 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Nonconvex Optimization with Guaranteed Privacy and Accuracy
Dec 14, 2022



Privacy protection and nonconvexity are two challenging problems in decentralized optimization and learning involving sensitive data. Despite some recent advances addressing each of the two problems separately, no results have been reported that have theoretical guarantees on both privacy protection and saddle/maximum avoidance in decentralized nonconvex optimization. We propose a new algorithm for decentralized nonconvex optimization that can enable both rigorous differential privacy and saddle/maximum avoiding performance. The new algorithm allows the incorporation of persistent additive noise to enable rigorous differential privacy for data samples, gradients, and intermediate optimization variables without losing provable convergence, and thus circumventing the dilemma of trading accuracy for privacy in differential privacy design. More interestingly, the algorithm is theoretically proven to be able to efficiently { guarantee accuracy by avoiding} convergence to local maxima and saddle points, which has not been reported before in the literature on decentralized nonconvex optimization. The algorithm is efficient in both communication (it only shares one variable in each iteration) and computation (it is encryption-free), and hence is promising for large-scale nonconvex optimization and learning involving high-dimensional optimization parameters. Numerical experiments for both a decentralized estimation problem and an Independent Component Analysis (ICA) problem confirm the effectiveness of the proposed approach.
Accelerating RNN-T Training and Inference Using CTC guidance
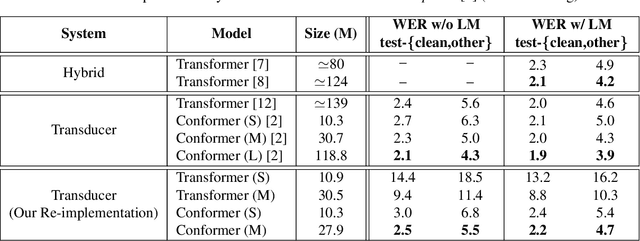
Oct 29, 2022We propose a novel method to accelerate training and inference process of recurrent neural network transducer (RNN-T) based on the guidance from a co-trained connectionist temporal classification (CTC) model. We made a key assumption that if an encoder embedding frame is classified as a blank frame by the CTC model, it is likely that this frame will be aligned to blank for all the partial alignments or hypotheses in RNN-T and it can be discarded from the decoder input. We also show that this frame reduction operation can be applied in the middle of the encoder, which result in significant speed up for the training and inference in RNN-T. We further show that the CTC alignment, a by-product of the CTC decoder, can also be used to perform lattice reduction for RNN-T during training. Our method is evaluated on the Librispeech and SpeechStew tasks. We demonstrate that the proposed method is able to accelerate the RNN-T inference by 2.2 times with similar or slightly better word error rates (WER).
