 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHorizonWeaver: Generalizable Multi-Level Semantic Editing for Driving Scenes
Apr 06, 2026Ensuring safety in autonomous driving requires scalable generation of realistic, controllable driving scenes beyond what real-world testing provides. Yet existing instruction guided image editors, trained on object-centric or artistic data, struggle with dense, safety-critical driving layouts. We propose HorizonWeaver, which tackles three fundamental challenges in driving scene editing: (1) multi-level granularity, requiring coherent object- and scene-level edits in dense environments; (2) rich high-level semantics, preserving diverse objects while following detailed instructions; and (3) ubiquitous domain shifts, handling changes in climate, layout, and traffic across unseen environments. The core of HorizonWeaver is a set of complementary contributions across data, model, and training: (1) Data: Large-scale dataset generation, where we build a paired real/synthetic dataset from Boreas, nuScenes, and Argoverse2 to improve generalization; (2) Model: Language-Guided Masks for fine-grained editing, where semantics-enriched masks and prompts enable precise, language-guided edits; and (3) Training: Content preservation and instruction alignment, where joint losses enforce scene consistency and instruction fidelity. Together, HorizonWeaver provides a scalable framework for photorealistic, instruction-driven editing of complex driving scenes, collecting 255K images across 13 editing categories and outperforming prior methods in L1, CLIP, and DINO metrics, achieving +46.4% user preference and improving BEV segmentation IoU by +33%. Project page: https://msoroco.github.io/horizonweaver/
HorizonForge: Driving Scene Editing with Any Trajectories and Any Vehicles
Feb 24, 2026Controllable driving scene generation is critical for realistic and scalable autonomous driving simulation, yet existing approaches struggle to jointly achieve photorealism and precise control. We introduce HorizonForge, a unified framework that reconstructs scenes as editable Gaussian Splats and Meshes, enabling fine-grained 3D manipulation and language-driven vehicle insertion. Edits are rendered through a noise-aware video diffusion process that enforces spatial and temporal consistency, producing diverse scene variations in a single feed-forward pass without per-trajectory optimization. To standardize evaluation, we further propose HorizonSuite, a comprehensive benchmark spanning ego- and agent-level editing tasks such as trajectory modifications and object manipulation. Extensive experiments show that Gaussian-Mesh representation delivers substantially higher fidelity than alternative 3D representations, and that temporal priors from video diffusion are essential for coherent synthesis. Combining these findings, HorizonForge establishes a simple yet powerful paradigm for photorealistic, controllable driving simulation, achieving an 83.4% user-preference gain and a 25.19% FID improvement over the second best state-of-the-art method. Project page: https://horizonforge.github.io/ .
LangDriveCTRL: Natural Language Controllable Driving Scene Editing with Multi-modal Agents
Dec 19, 2025


LangDriveCTRL is a natural-language-controllable framework for editing real-world driving videos to synthesize diverse traffic scenarios. It leverages explicit 3D scene decomposition to represent driving videos as a scene graph, containing static background and dynamic objects. To enable fine-grained editing and realism, it incorporates an agentic pipeline in which an Orchestrator transforms user instructions into execution graphs that coordinate specialized agents and tools. Specifically, an Object Grounding Agent establishes correspondence between free-form text descriptions and target object nodes in the scene graph; a Behavior Editing Agent generates multi-object trajectories from language instructions; and a Behavior Reviewer Agent iteratively reviews and refines the generated trajectories. The edited scene graph is rendered and then refined using a video diffusion tool to address artifacts introduced by object insertion and significant view changes. LangDriveCTRL supports both object node editing (removal, insertion and replacement) and multi-object behavior editing from a single natural-language instruction. Quantitatively, it achieves nearly $2\times$ higher instruction alignment than the previous SoTA, with superior structural preservation, photorealism, and traffic realism. Project page is available at: https://yunhe24.github.io/langdrivectrl/.
What if Eye...? Computationally Recreating Vision Evolution
Jan 25, 2025



