 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing is Improving: Visual Feedback for Iterative Text Layout Refinement
Mar 23, 2026Recent advances in Multimodal Large Language Models (MLLMs) have enabled automated generation of structured layouts from natural language descriptions. Existing methods typically follow a code-only paradigm that generates code to represent layouts, which are then rendered by graphic engines to produce final images. However, they are blind to the rendered visual outcome, making it difficult to guarantee readability and aesthetics. In this paper, we identify visual feedback as a critical factor in layout generation and propose Visual Feedback Layout Model (VFLM), a self-improving framework that leverages visual feedback iterative refinement. VFLM is capable of performing adaptive reflective generation, which leverages visual information to reflect on previous issues and iteratively generates outputs until satisfactory quality is achieved. It is achieved through reinforcement learning with a visually grounded reward model that incorporates OCR accuracy. By rewarding only the final generated outcome, we can effectively stimulate the model's iterative and reflective generative capabilities. Experiments across multiple benchmarks show that VFLM consistently outperforms advanced MLLMs, existing layout models, and code-only baselines, establishing visual feedback as critical for design-oriented MLLMs. Our code and data are available at https://github.com/FolSpark/VFLM.
Mask$^2$DiT: Dual Mask-based Diffusion Transformer for Multi-Scene Long Video Generation
Mar 25, 2025



Sora has unveiled the immense potential of the Diffusion Transformer (DiT) architecture in single-scene video generation. However, the more challenging task of multi-scene video generation, which offers broader applications, remains relatively underexplored. To bridge this gap, we propose Mask$^2$DiT, a novel approach that establishes fine-grained, one-to-one alignment between video segments and their corresponding text annotations. Specifically, we introduce a symmetric binary mask at each attention layer within the DiT architecture, ensuring that each text annotation applies exclusively to its respective video segment while preserving temporal coherence across visual tokens. This attention mechanism enables precise segment-level textual-to-visual alignment, allowing the DiT architecture to effectively handle video generation tasks with a fixed number of scenes. To further equip the DiT architecture with the ability to generate additional scenes based on existing ones, we incorporate a segment-level conditional mask, which conditions each newly generated segment on the preceding video segments, thereby enabling auto-regressive scene extension. Both qualitative and quantitative experiments confirm that Mask$^2$DiT excels in maintaining visual consistency across segments while ensuring semantic alignment between each segment and its corresponding text description. Our project page is https://tianhao-qi.github.io/Mask2DiTProject.
A Graph-Based Synthetic Data Pipeline for Scaling High-Quality Reasoning Instructions
Dec 12, 2024



Synthesizing high-quality reasoning data for continual training has been proven to be effective in enhancing the performance of Large Language Models (LLMs). However, previous synthetic approaches struggle to easily scale up data and incur high costs in the pursuit of high quality. In this paper, we propose the Graph-based Synthetic Data Pipeline (GSDP), an economical and scalable framework for high-quality reasoning data synthesis. Inspired by knowledge graphs, we extracted knowledge points from seed data and constructed a knowledge point relationships graph to explore their interconnections. By exploring the implicit relationships among knowledge, our method achieves $\times$255 data expansion. Furthermore, GSDP led by open-source models, achieves synthesis quality comparable to GPT-4-0613 while maintaining $\times$100 lower costs. To tackle the most challenging mathematical reasoning task, we present the GSDP-MATH dataset comprising over 1.91 million pairs of math problems and answers. After fine-tuning on GSDP-MATH, GSDP-7B based on Mistral-7B achieves 37.7% accuracy on MATH and 78.4% on GSM8K, demonstrating the effectiveness of our method. The dataset and models trained in this paper will be available.
