 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified 3D Object Perception Framework for Real-Time Outside-In Multi-Camera Systems
Jan 15, 2026Accurate 3D object perception and multi-target multi-camera (MTMC) tracking are fundamental for the digital transformation of industrial infrastructure. However, transitioning "inside-out" autonomous driving models to "outside-in" static camera networks presents significant challenges due to heterogeneous camera placements and extreme occlusion. In this paper, we present an adapted Sparse4D framework specifically optimized for large-scale infrastructure environments. Our system leverages absolute world-coordinate geometric priors and introduces an occlusion-aware ReID embedding module to maintain identity stability across distributed sensor networks. To bridge the Sim2Real domain gap without manual labeling, we employ a generative data augmentation strategy using the NVIDIA COSMOS framework, creating diverse environmental styles that enhance the model's appearance-invariance. Evaluated on the AI City Challenge 2025 benchmark, our camera-only framework achieves a state-of-the-art HOTA of $45.22$. Furthermore, we address real-time deployment constraints by developing an optimized TensorRT plugin for Multi-Scale Deformable Aggregation (MSDA). Our hardware-accelerated implementation achieves a $2.15\times$ speedup on modern GPU architectures, enabling a single Blackwell-class GPU to support over 64 concurrent camera streams.
DiagramIR: An Automatic Pipeline for Educational Math Diagram Evaluation
Nov 11, 2025Large Language Models (LLMs) are increasingly being adopted as tools for learning; however, most tools remain text-only, limiting their usefulness for domains where visualizations are essential, such as mathematics. Recent work shows that LLMs are capable of generating code that compiles to educational figures, but a major bottleneck remains: scalable evaluation of these diagrams. We address this by proposing DiagramIR: an automatic and scalable evaluation pipeline for geometric figures. Our method relies on intermediate representations (IRs) of LaTeX TikZ code. We compare our pipeline to other evaluation baselines such as LLM-as-a-Judge, showing that our approach has higher agreement with human raters. This evaluation approach also enables smaller models like GPT-4.1-Mini to perform comparably to larger models such as GPT-5 at a 10x lower inference cost, which is important for deploying accessible and scalable education technologies.
Digital Wargames to Enhance Military Medical Evacuation Decision-Making
Jul 08, 2025



Medical evacuation is one of the United States Army's most storied and critical mission sets, responsible for efficiently and expediently evacuating the battlefield ill and injured. Medical evacuation planning involves designing a robust network of medical platforms and facilities capable of moving and treating large numbers of casualties. Until now, there has not been a medium to simulate these networks in a classroom setting and evaluate both offline planning and online decision-making performance. This work describes the Medical Evacuation Wargaming Initiative (MEWI), a three-dimensional multiplayer simulation developed in Unity that replicates battlefield constraints and uncertainties. MEWI accurately models patient interactions at casualty collection points, ambulance exchange points, medical treatment facilities, and evacuation platforms. Two operational scenarios are introduced: an amphibious island assault in the Pacific and a Eurasian conflict across a sprawling road and river network. These scenarios pit students against the clock to save as many casualties as possible while adhering to doctrinal lessons learned during didactic training. We visualize performance data collected from two iterations of the MEWI Pacific scenario executed in the United States Army's Medical Evacuation Doctrine Course. We consider post-wargame Likert survey data from student participants and external observer notes to identify key planning decision points, document medical evacuation lessons learned, and quantify general utility. Results indicate that MEWI participation substantially improves uptake of medical evacuation lessons learned and co-operative decision-making. MEWI is a substantial step forward in the field of high-fidelity training tools for medical education, and our study findings offer critical insights into improving medical evacuation education and operations across the joint force.
AmpleGCG-Plus: A Strong Generative Model of Adversarial Suffixes to Jailbreak LLMs with Higher Success Rates in Fewer Attempts
Oct 29, 2024



Although large language models (LLMs) are typically aligned, they remain vulnerable to jailbreaking through either carefully crafted prompts in natural language or, interestingly, gibberish adversarial suffixes. However, gibberish tokens have received relatively less attention despite their success in attacking aligned LLMs. Recent work, AmpleGCG~\citep{liao2024amplegcg}, demonstrates that a generative model can quickly produce numerous customizable gibberish adversarial suffixes for any harmful query, exposing a range of alignment gaps in out-of-distribution (OOD) language spaces. To bring more attention to this area, we introduce AmpleGCG-Plus, an enhanced version that achieves better performance in fewer attempts. Through a series of exploratory experiments, we identify several training strategies to improve the learning of gibberish suffixes. Our results, verified under a strict evaluation setting, show that it outperforms AmpleGCG on both open-weight and closed-source models, achieving increases in attack success rate (ASR) of up to 17\% in the white-box setting against Llama-2-7B-chat, and more than tripling ASR in the black-box setting against GPT-4. Notably, AmpleGCG-Plus jailbreaks the newer GPT-4o series of models at similar rates to GPT-4, and, uncovers vulnerabilities against the recently proposed circuit breakers defense. We publicly release AmpleGCG-Plus along with our collected training datasets.
Review of Computational Epigraphy
Jun 03, 2024



