 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting RIS Optimization Limits for Multi-User Beamforming and Signal Suppression
Jun 16, 2026This paper presents a unified framework for exploiting the boundaries of reconfigurable intelligent surfaces (RIS) joint optimization in multi-user wireless systems, where a single RIS accommodates diverse objectives.We first propose an adaptive gradient-scaling mechanism that accelerates the convergence of the underlying optimization algorithm while maintaining stable performance across varying channel and system parameters. The proposed mechanism enables the solver to reach a reasonably good solution rapidly without requiring manual tuning of step sizes or algorithmic hyperparameters when system inputs change. We then propose a low-complexity beamformer recovery method tailored for single-user scenarios, which circumvents the full matrix decomposition required by traditional approaches, thereby significantly reducing computational overhead. Building on these foundations, we develop an element allocation strategy that enables user-specific prioritization through assignment of RIS subsets. This is further extended by a modular add-drop mechanism that supports partial-panel optimization in general multi-user settings. The framework is evaluated across three representative scenarios: (i) signal amplification for all users, (ii) signal suppression for all users, and (iii) selective amplification and suppression. To characterize performance limits, we derive power trade-off boundaries using scalarized joint optimization, which closely align with Monte Carlo simulations. Our unified joint optimization method consistently yield solutions near these boundaries, confirming its near-optimality. Extensive simulations under realistic channel models demonstrate that the proposed approach outperforms conventional semidefinite relaxation techniques, offering a scalable and effective RIS control strategy for cooperative and competitive multi-user environments.
EMBER: Efficient Memory via Budgeted Evidence Retention for Long-Horizon Agents
Jun 04, 2026Long-horizon agents can archive large histories, but future answers still incur retrieval, rereading, and context costs. When retained memory misses answer-relevant evidence, the system must return to larger portions of the raw history. We study budgeted evidence survival: before the query is known, which source evidence should be retained so that it remains recoverable and usable under a fixed retained source-evidence token budget? We instantiate this setting as Budgeted Pre-Query Retention, where memory is written during ingestion and later read without access to the full raw stream. We introduce EMBER, a learned retention policy that constructs a compact, source-backed evidence state. EMBER stores evidence capsules: verbatim source excerpts paired with retrieval keys and update metadata, preserving both grounding and read-time access. Post-query outcome feedback trains the writer to preserve evidence across the ingestion-retrieval-answer chain. On LongMemEval-RR, our LongMemEval-derived retained-evidence protocol, EMBER-14B reaches 0.3017 F1 at the 8192-token retained-evidence comparison point, compared with 0.1765 for the strongest non-EMBER budgeted baseline. Across retained source-evidence budgets, EMBER improves F1, Retain-Recall, and Read-Recall, indicating that long-horizon memory depends on retaining evidence within the budget rather than rereading larger histories.
Cast a Wider Net: Coordinated Pass@K Policy Optimization for Code Reasoning
May 26, 2026Repeated sampling with a verifier is the standard way to allocate test-time compute for code generation, with pass@$K$ as the canonical metric. Yet the standard policy class draws $K$ independent samples from a single answer distribution, so attempts often collapse onto near-duplicate reasoning paths and waste the budget on redundant rollouts. This failure is costly in competitive programming, where many problems admit multiple distinct algorithmic strategies and pass@$K$ requires only one correct attempt. We propose Coordinated Pass@$K$ Policy Optimization (CPPO), which turns pass@$K$ generation into joint exploration over strategies: a planner emits a tuple of $K{=}4$ alternative high-level methods, and a shared solver attempts one solution per method. CPPO trains this joint policy with a multiplicative planner reward, $R_{\mathrm{plan}} = J_ψ\cdot R_{\mathrm{out}}$, assigning credit only to valid strategy tuples that lead to verifier-confirmed pass@$K$ success. Across APPS, CodeContests, and LiveCodeBench-v6, CPPO improves pass@$4$ over direct sampling, planning baselines, planner-only SFT, and pass@$K$-oriented RL under the same $K{=}4$ solver-attempt budget, with statistically significant gains on six of nine model--benchmark cells. The largest single gain is $+0.16$ on Qwen3.5-9B LiveCodeBench-v6 over the strongest baseline, PKPO ($0.588 \rightarrow 0.748$; paired bootstrap, $p < 0.05$).