Sentiment-oriented Transformer-based Variational Autoencoder Network for Live Video Commenting
Apr 19, 2024



Automatic live video commenting is with increasing attention due to its significance in narration generation, topic explanation, etc. However, the diverse sentiment consideration of the generated comments is missing from the current methods. Sentimental factors are critical in interactive commenting, and lack of research so far. Thus, in this paper, we propose a Sentiment-oriented Transformer-based Variational Autoencoder (So-TVAE) network which consists of a sentiment-oriented diversity encoder module and a batch attention module, to achieve diverse video commenting with multiple sentiments and multiple semantics. Specifically, our sentiment-oriented diversity encoder elegantly combines VAE and random mask mechanism to achieve semantic diversity under sentiment guidance, which is then fused with cross-modal features to generate live video comments. Furthermore, a batch attention module is also proposed in this paper to alleviate the problem of missing sentimental samples, caused by the data imbalance, which is common in live videos as the popularity of videos varies. Extensive experiments on Livebot and VideoIC datasets demonstrate that the proposed So-TVAE outperforms the state-of-the-art methods in terms of the quality and diversity of generated comments. Related code is available at https://github.com/fufy1024/So-TVAE.
DEADiff: An Efficient Stylization Diffusion Model with Disentangled Representations
Mar 12, 2024



The diffusion-based text-to-image model harbors immense potential in transferring reference style. However, current encoder-based approaches significantly impair the text controllability of text-to-image models while transferring styles. In this paper, we introduce DEADiff to address this issue using the following two strategies: 1) a mechanism to decouple the style and semantics of reference images. The decoupled feature representations are first extracted by Q-Formers which are instructed by different text descriptions. Then they are injected into mutually exclusive subsets of cross-attention layers for better disentanglement. 2) A non-reconstructive learning method. The Q-Formers are trained using paired images rather than the identical target, in which the reference image and the ground-truth image are with the same style or semantics. We show that DEADiff attains the best visual stylization results and optimal balance between the text controllability inherent in the text-to-image model and style similarity to the reference image, as demonstrated both quantitatively and qualitatively. Our project page is https://tianhao-qi.github.io/DEADiff/.
DreamIdentity: Improved Editability for Efficient Face-identity Preserved Image Generation
Jul 01, 2023While large-scale pre-trained text-to-image models can synthesize diverse and high-quality human-centric images, an intractable problem is how to preserve the face identity for conditioned face images. Existing methods either require time-consuming optimization for each face-identity or learning an efficient encoder at the cost of harming the editability of models. In this work, we present an optimization-free method for each face identity, meanwhile keeping the editability for text-to-image models. Specifically, we propose a novel face-identity encoder to learn an accurate representation of human faces, which applies multi-scale face features followed by a multi-embedding projector to directly generate the pseudo words in the text embedding space. Besides, we propose self-augmented editability learning to enhance the editability of models, which is achieved by constructing paired generated face and edited face images using celebrity names, aiming at transferring mature ability of off-the-shelf text-to-image models in celebrity faces to unseen faces. Extensive experiments show that our methods can generate identity-preserved images under different scenes at a much faster speed.
Design Booster: A Text-Guided Diffusion Model for Image Translation with Spatial Layout Preservation
Feb 05, 2023



Diffusion models are able to generate photorealistic images in arbitrary scenes. However, when applying diffusion models to image translation, there exists a trade-off between maintaining spatial structure and high-quality content. Besides, existing methods are mainly based on test-time optimization or fine-tuning model for each input image, which are extremely time-consuming for practical applications. To address these issues, we propose a new approach for flexible image translation by learning a layout-aware image condition together with a text condition. Specifically, our method co-encodes images and text into a new domain during the training phase. In the inference stage, we can choose images/text or both as the conditions for each time step, which gives users more flexible control over layout and content. Experimental comparisons of our method with state-of-the-art methods demonstrate our model performs best in both style image translation and semantic image translation and took the shortest time.
ABINet++: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Spotting
Dec 12, 2022Scene text spotting is of great importance to the computer vision community due to its wide variety of applications. Recent methods attempt to introduce linguistic knowledge for challenging recognition rather than pure visual classification. However, how to effectively model the linguistic rules in end-to-end deep networks remains a research challenge. In this paper, we argue that the limited capacity of language models comes from 1) implicit language modeling; 2) unidirectional feature representation; and 3) language model with noise input. Correspondingly, we propose an autonomous, bidirectional and iterative ABINet++ for scene text spotting. Firstly, the autonomous suggests enforcing explicitly language modeling by decoupling the recognizer into vision model and language model and blocking gradient flow between both models. Secondly, a novel bidirectional cloze network (BCN) as the language model is proposed based on bidirectional feature representation. Thirdly, we propose an execution manner of iterative correction for the language model which can effectively alleviate the impact of noise input. Finally, to polish ABINet++ in long text recognition, we propose to aggregate horizontal features by embedding Transformer units inside a U-Net, and design a position and content attention module which integrates character order and content to attend to character features precisely. ABINet++ achieves state-of-the-art performance on both scene text recognition and scene text spotting benchmarks, which consistently demonstrates the superiority of our method in various environments especially on low-quality images. Besides, extensive experiments including in English and Chinese also prove that, a text spotter that incorporates our language modeling method can significantly improve its performance both in accuracy and speed compared with commonly used attention-based recognizers.
