 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
FACET: Fairness in Computer Vision Evaluation Benchmark
Aug 31, 2023



Computer vision models have known performance disparities across attributes such as gender and skin tone. This means during tasks such as classification and detection, model performance differs for certain classes based on the demographics of the people in the image. These disparities have been shown to exist, but until now there has not been a unified approach to measure these differences for common use-cases of computer vision models. We present a new benchmark named FACET (FAirness in Computer Vision EvaluaTion), a large, publicly available evaluation set of 32k images for some of the most common vision tasks - image classification, object detection and segmentation. For every image in FACET, we hired expert reviewers to manually annotate person-related attributes such as perceived skin tone and hair type, manually draw bounding boxes and label fine-grained person-related classes such as disk jockey or guitarist. In addition, we use FACET to benchmark state-of-the-art vision models and present a deeper understanding of potential performance disparities and challenges across sensitive demographic attributes. With the exhaustive annotations collected, we probe models using single demographics attributes as well as multiple attributes using an intersectional approach (e.g. hair color and perceived skin tone). Our results show that classification, detection, segmentation, and visual grounding models exhibit performance disparities across demographic attributes and intersections of attributes. These harms suggest that not all people represented in datasets receive fair and equitable treatment in these vision tasks. We hope current and future results using our benchmark will contribute to fairer, more robust vision models. FACET is available publicly at https://facet.metademolab.com/
The effectiveness of MAE pre-pretraining for billion-scale pretraining
Mar 23, 2023



This paper revisits the standard pretrain-then-finetune paradigm used in computer vision for visual recognition tasks. Typically, state-of-the-art foundation models are pretrained using large scale (weakly) supervised datasets with billions of images. We introduce an additional pre-pretraining stage that is simple and uses the self-supervised MAE technique to initialize the model. While MAE has only been shown to scale with the size of models, we find that it scales with the size of the training dataset as well. Thus, our MAE-based pre-pretraining scales with both model and data size making it applicable for training foundation models. Pre-pretraining consistently improves both the model convergence and the downstream transfer performance across a range of model scales (millions to billions of parameters), and dataset sizes (millions to billions of images). We measure the effectiveness of pre-pretraining on 10 different visual recognition tasks spanning image classification, video recognition, object detection, low-shot classification and zero-shot recognition. Our largest model achieves new state-of-the-art results on iNaturalist-18 (91.3%), 1-shot ImageNet-1k (62.1%), and zero-shot transfer on Food-101 (96.0%). Our study reveals that model initialization plays a significant role, even for web-scale pretraining with billions of images.
Vision-Language Models Performing Zero-Shot Tasks Exhibit Gender-based Disparities
Jan 26, 2023



We explore the extent to which zero-shot vision-language models exhibit gender bias for different vision tasks. Vision models traditionally required task-specific labels for representing concepts, as well as finetuning; zero-shot models like CLIP instead perform tasks with an open-vocabulary, meaning they do not need a fixed set of labels, by using text embeddings to represent concepts. With these capabilities in mind, we ask: Do vision-language models exhibit gender bias when performing zero-shot image classification, object detection and semantic segmentation? We evaluate different vision-language models with multiple datasets across a set of concepts and find (i) all models evaluated show distinct performance differences based on the perceived gender of the person co-occurring with a given concept in the image and that aggregating analyses over all concepts can mask these concerns; (ii) model calibration (i.e. the relationship between accuracy and confidence) also differs distinctly by perceived gender, even when evaluating on similar representations of concepts; and (iii) these observed disparities align with existing gender biases in word embeddings from language models. These findings suggest that, while language greatly expands the capability of vision tasks, it can also contribute to social biases in zero-shot vision settings. Furthermore, biases can further propagate when foundational models like CLIP are used by other models to enable zero-shot capabilities.