Quantization enabled Privacy Protection in Decentralized Stochastic Optimization
Aug 07, 2022
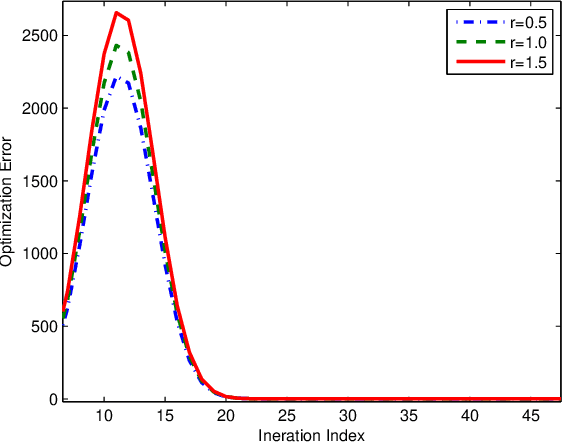
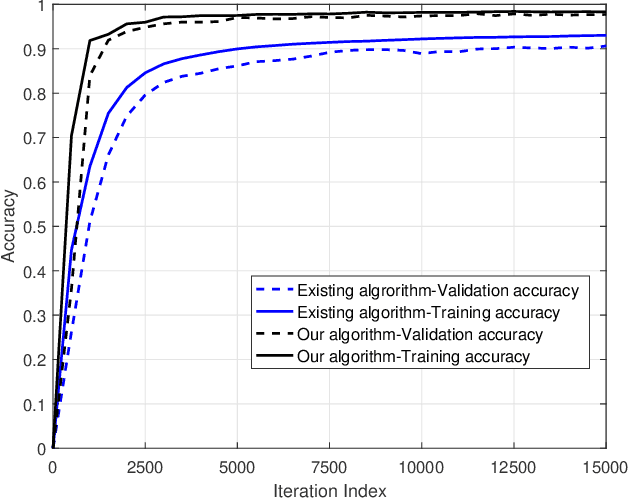
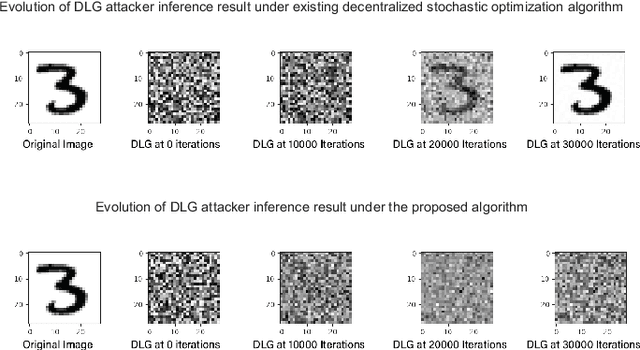
By enabling multiple agents to cooperatively solve a global optimization problem in the absence of a central coordinator, decentralized stochastic optimization is gaining increasing attention in areas as diverse as machine learning, control, and sensor networks. Since the associated data usually contain sensitive information, such as user locations and personal identities, privacy protection has emerged as a crucial need in the implementation of decentralized stochastic optimization. In this paper, we propose a decentralized stochastic optimization algorithm that is able to guarantee provable convergence accuracy even in the presence of aggressive quantization errors that are proportional to the amplitude of quantization inputs. The result applies to both convex and non-convex objective functions, and enables us to exploit aggressive quantization schemes to obfuscate shared information, and hence enables privacy protection without losing provable optimization accuracy. In fact, by using a {stochastic} ternary quantization scheme, which quantizes any value to three numerical levels, we achieve quantization-based rigorous differential privacy in decentralized stochastic optimization, which has not been reported before. In combination with the presented quantization scheme, the proposed algorithm ensures, for the first time, rigorous differential privacy in decentralized stochastic optimization without losing provable convergence accuracy. Simulation results for a distributed estimation problem as well as numerical experiments for decentralized learning on a benchmark machine learning dataset confirm the effectiveness of the proposed approach.
Decentralized Stochastic Optimization with Inherent Privacy Protection
May 08, 2022
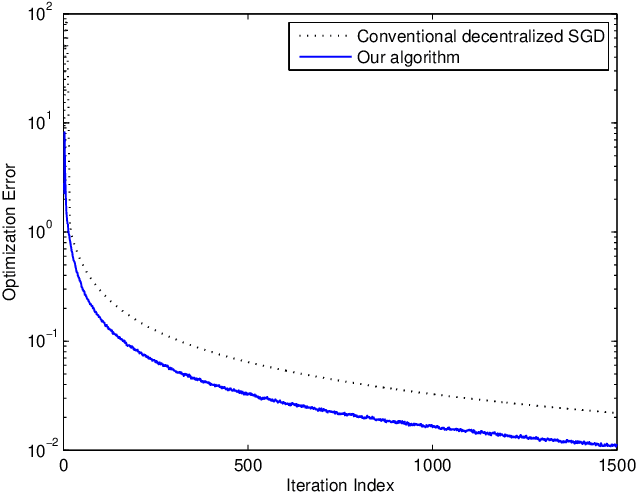
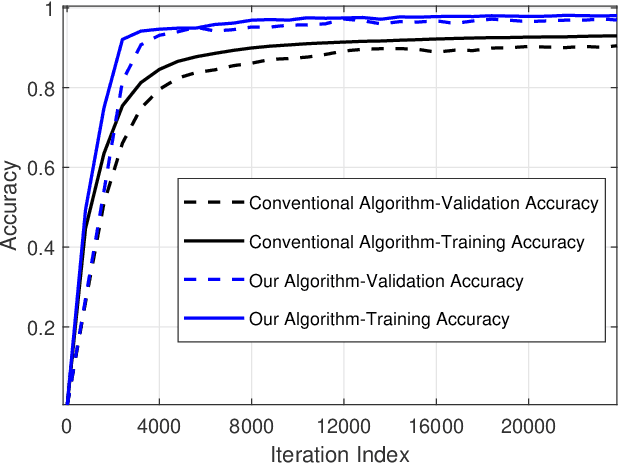

Decentralized stochastic optimization is the basic building block of modern collaborative machine learning, distributed estimation and control, and large-scale sensing. Since involved data usually contain sensitive information like user locations, healthcare records and financial transactions, privacy protection has become an increasingly pressing need in the implementation of decentralized