 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel-Probe: Towards Efficient Parallel Thinking via 2D Probing
Feb 03, 2026Parallel thinking has emerged as a promising paradigm for reasoning, yet it imposes significant computational burdens. Existing efficiency methods primarily rely on local, per-trajectory signals and lack principled mechanisms to exploit global dynamics across parallel branches. We introduce 2D probing, an interface that exposes the width-depth dynamics of parallel thinking by periodically eliciting intermediate answers from all branches. Our analysis reveals three key insights: non-monotonic scaling across width-depth allocations, heterogeneous reasoning branch lengths, and early stabilization of global consensus. Guided by these insights, we introduce $\textbf{Parallel-Probe}$, a training-free controller designed to optimize online parallel thinking. Parallel-Probe employs consensus-based early stopping to regulate reasoning depth and deviation-based branch pruning to dynamically adjust width. Extensive experiments across three benchmarks and multiple models demonstrate that Parallel-Probe establishes a superior Pareto frontier for test-time scaling. Compared to standard majority voting, it reduces sequential tokens by up to $\textbf{35.8}$% and total token cost by over $\textbf{25.8}$% while maintaining competitive accuracy.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
A Unified 3D Object Perception Framework for Real-Time Outside-In Multi-Camera Systems
Jan 15, 2026Accurate 3D object perception and multi-target multi-camera (MTMC) tracking are fundamental for the digital transformation of industrial infrastructure. However, transitioning "inside-out" autonomous driving models to "outside-in" static camera networks presents significant challenges due to heterogeneous camera placements and extreme occlusion. In this paper, we present an adapted Sparse4D framework specifically optimized for large-scale infrastructure environments. Our system leverages absolute world-coordinate geometric priors and introduces an occlusion-aware ReID embedding module to maintain identity stability across distributed sensor networks. To bridge the Sim2Real domain gap without manual labeling, we employ a generative data augmentation strategy using the NVIDIA COSMOS framework, creating diverse environmental styles that enhance the model's appearance-invariance. Evaluated on the AI City Challenge 2025 benchmark, our camera-only framework achieves a state-of-the-art HOTA of $45.22$. Furthermore, we address real-time deployment constraints by developing an optimized TensorRT plugin for Multi-Scale Deformable Aggregation (MSDA). Our hardware-accelerated implementation achieves a $2.15\times$ speedup on modern GPU architectures, enabling a single Blackwell-class GPU to support over 64 concurrent camera streams.
LangDriveCTRL: Natural Language Controllable Driving Scene Editing with Multi-modal Agents
Dec 19, 2025

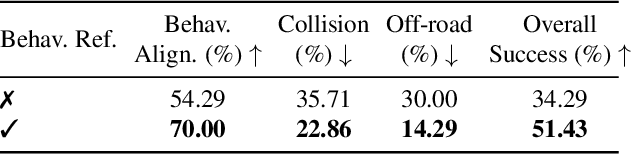

LangDriveCTRL is a natural-language-controllable framework for editing real-world driving videos to synthesize diverse traffic scenarios. It leverages explicit 3D scene decomposition to represent driving videos as a scene graph, containing static background and dynamic objects. To enable fine-grained editing and realism, it incorporates an agentic pipeline in which an Orchestrator transforms user instructions into execution graphs that coordinate specialized agents and tools. Specifically, an Object Grounding Agent establishes correspondence between free-form text descriptions and target object nodes in the scene graph; a Behavior Editing Agent generates multi-object trajectories from language instructions; and a Behavior Reviewer Agent iteratively reviews and refines the generated trajectories. The edited scene graph is rendered and then refined using a video diffusion tool to address artifacts introduced by object insertion and significant view changes. LangDriveCTRL supports both object node editing (removal, insertion and replacement) and multi-object behavior editing from a single natural-language instruction. Quantitatively, it achieves nearly $2\times$ higher instruction alignment than the previous SoTA, with superior structural preservation, photorealism, and traffic realism. Project page is available at: https://yunhe24.github.io/langdrivectrl/.
Rubric-Based Benchmarking and Reinforcement Learning for Advancing LLM Instruction Following
Nov 13, 2025Recent progress in large language models (LLMs) has led to impressive performance on a range of tasks, yet advanced instruction following (IF)-especially for complex, multi-turn, and system-prompted instructions-remains a significant challenge. Rigorous evaluation and effective training for such capabilities are hindered by the lack of high-quality, human-annotated benchmarks and reliable, interpretable reward signals. In this work, we introduce AdvancedIF (we will release this benchmark soon), a comprehensive benchmark featuring over 1,600 prompts and expert-curated rubrics that assess LLMs ability to follow complex, multi-turn, and system-level instructions. We further propose RIFL (Rubric-based Instruction-Following Learning), a novel post-training pipeline that leverages rubric generation, a finetuned rubric verifier, and reward shaping to enable effective reinforcement learning for instruction following. Extensive experiments demonstrate that RIFL substantially improves the instruction-following abilities of LLMs, achieving a 6.7% absolute gain on AdvancedIF and strong results on public benchmarks. Our ablation studies confirm the effectiveness of each component in RIFL. This work establishes rubrics as a powerful tool for both training and evaluating advanced IF in LLMs, paving the way for more capable and reliable AI systems.
Boosting LLM Reasoning via Spontaneous Self-Correction
Jun 07, 2025