A Systematic Study of Bias Amplification
Jan 27, 2022
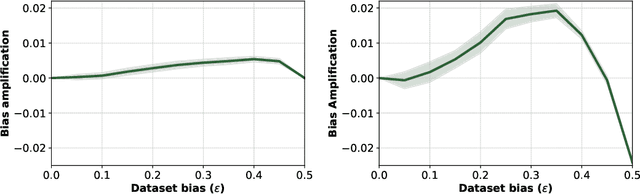
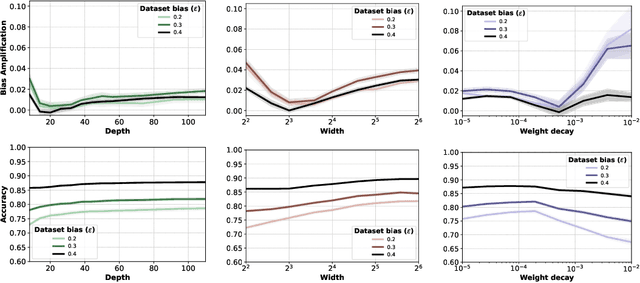
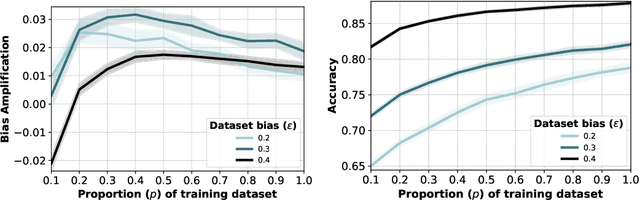
Recent research suggests that predictions made by machine-learning models can amplify biases present in the training data. When a model amplifies bias, it makes certain predictions at a higher rate for some groups than expected based on training-data statistics. Mitigating such bias amplification requires a deep understanding of the mechanics in modern machine learning that give rise to that amplification. We perform the first systematic, controlled study into when and how bias amplification occurs. To enable this study, we design a simple image-classification problem in which we can tightly control (synthetic) biases. Our study of this problem reveals that the strength of bias amplification is correlated to measures such as model accuracy, model capacity, model overconfidence, and amount of training data. We also find that bias amplification can vary greatly during training. Finally, we find that bias amplification may depend on the difficulty of the classification task relative to the difficulty of recognizing group membership: bias amplification appears to occur primarily when it is easier to recognize group membership than class membership. Our results suggest best practices for training machine-learning models that we hope will help pave the way for the development of better mitigation strategies.
Revisiting Weakly Supervised Pre-Training of Visual Perception Models
Jan 20, 2022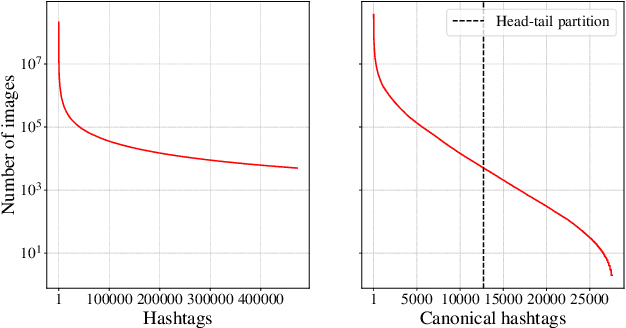
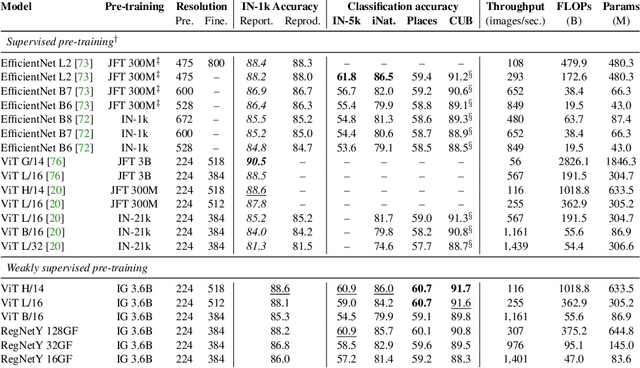
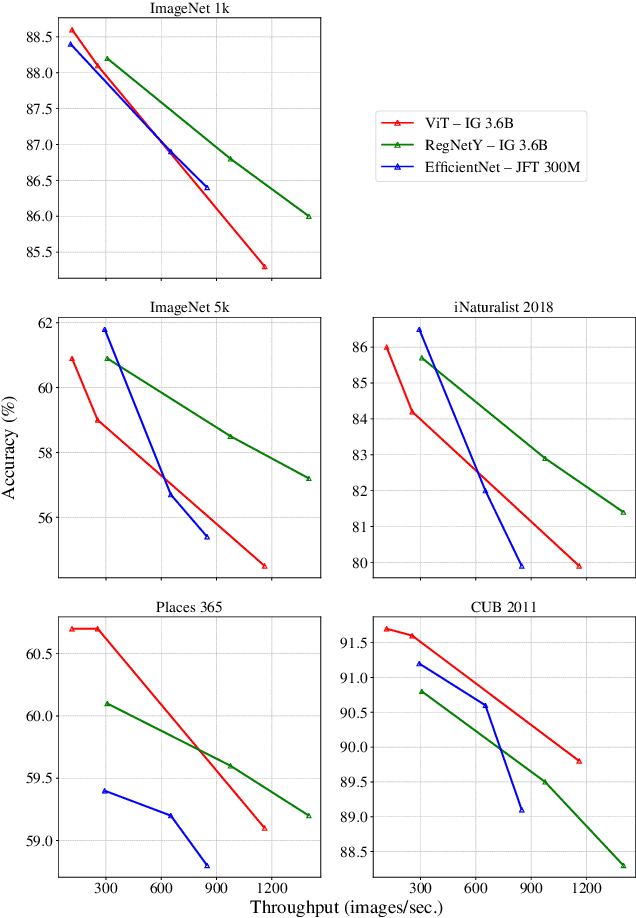
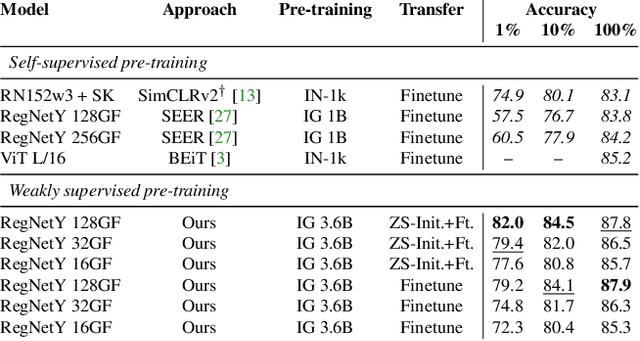