stochastic optimization algorithms. In this paper, we propose a decentralized stochastic gradient descent algorithm which is embedded with inherent privacy protection for every participating agent against other participating agents and external eavesdroppers. This proposed algorithm builds in a dynamics based gradient-obfuscation mechanism to enable privacy protection without compromising optimization accuracy, which is in significant difference from differential-privacy based privacy solutions for decentralized optimization that have to trade optimization accuracy for privacy. The dynamics based privacy approach is encryption-free, and hence avoids incurring heavy communication or computation overhead, which is a common problem with encryption based privacy solutions for decentralized stochastic optimization. Besides rigorously characterizing the convergence performance of the proposed decentralized stochastic gradient descent algorithm under both convex objective functions and non-convex objective functions, we also provide rigorous information-theoretic analysis of its strength of privacy protection. Simulation results for a distributed estimation problem as well as numerical experiments for decentralized learning on a benchmark machine learning dataset confirm the effectiveness of the proposed approach.
Unsupervised Data Selection via Discrete Speech Representation for ASR
Apr 05, 2022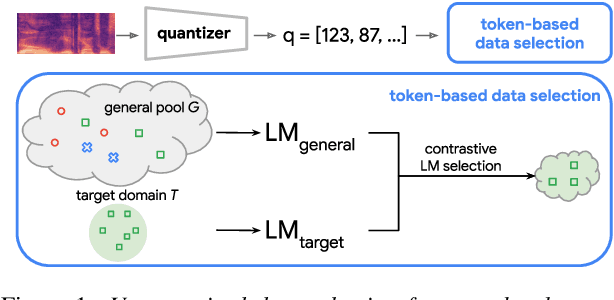


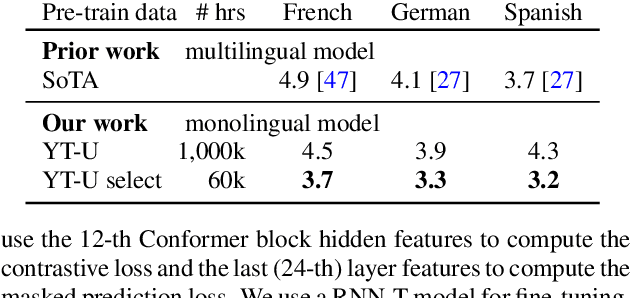
Self-supervised learning of speech representations has achieved impressive results in improving automatic speech recognition (ASR). In this paper, we show that data selection is important for self-supervised learning. We propose a simple and effective unsupervised data selection method which selects acoustically similar speech to a target domain. It takes the discrete speech representation available in common self-supervised learning frameworks as input, and applies a contrastive data selection method on the discrete tokens. Through extensive empirical studies we show that our proposed method reduces the amount of required pre-training data and improves the downstream ASR performance. Pre-training on a selected subset of 6% of the general data pool results in 11.8% relative improvements in LibriSpeech test-other compared to pre-training on the full set. On Multilingual LibriSpeech French, German, and Spanish test sets, selecting 6% data for pre-training reduces word error rate by more than 15% relatively compared to the full set, and achieves competitive results compared to current state-of-the-art performances.