Vision systems in nature show remarkable diversity, from simple light-sensitive patches to complex camera eyes with lenses. While natural selection has produced these eyes through countless mutations over millions of years, they represent just one set of realized evolutionary paths. Testing hypotheses about how environmental pressures shaped eye evolution remains challenging since we cannot experimentally isolate individual factors. Computational evolution offers a way to systematically explore alternative trajectories. Here we show how environmental demands drive three fundamental aspects of visual evolution through an artificial evolution framework that co-evolves both physical eye structure and neural processing in embodied agents. First, we demonstrate computational evidence that task specific selection drives bifurcation in eye evolution - orientation tasks like navigation in a maze leads to distributed compound-type eyes while an object discrimination task leads to the emergence of high-acuity camera-type eyes. Second, we reveal how optical innovations like lenses naturally emerge to resolve fundamental tradeoffs between light collection and spatial precision. Third, we uncover systematic scaling laws between visual acuity and neural processing, showing how task complexity drives coordinated evolution of sensory and computational capabilities. Our work introduces a novel paradigm that illuminates evolutionary principles shaping vision by creating targeted single-player games where embodied agents must simultaneously evolve visual systems and learn complex behaviors. Through our unified genetic encoding framework, these embodied agents serve as next-generation hypothesis testing machines while providing a foundation for designing manufacturable bio-inspired vision systems.
DecentNeRFs: Decentralized Neural Radiance Fields from Crowdsourced Images
Mar 28, 2024Neural radiance fields (NeRFs) show potential for transforming images captured worldwide into immersive 3D visual experiences. However, most of this captured visual data remains siloed in our camera rolls as these images contain personal details. Even if made public, the problem of learning 3D representations of billions of scenes captured daily in a centralized manner is computationally intractable. Our approach, DecentNeRF, is the first attempt at decentralized, crowd-sourced NeRFs that require $\sim 10^4\times$ less server computing for a scene than a centralized approach. Instead of sending the raw data, our approach requires users to send a 3D representation, distributing the high computation cost of training centralized NeRFs between the users. It learns photorealistic scene representations by decomposing users' 3D views into personal and global NeRFs and a novel optimally weighted aggregation of only the latter. We validate the advantage of our approach to learn NeRFs with photorealism and minimal server computation cost on structured synthetic and real-world photo tourism datasets. We further analyze how secure aggregation of global NeRFs in DecentNeRF minimizes the undesired reconstruction of personal content by the server.
A MEMS-based Foveating LIDAR to enable Real-time Adaptive Depth Sensing
Mar 21, 2020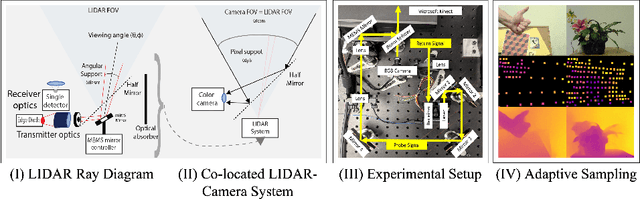


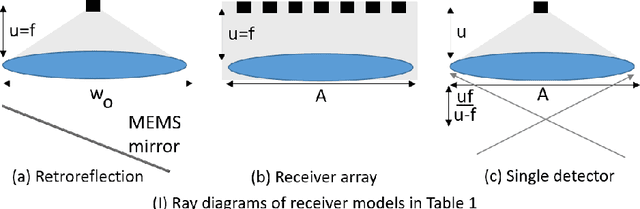
Most active depth sensors sample their visual field using a fixed pattern, decided by accuracy, speed and cost trade-offs, rather than scene content. However, a number of recent works have demonstrated that adapting measurement patterns to scene content can offer significantly better trade-offs. We propose a hardware LIDAR design that allows flexible real-time measurements according to dynamically specified measurement patterns. Our flexible depth sensor design consists of a controllable scanning LIDAR that can foveate, or increase resolution in regions of interest, and that can fully leverage the power of adaptive depth sensing. We describe our optical setup and calibration, which enables fast sparse depth measurements using a scanning MEMS (micro-electro mechanical) mirror. We validate the efficacy of our prototype LIDAR design by testing on over 75 static and dynamic scenes spanning a range of environments. We also show CNN-based depth-map completion of sparse measurements obtained by our sensor. Our experiments show that our sensor can realize adaptive depth sensing systems.