Model pre-training is a cornerstone of modern visual recognition systems. Although fully supervised pre-training on datasets like ImageNet is still the de-facto standard, recent studies suggest that large-scale weakly supervised pre-training can outperform fully supervised approaches. This paper revisits weakly-supervised pre-training of models using hashtag supervision with modern versions of residual networks and the largest-ever dataset of images and corresponding hashtags. We study the performance of the resulting models in various transfer-learning settings including zero-shot transfer. We also compare our models with those obtained via large-scale self-supervised learning. We find our weakly-supervised models to be very competitive across all settings, and find they substantially outperform their self-supervised counterparts. We also include an investigation into whether our models learned potentially troubling associations or stereotypes. Overall, our results provide a compelling argument for the use of weakly supervised learning in the development of visual recognition systems. Our models, Supervised Weakly through hashtAGs (SWAG), are available publicly.
PyTorchVideo: A Deep Learning Library for Video Understanding
Nov 18, 2021
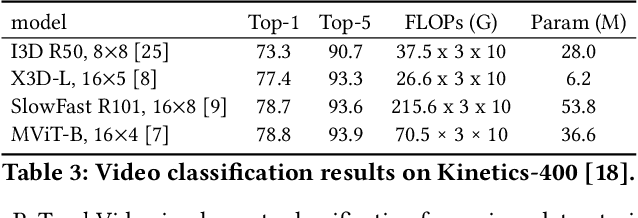

We introduce PyTorchVideo, an open-source deep-learning library that provides a rich set of modular, efficient, and reproducible components for a variety of video understanding tasks, including classification, detection, self-supervised learning, and low-level processing. The library covers a full stack of video understanding tools including multimodal data loading, transformations, and models that reproduce state-of-the-art performance. PyTorchVideo further supports hardware acceleration that enables real-time inference on mobile devices. The library is based on PyTorch and can be used by any training framework; for example, PyTorchLightning, PySlowFast, or Classy Vision. PyTorchVideo is available at https://pytorchvideo.org/
