Gaussian Splatting. The main challenges of this task lie in the preservation of geometric consistency and the maintenance of texture coherence in the presence of the substantial discrete nature of Gaussian primitives. We introduce a robust framework specifically designed to overcome these obstacles. The key insight of our approach is the enhancement of information exchange among visible and invisible areas, facilitating content restoration in terms of both geometry and texture. Our methodology begins with optimizing the positioning of Gaussian primitives to improve geometric consistency across both removed and visible areas, guided by an online registration process informed by monocular depth estimation. Following this, we employ a novel feature propagation mechanism to bolster texture coherence, leveraging a cross-attention design that bridges sampling Gaussians from both uncertain and certain areas. This innovative approach significantly refines the texture coherence within the final radiance field. Extensive experiments validate that our method not only elevates the quality of novel view synthesis for scenes undergoing object removal but also showcases notable efficiency gains in training and rendering speeds.
A Survey on Game Playing Agents and Large Models: Methods, Applications, and Challenges
Mar 15, 2024The swift evolution of Large-scale Models (LMs), either language-focused or multi-modal, has garnered extensive attention in both academy and industry. But despite the surge in interest in this rapidly evolving area, there are scarce systematic reviews on their capabilities and potential in distinct impactful scenarios. This paper endeavours to help bridge this gap, offering a thorough examination of the current landscape of LM usage in regards to complex game playing scenarios and the challenges still open. Here, we seek to systematically review the existing architectures of LM-based Agents (LMAs) for games and summarize their commonalities, challenges, and any other insights. Furthermore, we present our perspective on promising future research avenues for the advancement of LMs in games. We hope to assist researchers in gaining a clear understanding of the field and to generate more interest in this highly impactful research direction. A corresponding resource, continuously updated, can be found in our GitHub repository.
Mixer is more than just a model
Mar 02, 2024Recently, MLP structures have regained popularity, with MLP-Mixer standing out as a prominent example. In the field of computer vision, MLP-Mixer is noted for its ability to extract data information from both channel and token perspectives, effectively acting as a fusion of channel and token information. Indeed, Mixer represents a paradigm for information extraction that amalgamates channel and token information. The essence of Mixer lies in its ability to blend information from diverse perspectives, epitomizing the true concept of "mixing" in the realm of neural network architectures. Beyond channel and token considerations, it is possible to create more tailored mixers from various perspectives to better suit specific task requirements. This study focuses on the domain of audio recognition, introducing a novel model named Audio Spectrogram Mixer with Roll-Time and Hermit FFT (ASM-RH) that incorporates insights from both time and frequency domains. Experimental results demonstrate that ASM-RH is particularly well-suited for audio data and yields promising outcomes across multiple classification tasks. The models and optimal weights files will be published.
Networked Collaborative Sensing using Multi-domain Measurements: Architectures, Performance Limits and Algorithms
Feb 23, 2024



As a promising 6G technology, integrated sensing and communication (ISAC) gains growing interest. ISAC provides integration gain via sharing spectrum, hardware, and software. However, concerns exist regarding its sensing performance when compared to dedicated radar systems. To address this issue, the advantages of widely deployed networks should be utilized, and this paper proposes networked collaborative sensing (NCS) using multi-domain measurements (MM), including range, Doppler, and two-dimension angle of arrival. In the NCS-MM architecture, this paper proposes a novel multi-domain decoupling model and a novel guard band-based protocol. The proposed model simplifies multi-domain derivations and algorithm designs, and the proposed protocol conserves resources and mitigates NCS interference. To determine the performance limits, this paper derives the Cram\'er-Rao lower bound (CRLB) of three-dimension position and velocity in NCS-MM. An accumulated single-dimension channel model is used to obtain the CRLB of MM, which is proven to be equivalent to that of the multi-dimension model. The algorithms of both MM estimation and fusion are proposed. An arbitrary-dimension Newtonized orthogonal matched pursuit (AD-NOMP) is proposed to accurately estimate grid-less MM. The degree-of-freedom (DoF) of MM is analyzed, and a novel DoF-based two-stage weighted least squares (TSWLS) is proposed to reduce equations without DoF loss. The numerical results show that the performances of the proposed algorithms are close to their performance limits.
Angle Robustness Unmanned Aerial Vehicle Navigation in GNSS-Denied Scenarios
Feb 04, 2024