BigSSL: Exploring the Frontier of Large-Scale Semi-Supervised Learning for Automatic Speech Recognition
Oct 01, 2021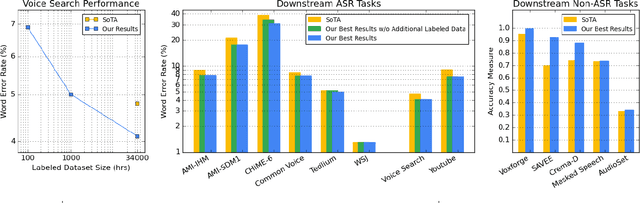
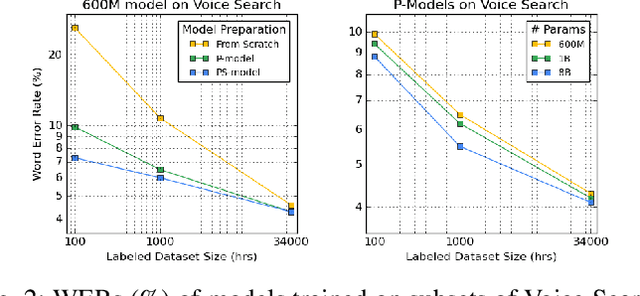
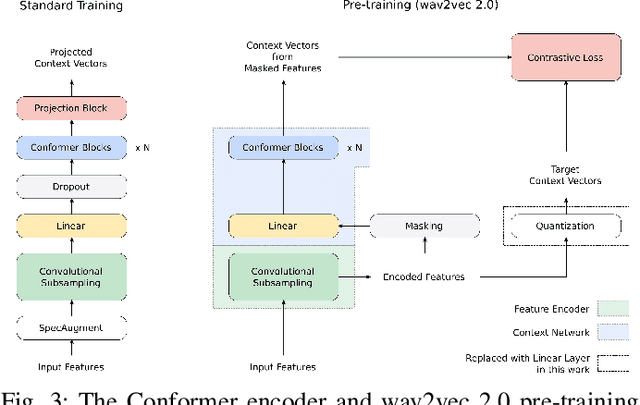
We summarize the results of a host of efforts using giant automatic speech recognition (ASR) models pre-trained using large, diverse unlabeled datasets containing approximately a million hours of audio. We find that the combination of pre-training, self-training and scaling up model size greatly increases data efficiency, even for extremely large tasks with tens of thousands of hours of labeled data. In particular, on an ASR task with 34k hours of labeled data, by fine-tuning an 8 billion parameter pre-trained Conformer model we can match state-of-the-art (SoTA) performance with only 3% of the training data and significantly improve SoTA with the full training set. We also report on the universal benefits gained from using big pre-trained and self-trained models for a large set of downstream tasks that cover a wide range of speech domains and span multiple orders of magnitudes of dataset sizes, including obtaining SoTA performance on many public benchmarks. In addition, we utilize the learned representation of pre-trained networks to achieve SoTA results on non-ASR tasks.