Accelerating Transformer-Based Monocular SLAM via Geometric Utility Scoring
Apr 13, 2026Geometric Foundation Models (GFMs) have recently advanced monocular SLAM by providing robust, calibration-free 3D priors. However, deploying these models on dense video streams introduces significant computational redundancy. Current GFM-based SLAM systems typically rely on post hoc keyframe selection. Because of this, they must perform expensive dense geometric decoding simply to determine whether a frame contains novel geometry, resulting in late rejection and wasted computation. To mitigate this inefficiency, we propose LeanGate, a lightweight feed-forward frame-gating network. LeanGate predicts a geometric utility score to assess a frame's mapping value prior to the heavy GFM feature extraction and matching stages. As a predictive plug-and-play module, our approach bypasses over 90% of redundant frames. Evaluations on standard SLAM benchmarks demonstrate that LeanGate reduces tracking FLOPs by more than 85% and achieves a 5x end-to-end throughput speedup. Furthermore, it maintains the tracking and mapping accuracy of dense baselines. Project page: https://lean-gate.github.io/
ByteLoom: Weaving Geometry-Consistent Human-Object Interactions through Progressive Curriculum Learning
Dec 28, 2025Human-object interaction (HOI) video generation has garnered increasing attention due to its promising applications in digital humans, e-commerce, advertising, and robotics imitation learning. However, existing methods face two critical limitations: (1) a lack of effective mechanisms to inject multi-view information of the object into the model, leading to poor cross-view consistency, and (2) heavy reliance on fine-grained hand mesh annotations for modeling interaction occlusions. To address these challenges, we introduce ByteLoom, a Diffusion Transformer (DiT)-based framework that generates realistic HOI videos with geometrically consistent object illustration, using simplified human conditioning and 3D object inputs. We first propose an RCM-cache mechanism that leverages Relative Coordinate Maps (RCM) as a universal representation to maintain object's geometry consistency and precisely control 6-DoF object transformations in the meantime. To compensate HOI dataset scarcity and leverage existing datasets, we further design a training curriculum that enhances model capabilities in a progressive style and relaxes the demand of hand mesh. Extensive experiments demonstrate that our method faithfully preserves human identity and the object's multi-view geometry, while maintaining smooth motion and object manipulation.
Privacy-Aware Sharing of Raw Spatial Sensor Data for Cooperative Perception
Dec 18, 2025Cooperative perception between vehicles is poised to offer robust and reliable scene understanding. Recently, we are witnessing experimental systems research building testbeds that share raw spatial sensor data for cooperative perception. While there has been a marked improvement in accuracies and is the natural way forward, we take a moment to consider the problems with such an approach for eventual adoption by automakers. In this paper, we first argue that new forms of privacy concerns arise and discourage stakeholders to share raw sensor data. Next, we present SHARP, a research framework to minimize privacy leakage and drive stakeholders towards the ambitious goal of raw data based cooperative perception. Finally, we discuss open questions for networked systems, mobile computing, perception researchers, industry and government in realizing our proposed framework.
Zoomer: Adaptive Image Focus Optimization for Black-box MLLM
Apr 30, 2025

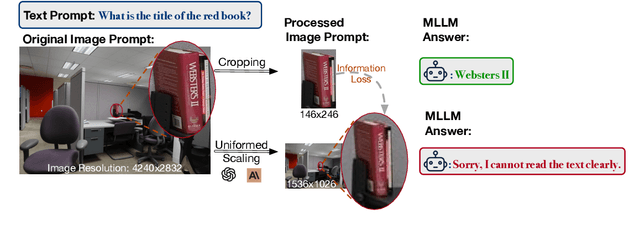
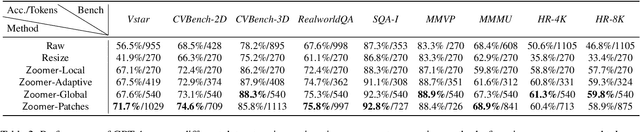
Recent advancements in multimodal large language models (MLLMs) have broadened the scope of vision-language tasks, excelling in applications like image captioning and interactive question-answering. However, these models struggle with accurately processing visual data, particularly in tasks requiring precise object recognition and fine visual details. Stringent token limits often result in the omission of critical information, hampering performance. To address these limitations, we introduce \SysName, a novel visual prompting mechanism designed to enhance MLLM performance while preserving essential visual details within token limits. \SysName features three key innovations: a prompt-aware strategy that dynamically highlights relevant image regions, a spatial-preserving orchestration schema that maintains object integrity, and a budget-aware prompting method that balances global context with crucial visual details. Comprehensive evaluations across multiple datasets demonstrate that \SysName consistently outperforms baseline methods, achieving up to a $26.9\%$ improvement in accuracy while significantly reducing token consumption.