CDistNet: Perceiving Multi-Domain Character Distance for Robust Text Recognition
Nov 25, 2021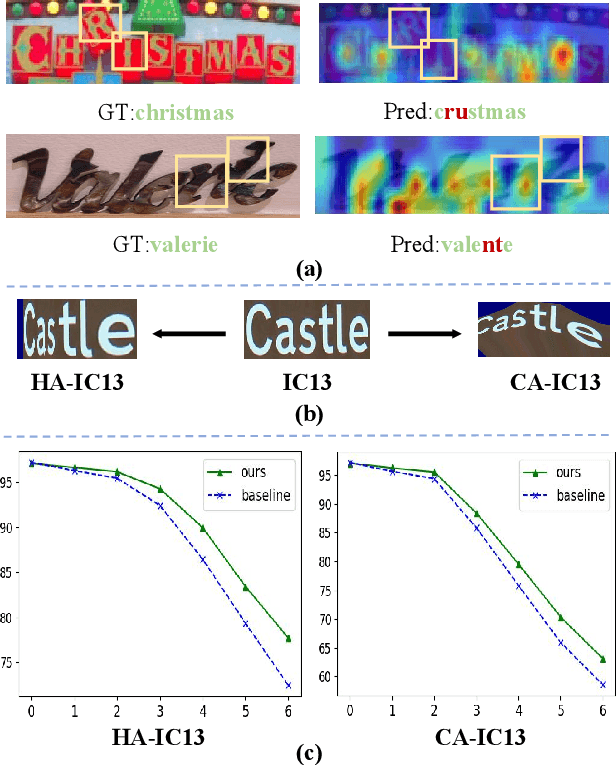
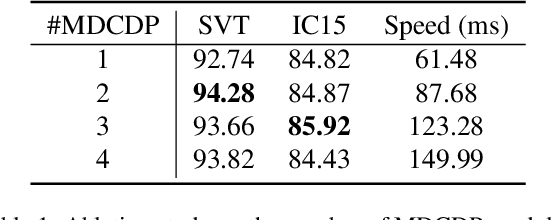
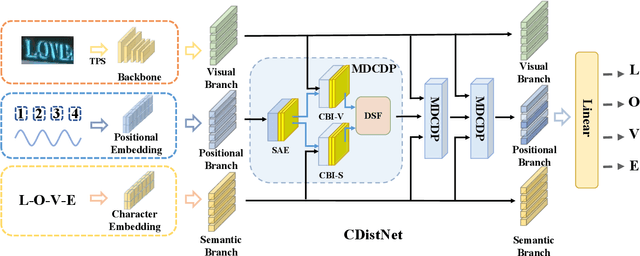
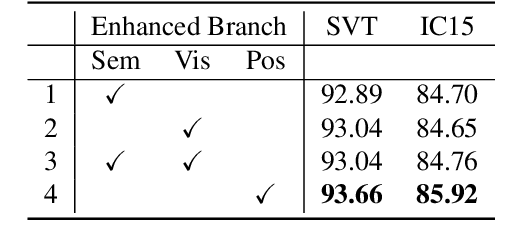
The attention-based encoder-decoder framework is becoming popular in scene text recognition, largely due to its superiority in integrating recognition clues from both visual and semantic domains. However, recent studies show the two clues might be misaligned in the difficult text (e.g., with rare text shapes) and introduce constraints such as character position to alleviate the problem. Despite certain success, a content-free positional embedding hardly associates with meaningful local image regions stably. In this paper, we propose a novel module called Multi-Domain Character Distance Perception (MDCDP) to establish a visual and semantic related position encoding. MDCDP uses positional embedding to query both visual and semantic features following the attention mechanism. It naturally encodes the positional clue, which describes both visual and semantic distances among characters. We develop a novel architecture named CDistNet that stacks MDCDP several times to guide precise distance modeling. Thus, the visual-semantic alignment is well built even various difficulties presented. We apply CDistNet to two augmented datasets and six public benchmarks. The experiments demonstrate that CDistNet achieves state-of-the-art recognition accuracy. While the visualization also shows that CDistNet achieves proper attention localization in both visual and semantic domains. We will release our code upon acceptance.