Due to the inability to receive signals from the Global Navigation Satellite System (GNSS) in extreme conditions, achieving accurate and robust navigation for Unmanned Aerial Vehicles (UAVs) is a challenging task. Recently emerged, vision-based navigation has been a promising and feasible alternative to GNSS-based navigation. However, existing vision-based techniques are inadequate in addressing flight deviation caused by environmental disturbances and inaccurate position predictions in practical settings. In this paper, we present a novel angle robustness navigation paradigm to deal with flight deviation in point-to-point navigation tasks. Additionally, we propose a model that includes the Adaptive Feature Enhance Module, Cross-knowledge Attention-guided Module and Robust Task-oriented Head Module to accurately predict direction angles for high-precision navigation. To evaluate the vision-based navigation methods, we collect a new dataset termed as UAV_AR368. Furthermore, we design the Simulation Flight Testing Instrument (SFTI) using Google Earth to simulate different flight environments, thereby reducing the expenses associated with real flight testing. Experiment results demonstrate that the proposed model outperforms the state-of-the-art by achieving improvements of 26.0% and 45.6% in the success rate of arrival under ideal and disturbed circumstances, respectively.
ASM: Audio Spectrogram Mixer
Jan 20, 2024Transformer structures have demonstrated outstanding skills in the deep learning space recently, significantly increasing the accuracy of models across a variety of domains. Researchers have started to question whether such a sophisticated network structure is actually necessary and whether equally outstanding results can be reached with reduced inference cost due to its complicated network topology and high inference cost. In order to prove the Mixer's efficacy on three datasets Speech Commands, UrbanSound8k, and CASIA Chinese Sentiment Corpus this paper applies amore condensed version of the Mixer to an audio classification task and conducts comparative experiments with the Transformer-based Audio Spectrogram Transformer (AST)model. In addition, this paper conducts comparative experiments on the application of several activation functions in Mixer, namely GeLU, Mish, Swish and Acon-C. Further-more, the use of various activation functions in Mixer, including GeLU, Mish, Swish, and Acon-C, is compared in this research through comparison experiments. Additionally, some AST model flaws are highlighted, and the model suggested in this study is improved as a result. In conclusion, a model called the Audio Spectrogram Mixer, which is the first model for audio classification with Mixer, is suggested in this study and the model's future directions for improvement are examined.
Sample-based Dynamic Hierarchical Transformer with Layer and Head Flexibility via Contextual Bandit
Dec 12, 2023Transformer requires a fixed number of layers and heads which makes them inflexible to the complexity of individual samples and expensive in training and inference. To address this, we propose a sample-based Dynamic Hierarchical Transformer (DHT) model whose layers and heads can be dynamically configured with single data samples via solving contextual bandit problems. To determine the number of layers and heads, we use the Uniform Confidence Bound while we deploy combinatorial Thompson Sampling in order to select specific head combinations given their number. Different from previous work that focuses on compressing trained networks for inference only, DHT is not only advantageous for adaptively optimizing the underlying network architecture during training but also has a flexible network for efficient inference. To the best of our knowledge, this is the first comprehensive data-driven dynamic transformer without any additional auxiliary neural networks that implement the dynamic system. According to the experiment results, we achieve up to 74% computational savings for both training and inference with a minimal loss of accuracy.
FedEmb: A Vertical and Hybrid Federated Learning Algorithm using Network And Feature Embedding Aggregation
Dec 04, 2023



Federated learning (FL) is an emerging paradigm for decentralized training of machine learning models on distributed clients, without revealing the data to the central server. The learning scheme may be horizontal, vertical or hybrid (both vertical and horizontal). Most existing research work with deep neural network (DNN) modelling is focused on horizontal data distributions, while vertical and hybrid schemes are much less studied. In this paper, we propose a generalized algorithm FedEmb, for modelling vertical and hybrid DNN-based learning. The idea of our algorithm is characterised by higher inference accuracy, stronger privacy-preserving properties, and lower client-server communication bandwidth demands as compared with existing work. The experimental results show that FedEmb is an effective method to tackle both split feature & subject space decentralized problems, shows 0.3% to 4.2% inference accuracy improvement with limited privacy revealing for datasets stored in local clients, and reduces 88.9 % time complexity over vertical baseline method.
* Accepted by Proceedings on Engineering Sciences