Streaming Attention-Based Models with Augmented Memory for End-to-End Speech Recognition
Nov 03, 2020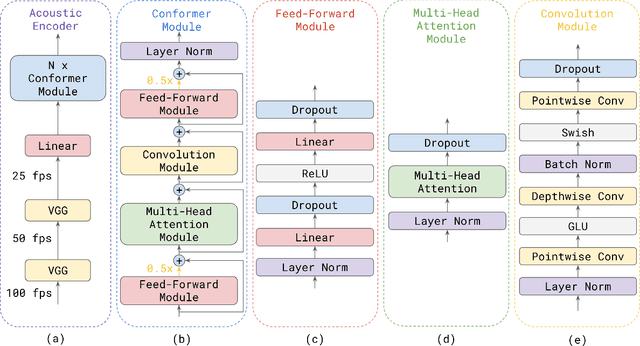
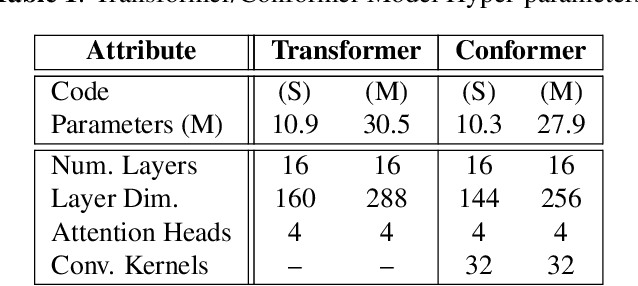
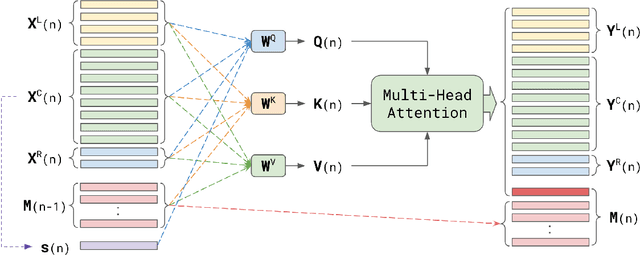
Attention-based models have been gaining popularity recently for their strong performance demonstrated in fields such as machine translation and automatic speech recognition. One major challenge of attention-based models is the need of access to the full sequence and the quadratically growing computational cost concerning the sequence length. These characteristics pose challenges, especially for low-latency scenarios, where the system is often required to be streaming. In this paper, we build a compact and streaming speech recognition system on top of the end-to-end neural transducer architecture with attention-based modules augmented with convolution. The proposed system equips the end-to-end models with the streaming capability and reduces the large footprint from the streaming attention-based model using augmented memory. On the LibriSpeech dataset, our proposed system achieves word error rates 2.7% on test-clean and 5.8% on test-other, to our best knowledge the lowest among streaming approaches reported so far.
Streaming Simultaneous Speech Translation with Augmented Memory Transformer
Oct 30, 2020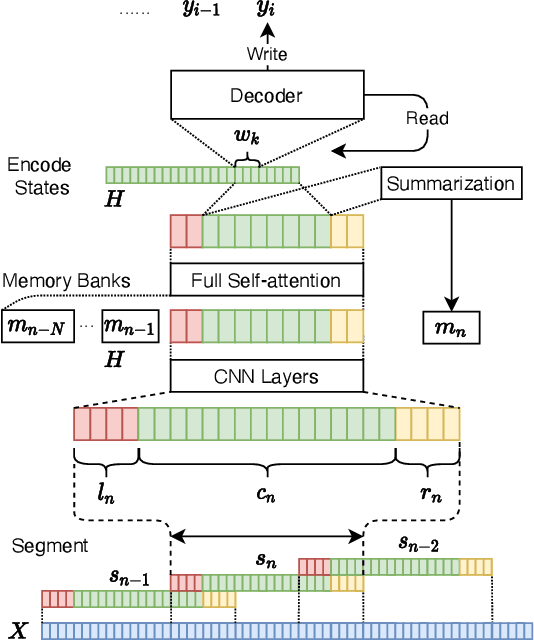
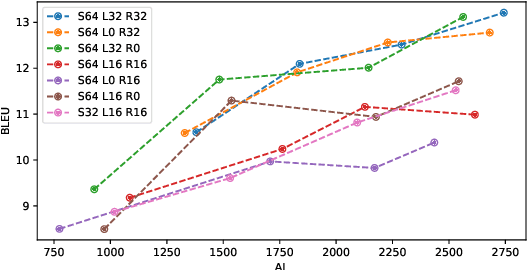
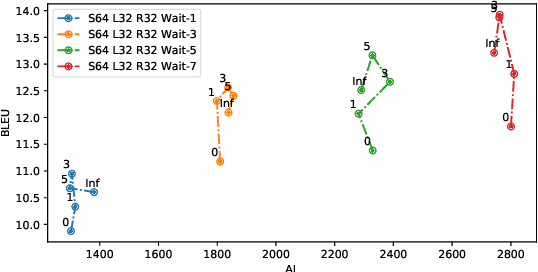
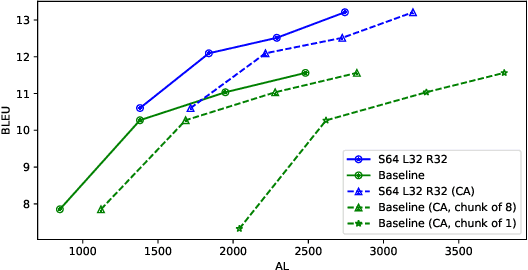
Transformer-based models have achieved state-of-the-art performance on speech translation tasks. However, the model architecture is not efficient enough for streaming scenarios since self-attention is computed over an entire input sequence and the computational cost grows quadratically with the length of the input sequence. Nevertheless, most of the previous work on simultaneous speech translation, the task of generating translations from partial audio input, ignores the time spent in generating the translation when analyzing the latency. With this assumption, a system may have good latency quality trade-offs but be inapplicable in real-time scenarios. In this paper, we focus on the task of streaming simultaneous speech translation, where the systems are not only capable of translating with partial input but are also able to handle very long or continuous input. We propose an end-to-end transformer-based sequence-to-sequence model, equipped with an augmented memory transformer encoder, which has shown great success on the streaming automatic speech recognition task with hybrid or transducer-based models. We conduct an empirical evaluation of the proposed model on segment, context and memory sizes and we compare our approach to a transformer with a unidirectional mask.