From Two to One: A New Scene Text Recognizer with Visual Language Modeling Network
Aug 22, 2021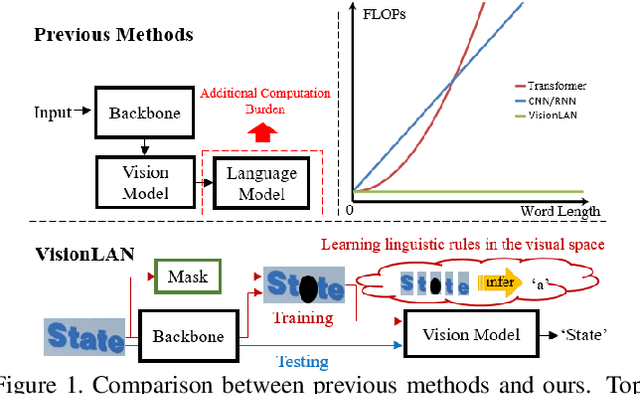
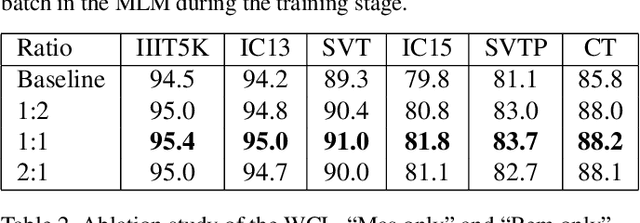
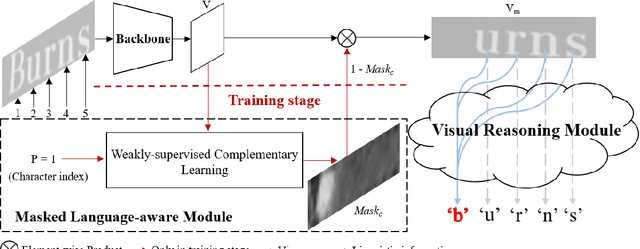
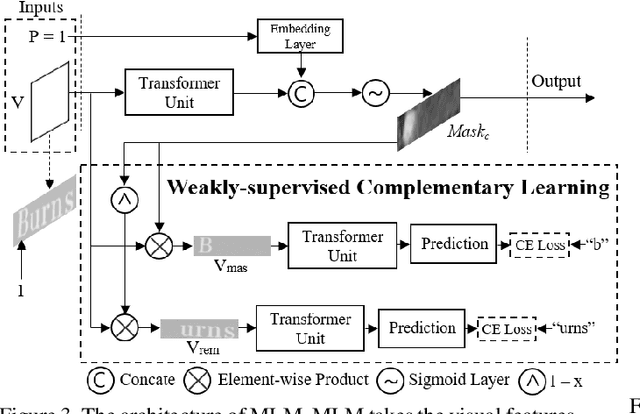
In this paper, we abandon the dominant complex language model and rethink the linguistic learning process in the scene text recognition. Different from previous methods considering the visual and linguistic information in two separate structures, we propose a Visual Language Modeling Network (VisionLAN), which views the visual and linguistic information as a union by directly enduing the vision model with language capability. Specially, we introduce the text recognition of character-wise occluded feature maps in the training stage. Such operation guides the vision model to use not only the visual texture of characters, but also the linguistic information in visual context for recognition when the visual cues are confused (e.g. occlusion, noise, etc.). As the linguistic information is acquired along with visual features without the need of extra language model, VisionLAN significantly improves the speed by 39% and adaptively considers the linguistic information to enhance the visual features for accurate recognition. Furthermore, an Occlusion Scene Text (OST) dataset is proposed to evaluate the performance on the case of missing character-wise visual cues. The state of-the-art results on several benchmarks prove our effectiveness. Code and dataset are available at https://github.com/wangyuxin87/VisionLAN.