 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetroInfer: A Vector-Storage Approach for Scalable Long-Context LLM Inference
May 05, 2025The growing context lengths of large language models (LLMs) pose significant challenges for efficient inference, primarily due to GPU memory and bandwidth constraints. We present RetroInfer, a novel system that reconceptualizes the key-value (KV) cache as a vector storage system which exploits the inherent attention sparsity to accelerate long-context LLM inference. At its core is the wave index, an Attention-aWare VEctor index that enables efficient and accurate retrieval of critical tokens through techniques such as tripartite attention approximation, accuracy-bounded attention estimation, and segmented clustering. Complementing this is the wave buffer, which coordinates KV cache placement and overlaps computation and data transfer across GPU and CPU to sustain high throughput. Unlike prior sparsity-based methods that struggle with token selection and hardware coordination, RetroInfer delivers robust performance without compromising model accuracy. Experiments on long-context benchmarks show up to 4.5X speedup over full attention within GPU memory limits and up to 10.5X over sparse attention baselines when KV cache is extended to CPU memory, all while preserving full-attention-level accuracy.
Empowering Agentic Video Analytics Systems with Video Language Models
May 02, 2025



AI-driven video analytics has become increasingly pivotal across diverse domains. However, existing systems are often constrained to specific, predefined tasks, limiting their adaptability in open-ended analytical scenarios. The recent emergence of Video-Language Models (VLMs) as transformative technologies offers significant potential for enabling open-ended video understanding, reasoning, and analytics. Nevertheless, their limited context windows present challenges when processing ultra-long video content, which is prevalent in real-world applications. To address this, we introduce AVAS, a VLM-powered system designed for open-ended, advanced video analytics. AVAS incorporates two key innovations: (1) the near real-time construction of Event Knowledge Graphs (EKGs) for efficient indexing of long or continuous video streams, and (2) an agentic retrieval-generation mechanism that leverages EKGs to handle complex and diverse queries. Comprehensive evaluations on public benchmarks, LVBench and VideoMME-Long, demonstrate that AVAS achieves state-of-the-art performance, attaining 62.3% and 64.1% accuracy, respectively, significantly surpassing existing VLM and video Retrieval-Augmented Generation (RAG) systems. Furthermore, to evaluate video analytics in ultra-long and open-world video scenarios, we introduce a new benchmark, AVAS-100. This benchmark comprises 8 videos, each exceeding 10 hours in duration, along with 120 manually annotated, diverse, and complex question-answer pairs. On AVAS-100, AVAS achieves top-tier performance with an accuracy of 75.8%.
Zoomer: Adaptive Image Focus Optimization for Black-box MLLM
Apr 30, 2025

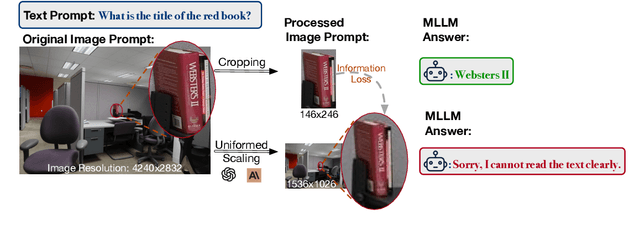
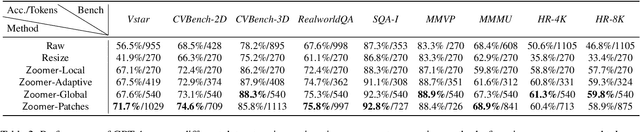
Recent advancements in multimodal large language models (MLLMs) have broadened the scope of vision-language tasks, excelling in applications like image captioning and interactive question-answering. However, these models struggle with accurately processing visual data, particularly in tasks requiring precise object recognition and fine visual details. Stringent token limits often result in the omission of critical information, hampering performance. To address these limitations, we introduce \SysName, a novel visual prompting mechanism designed to enhance MLLM performance while preserving essential visual details within token limits. \SysName features three key innovations: a prompt-aware strategy that dynamically highlights relevant image regions, a spatial-preserving orchestration schema that maintains object integrity, and a budget-aware prompting method that balances global context with crucial visual details. Comprehensive evaluations across multiple datasets demonstrate that \SysName consistently outperforms baseline methods, achieving up to a $26.9\%$ improvement in accuracy while significantly reducing token consumption.
MMInference: Accelerating Pre-filling for Long-Context VLMs via Modality-Aware Permutation Sparse Attention
Apr 22, 2025