Transformer in action: a comparative study of transformer-based acoustic models for large scale speech recognition applications
Oct 29, 2020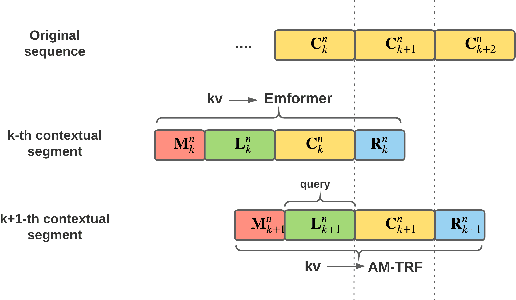
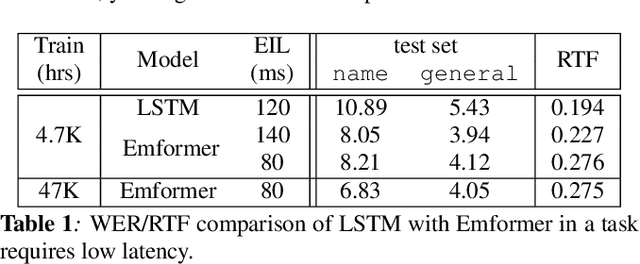
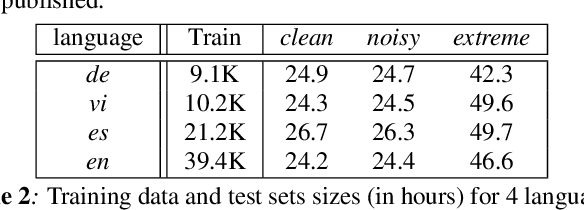
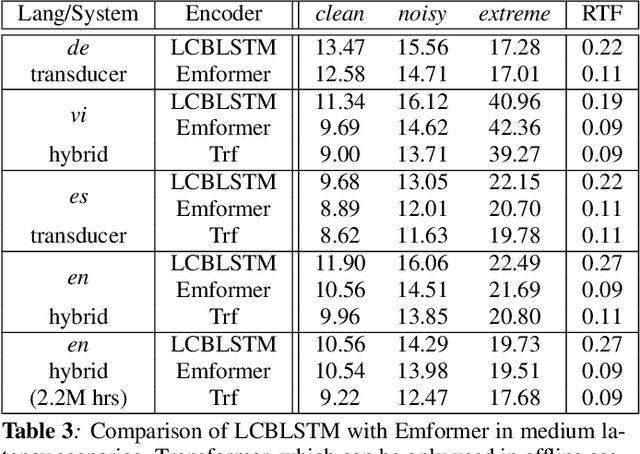
In this paper, we summarize the application of transformer and its streamable variant, Emformer based acoustic model for large scale speech recognition applications. We compare the transformer based acoustic models with their LSTM counterparts on industrial scale tasks. Specifically, we compare Emformer with latency-controlled BLSTM (LCBLSTM) on medium latency tasks and LSTM on low latency tasks. On a low latency voice assistant task, Emformer gets 24% to 26% relative word error rate reductions (WERRs). For medium latency scenarios, comparing with LCBLSTM with similar model size and latency, Emformer gets significant WERR across four languages in video captioning datasets with 2-3 times inference real-time factors reduction.