Computational Epigraphy refers to the process of extracting text from stone inscription, transliteration, interpretation, and attribution with the aid of computational methods. Traditional epigraphy methods are time consuming, and tend to damage the stone inscriptions while extracting text. Additionally, interpretation and attribution are subjective and can vary between different epigraphers. However, using modern computation methods can not only be used to extract text, but also interpret and attribute the text in a robust way. We survey and document the existing computational methods that aid in the above-mentioned tasks in epigraphy.
Scene Graph Generation with Geometric Context
Nov 25, 2021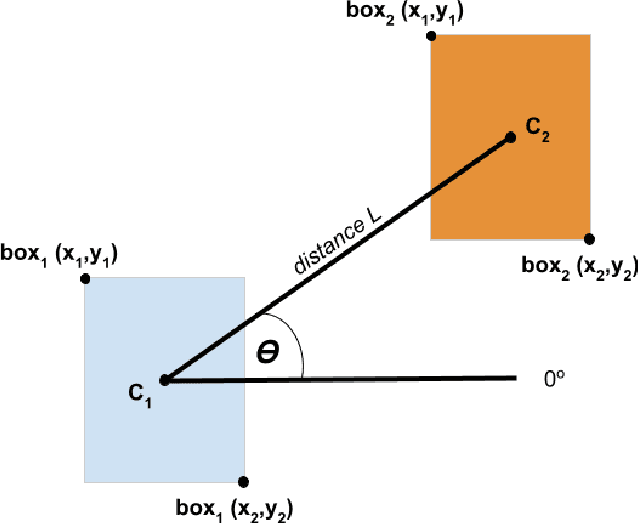

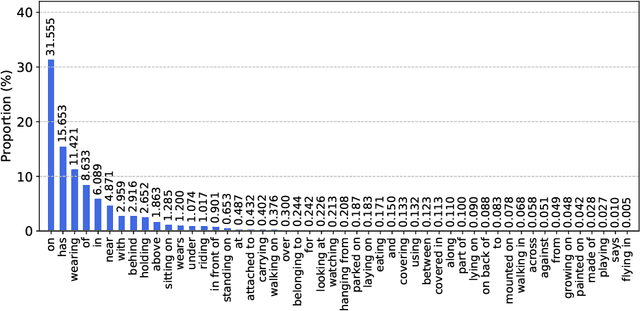
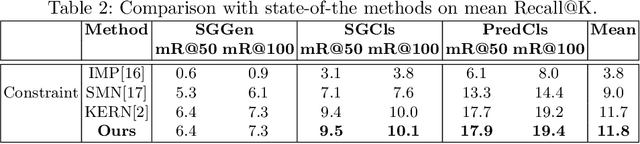
Scene Graph Generation has gained much attention in computer vision research with the growing demand in image understanding projects like visual question answering, image captioning, self-driving cars, crowd behavior analysis, activity recognition, and more. Scene graph, a visually grounded graphical structure of an image, immensely helps to simplify the image understanding tasks. In this work, we introduced a post-processing algorithm called Geometric Context to understand the visual scenes better geometrically. We use this post-processing algorithm to add and refine the geometric relationships between object pairs to a prior model. We exploit this context by calculating the direction and distance between object pairs. We use Knowledge Embedded Routing Network (KERN) as our baseline model, extend the work with our algorithm, and show comparable results on the recent state-of-the-art algorithms.
Make Bipedal Robots Learn How to Imitate
May 15, 2021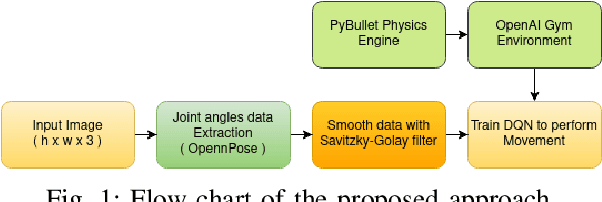
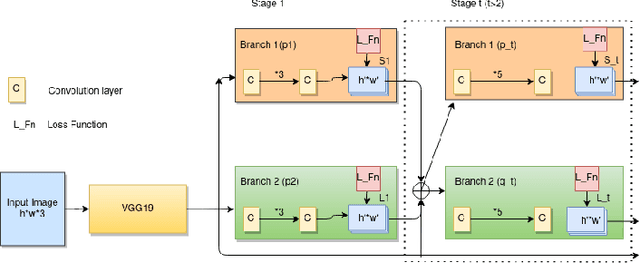

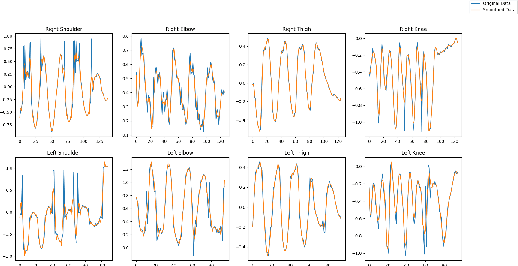
Bipedal robots do not perform well as humans since they do not learn to walk like we do. In this paper we propose a method to train a bipedal robot to perform some basic movements with the help of imitation learning (IL) in which an instructor will perform the movement and the robot will try to mimic the instructor movement. To the best of our knowledge, this is the first time we train the robot to perform movements with a single video of the instructor and as the training is done based on joint angles the robot will keep its joint angles always in physical limits which in return help in faster training. The joints of the robot are identified by OpenPose architecture and then joint angle data is extracted with the help of angle between three points resulting in a noisy solution. We smooth the data using Savitzky-Golay filter and preserve the Simulatore data anatomy. An ingeniously written Deep Q Network (DQN) is trained with experience replay to make the robot learn to perform the movements as similar as the instructor. The implementation of the paper is made publicly available.