The integration of long-context capabilities with visual understanding unlocks unprecedented potential for Vision Language Models (VLMs). However, the quadratic attention complexity during the pre-filling phase remains a significant obstacle to real-world deployment. To overcome this limitation, we introduce MMInference (Multimodality Million tokens Inference), a dynamic sparse attention method that accelerates the prefilling stage for long-context multi-modal inputs. First, our analysis reveals that the temporal and spatial locality of video input leads to a unique sparse pattern, the Grid pattern. Simultaneously, VLMs exhibit markedly different sparse distributions across different modalities. We introduce a permutation-based method to leverage the unique Grid pattern and handle modality boundary issues. By offline search the optimal sparse patterns for each head, MMInference constructs the sparse distribution dynamically based on the input. We also provide optimized GPU kernels for efficient sparse computations. Notably, MMInference integrates seamlessly into existing VLM pipelines without any model modifications or fine-tuning. Experiments on multi-modal benchmarks-including Video QA, Captioning, VisionNIAH, and Mixed-Modality NIAH-with state-of-the-art long-context VLMs (LongVila, LlavaVideo, VideoChat-Flash, Qwen2.5-VL) show that MMInference accelerates the pre-filling stage by up to 8.3x at 1M tokens while maintaining accuracy. Our code is available at https://aka.ms/MMInference.
NTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.
NTIRE 2025 Challenge on Cross-Domain Few-Shot Object Detection: Methods and Results
Apr 14, 2025Cross-Domain Few-Shot Object Detection (CD-FSOD) poses significant challenges to existing object detection and few-shot detection models when applied across domains. In conjunction with NTIRE 2025, we organized the 1st CD-FSOD Challenge, aiming to advance the performance of current object detectors on entirely novel target domains with only limited labeled data. The challenge attracted 152 registered participants, received submissions from 42 teams, and concluded with 13 teams making valid final submissions. Participants approached the task from diverse perspectives, proposing novel models that achieved new state-of-the-art (SOTA) results under both open-source and closed-source settings. In this report, we present an overview of the 1st NTIRE 2025 CD-FSOD Challenge, highlighting the proposed solutions and summarizing the results submitted by the participants.
Scaling Up On-Device LLMs via Active-Weight Swapping Between DRAM and Flash
Apr 11, 2025Large language models (LLMs) are increasingly being deployed on mobile devices, but the limited DRAM capacity constrains the deployable model size. This paper introduces ActiveFlow, the first LLM inference framework that can achieve adaptive DRAM usage for modern LLMs (not ReLU-based), enabling the scaling up of deployable model sizes. The framework is based on the novel concept of active weight DRAM-flash swapping and incorporates three novel techniques: (1) Cross-layer active weights preloading. It uses the activations from the current layer to predict the active weights of several subsequent layers, enabling computation and data loading to overlap, as well as facilitating large I/O transfers. (2) Sparsity-aware self-distillation. It adjusts the active weights to align with the dense-model output distribution, compensating for approximations introduced by contextual sparsity. (3) Active weight DRAM-flash swapping pipeline. It orchestrates the DRAM space allocation among the hot weight cache, preloaded active weights, and computation-involved weights based on available memory. Results show ActiveFlow achieves the performance-cost Pareto frontier compared to existing efficiency optimization methods.
Advancing Mobile GUI Agents: A Verifier-Driven Approach to Practical Deployment
Mar 21, 2025