Emformer: Efficient Memory Transformer Based Acoustic Model For Low Latency Streaming Speech Recognition
Oct 29, 2020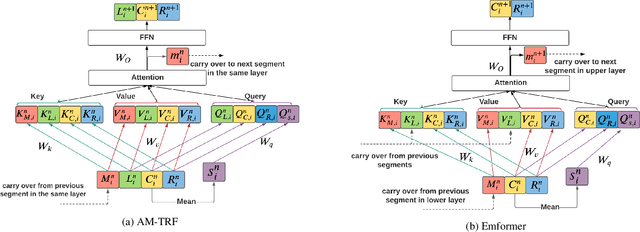
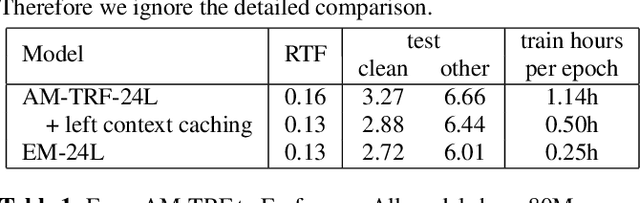
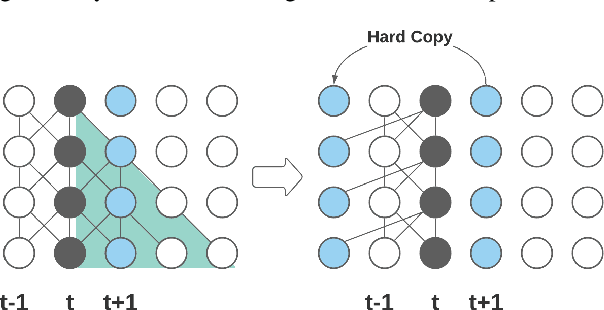
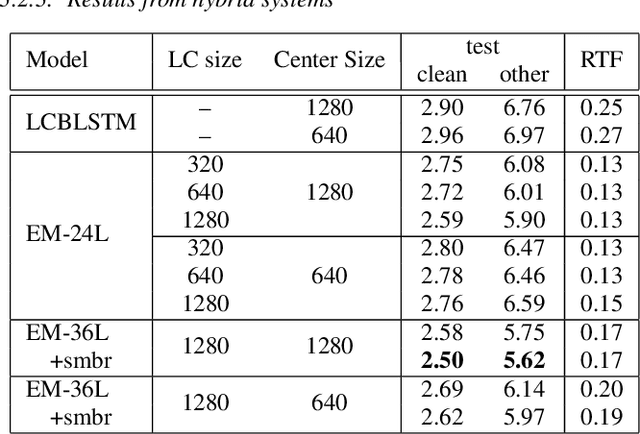
This paper proposes an efficient memory transformer Emformer for low latency streaming speech recognition. In Emformer, the long-range history context is distilled into an augmented memory bank to reduce self-attention's computation complexity. A cache mechanism saves the computation for the key and value in self-attention for the left context. Emformer applies a parallelized block processing in training to support low latency models. We carry out experiments on benchmark LibriSpeech data. Under average latency of 960 ms, Emformer gets WER $2.50\%$ on test-clean and $5.62\%$ on test-other. Comparing with a strong baseline augmented memory transformer (AM-TRF), Emformer gets $4.6$ folds training speedup and $18\%$ relative real-time factor (RTF) reduction in decoding with relative WER reduction $17\%$ on test-clean and $9\%$ on test-other. For a low latency scenario with an average latency of 80 ms, Emformer achieves WER $3.01\%$ on test-clean and $7.09\%$ on test-other. Comparing with the LSTM baseline with the same latency and model size, Emformer gets relative WER reduction $9\%$ and $16\%$ on test-clean and test-other, respectively.