Forward Prediction for Physical Reasoning
Jun 18, 2020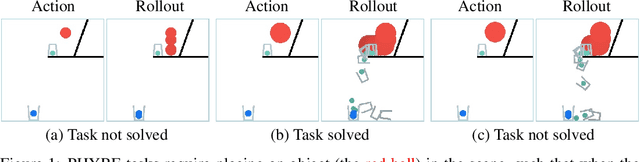

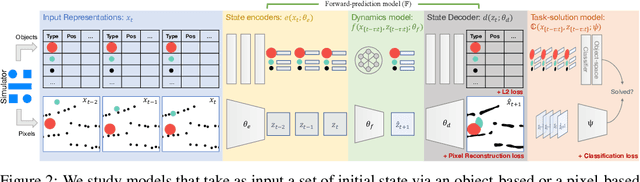
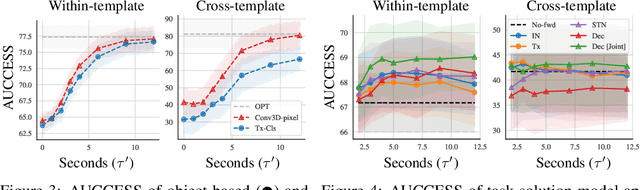
Physical reasoning requires forward prediction: the ability to forecast what will happen next given some initial world state. We study the performance of state-of-the-art forward-prediction models in complex physical-reasoning tasks. We do so by incorporating models that operate on object or pixel-based representations of the world, into simple physical-reasoning agents. We find that forward-prediction models improve the performance of physical-reasoning agents, particularly on complex tasks that involve many objects. However, we also find that these improvements are contingent on the training tasks being similar to the test tasks, and that generalization to different tasks is more challenging. Surprisingly, we observe that forward predictors with better pixel accuracy do not necessarily lead to better physical-reasoning performance. Nevertheless, our best models set a new state-of-the-art on the PHYRE benchmark for physical reasoning.
Classification of Hepatic Lesions using the Matching Metric
Oct 02, 2012
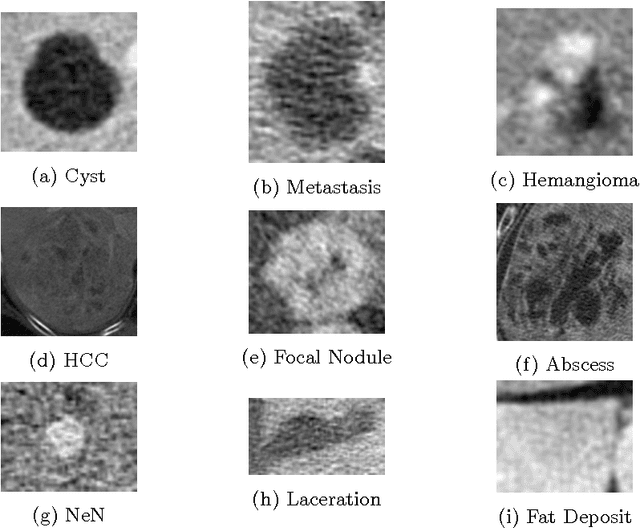

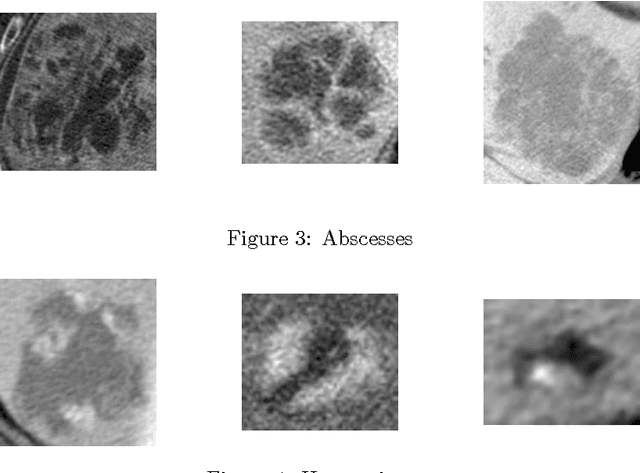
In this paper we present a methodology of classifying hepatic (liver) lesions using multidimensional persistent homology, the matching metric (also called the bottleneck distance), and a support vector machine. We present our classification results on a dataset of 132 lesions that have been outlined and annotated by radiologists. We find that topological features are useful in the classification of hepatic lesions. We also find that two-dimensional persistent homology outperforms one-dimensional persistent homology in this application.