We propose V-Droid, a mobile GUI task automation agent. Unlike previous mobile agents that utilize Large Language Models (LLMs) as generators to directly generate actions at each step, V-Droid employs LLMs as verifiers to evaluate candidate actions before making final decisions. To realize this novel paradigm, we introduce a comprehensive framework for constructing verifier-driven mobile agents: the discretized action space construction coupled with the prefilling-only workflow to accelerate the verification process, the pair-wise progress preference training to significantly enhance the verifier's decision-making capabilities, and the scalable human-agent joint annotation scheme to efficiently collect the necessary data at scale. V-Droid sets a new state-of-the-art task success rate across several public mobile task automation benchmarks: 59.5% on AndroidWorld, 38.3% on AndroidLab, and 49% on MobileAgentBench, surpassing existing agents by 9.5%, 2.1%, and 9%, respectively. Furthermore, V-Droid achieves an impressively low latency of 0.7 seconds per step, making it the first mobile agent capable of delivering near-real-time, effective decision-making capabilities.
HiTVideo: Hierarchical Tokenizers for Enhancing Text-to-Video Generation with Autoregressive Large Language Models
Mar 14, 2025



Text-to-video generation poses significant challenges due to the inherent complexity of video data, which spans both temporal and spatial dimensions. It introduces additional redundancy, abrupt variations, and a domain gap between language and vision tokens while generation. Addressing these challenges requires an effective video tokenizer that can efficiently encode video data while preserving essential semantic and spatiotemporal information, serving as a critical bridge between text and vision. Inspired by the observation in VQ-VAE-2 and workflows of traditional animation, we propose HiTVideo for text-to-video generation with hierarchical tokenizers. It utilizes a 3D causal VAE with a multi-layer discrete token framework, encoding video content into hierarchically structured codebooks. Higher layers capture semantic information with higher compression, while lower layers focus on fine-grained spatiotemporal details, striking a balance between compression efficiency and reconstruction quality. Our approach efficiently encodes longer video sequences (e.g., 8 seconds, 64 frames), reducing bits per pixel (bpp) by approximately 70\% compared to baseline tokenizers, while maintaining competitive reconstruction quality. We explore the trade-offs between compression and reconstruction, while emphasizing the advantages of high-compressed semantic tokens in text-to-video tasks. HiTVideo aims to address the potential limitations of existing video tokenizers in text-to-video generation tasks, striving for higher compression ratios and simplify LLMs modeling under language guidance, offering a scalable and promising framework for advancing text to video generation. Demo page: https://ziqinzhou66.github.io/project/HiTVideo.
Towards Explainable Doctor Recommendation with Large Language Models
Mar 04, 2025The advent of internet medicine provides patients with unprecedented convenience in searching and communicating with doctors relevant to their diseases and desired treatments online. However, the current doctor recommendation systems fail to fully ensure the professionalism and interpretability of the recommended results. In this work, we formulate doctor recommendation as a ranking task and develop a large language model (LLM)-based pointwise ranking framework. Our framework ranks doctors according to their relevance regarding specific diseases-treatment pairs in a zero-shot setting. The advantage of our framework lies in its ability to generate precise and explainable doctor ranking results. Additionally, we construct DrRank, a new expertise-driven doctor ranking dataset comprising over 38 disease-treatment pairs. Experiment results on the DrRank dataset demonstrate that our framework significantly outperforms the strongest cross-encoder baseline, achieving a notable gain of +5.45 in the NDCG@10 score while maintaining affordable latency consumption. Furthermore, we comprehensively present the fairness analysis results of our framework from three perspectives of different diseases, patient gender, and geographical regions. Meanwhile, the interpretability of our framework is rigorously verified by three human experts, providing further evidence of the reliability of our proposed framework for doctor recommendation.