While large language models (LLMs) have demonstrated remarkable success on a broad range of tasks, math reasoning remains a challenging one. One of the approaches for improving math reasoning is self-correction, which designs self-improving loops to let the model correct its own mistakes. However, existing self-correction approaches treat corrections as standalone post-generation refinements, relying on extra prompt and system designs to elicit self-corrections, instead of performing real-time, spontaneous self-corrections in a single pass. To address this, we propose SPOC, a spontaneous self-correction approach that enables LLMs to generate interleaved solutions and verifications in a single inference pass, with generation dynamically terminated based on verification outcomes, thereby effectively scaling inference time compute. SPOC considers a multi-agent perspective by assigning dual roles -- solution proposer and verifier -- to the same model. We adopt a simple yet effective approach to generate synthetic data for fine-tuning, enabling the model to develop capabilities for self-verification and multi-agent collaboration. We further improve its solution proposal and verification accuracy through online reinforcement learning. Experiments on mathematical reasoning benchmarks show that SPOC significantly improves performance. Notably, SPOC boosts the accuracy of Llama-3.1-8B and 70B Instruct models, achieving gains of 8.8% and 11.6% on MATH500, 10.0% and 20.0% on AMC23, and 3.3% and 6.7% on AIME24, respectively.
Towards An Efficient LLM Training Paradigm for CTR Prediction
Mar 02, 2025Large Language Models (LLMs) have demonstrated tremendous potential as the next-generation ranking-based recommendation system. Many recent works have shown that LLMs can significantly outperform conventional click-through-rate (CTR) prediction approaches. Despite such promising results, the computational inefficiency inherent in the current training paradigm makes it particularly challenging to train LLMs for ranking-based recommendation tasks on large datasets. To train LLMs for CTR prediction, most existing studies adopt the prevalent ''sliding-window'' paradigm. Given a sequence of $m$ user interactions, a unique training prompt is constructed for each interaction by designating it as the prediction target along with its preceding $n$ interactions serving as context. In turn, the sliding-window paradigm results in an overall complexity of $O(mn^2)$ that scales linearly with the length of user interactions. Consequently, a direct adoption to train LLMs with such strategy can result in prohibitively high training costs as the length of interactions grows. To alleviate the computational inefficiency, we propose a novel training paradigm, namely Dynamic Target Isolation (DTI), that structurally parallelizes the training of $k$ (where $k >> 1$) target interactions. Furthermore, we identify two major bottlenecks - hidden-state leakage and positional bias overfitting - that limit DTI to only scale up to a small value of $k$ (e.g., 5) then propose a computationally light solution to effectively tackle each. Through extensive experiments on three widely adopted public CTR datasets, we empirically show that DTI reduces training time by an average of $\textbf{92%}$ (e.g., from $70.5$ hrs to $5.31$ hrs), without compromising CTR prediction performance.
Think Smarter not Harder: Adaptive Reasoning with Inference Aware Optimization
Jan 31, 2025Solving mathematics problems has been an intriguing capability of large language models, and many efforts have been made to improve reasoning by extending reasoning length, such as through self-correction and extensive long chain-of-thoughts. While promising in problem-solving, advanced long reasoning chain models exhibit an undesired single-modal behavior, where trivial questions require unnecessarily tedious long chains of thought. In this work, we propose a way to allow models to be aware of inference budgets by formulating it as utility maximization with respect to an inference budget constraint, hence naming our algorithm Inference Budget-Constrained Policy Optimization (IBPO). In a nutshell, models fine-tuned through IBPO learn to ``understand'' the difficulty of queries and allocate inference budgets to harder ones. With different inference budgets, our best models are able to have a $4.14$\% and $5.74$\% absolute improvement ($8.08$\% and $11.2$\% relative improvement) on MATH500 using $2.16$x and $4.32$x inference budgets respectively, relative to LLaMA3.1 8B Instruct. These improvements are approximately $2$x those of self-consistency under the same budgets.
Step-KTO: Optimizing Mathematical Reasoning through Stepwise Binary Feedback
Jan 18, 2025Large language models (LLMs) have recently demonstrated remarkable success in mathematical reasoning. Despite progress in methods like chain-of-thought prompting and self-consistency sampling, these advances often focus on final correctness without ensuring that the underlying reasoning process is coherent and reliable. This paper introduces Step-KTO, a training framework that combines process-level and outcome-level binary feedback to guide LLMs toward more trustworthy reasoning trajectories. By providing binary evaluations for both the intermediate reasoning steps and the final answer, Step-KTO encourages the model to adhere to logical progressions rather than relying on superficial shortcuts. Our experiments on challenging mathematical benchmarks show that Step-KTO significantly improves both final answer accuracy and the quality of intermediate reasoning steps. For example, on the MATH-500 dataset, Step-KTO achieves a notable improvement in Pass@1 accuracy over strong baselines. These results highlight the promise of integrating stepwise process feedback into LLM training, paving the way toward more interpretable and dependable reasoning capabilities.
Unifying Generative and Dense Retrieval for Sequential Recommendation
Nov 27, 2024



Sequential dense retrieval models utilize advanced sequence learning techniques to compute item and user representations, which are then used to rank relevant items for a user through inner product computation between the user and all item representations. However, this approach requires storing a unique representation for each item, resulting in significant memory requirements as the number of items grow. In contrast, the recently proposed generative retrieval paradigm offers a promising alternative by directly predicting item indices using a generative model trained on semantic IDs that encapsulate items' semantic information. Despite its potential for large-scale applications, a comprehensive comparison between generative retrieval and sequential dense retrieval under fair conditions is still lacking, leaving open questions regarding performance, and computation trade-offs. To address this, we compare these two approaches under controlled conditions on academic benchmarks and propose LIGER (LeveragIng dense retrieval for GEnerative Retrieval), a hybrid model that combines the strengths of these two widely used methods. LIGER integrates sequential dense retrieval into generative retrieval, mitigating performance differences and enhancing cold-start item recommendation in the datasets evaluated. This hybrid approach provides insights into the trade-offs between these approaches and demonstrates improvements in efficiency and effectiveness for recommendation systems in small-scale benchmarks.