"Impressively Scary:" Exploring User Perceptions and Reactions to Unraveling Machine Learning Models in Social Media Applications
Mar 05, 2025Machine learning models deployed locally on social media applications are used for features, such as face filters which read faces in-real time, and they expose sensitive attributes to the apps. However, the deployment of machine learning models, e.g., when, where, and how they are used, in social media applications is opaque to users. We aim to address this inconsistency and investigate how social media user perceptions and behaviors change once exposed to these models. We conducted user studies (N=21) and found that participants were unaware to both what the models output and when the models were used in Instagram and TikTok, two major social media platforms. In response to being exposed to the models' functionality, we observed long term behavior changes in 8 participants. Our analysis uncovers the challenges and opportunities in providing transparency for machine learning models that interact with local user data.
AGrail: A Lifelong Agent Guardrail with Effective and Adaptive Safety Detection
Feb 18, 2025



The rapid advancements in Large Language Models (LLMs) have enabled their deployment as autonomous agents for handling complex tasks in dynamic environments. These LLMs demonstrate strong problem-solving capabilities and adaptability to multifaceted scenarios. However, their use as agents also introduces significant risks, including task-specific risks, which are identified by the agent administrator based on the specific task requirements and constraints, and systemic risks, which stem from vulnerabilities in their design or interactions, potentially compromising confidentiality, integrity, or availability (CIA) of information and triggering security risks. Existing defense agencies fail to adaptively and effectively mitigate these risks. In this paper, we propose AGrail, a lifelong agent guardrail to enhance LLM agent safety, which features adaptive safety check generation, effective safety check optimization, and tool compatibility and flexibility. Extensive experiments demonstrate that AGrail not only achieves strong performance against task-specific and system risks but also exhibits transferability across different LLM agents' tasks.
VoLUT: Efficient Volumetric streaming enhanced by LUT-based super-resolution
Feb 17, 20253D volumetric video provides immersive experience and is gaining traction in digital media. Despite its rising popularity, the streaming of volumetric video content poses significant challenges due to the high data bandwidth requirement. A natural approach to mitigate the bandwidth issue is to reduce the volumetric video's data rate by downsampling the content prior to transmission. The video can then be upsampled at the receiver's end using a super-resolution (SR) algorithm to reconstruct the high-resolution details. While super-resolution techniques have been extensively explored and advanced for 2D video content, there is limited work on SR algorithms tailored for volumetric videos. To address this gap and the growing need for efficient volumetric video streaming, we have developed VoLUT with a new SR algorithm specifically designed for volumetric content. Our algorithm uniquely harnesses the power of lookup tables (LUTs) to facilitate the efficient and accurate upscaling of low-resolution volumetric data. The use of LUTs enables our algorithm to quickly reference precomputed high-resolution values, thereby significantly reducing the computational complexity and time required for upscaling. We further apply adaptive video bit rate algorithm (ABR) to dynamically determine the downsampling rate according to the network condition and stream the selected video rate to the receiver. Compared to related work, VoLUT is the first to enable high-quality 3D SR on commodity mobile devices at line-rate. Our evaluation shows VoLUT can reduce bandwidth usage by 70% , boost QoE by 36.7% for volumetric video streaming and achieve 3D SR speed-up with no quality compromise.