 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Generative Recommendation for Fusing Semantic and Collaborative Signals
Feb 03, 2026Sequential recommender systems rank relevant items by modeling a user's interaction history and computing the inner product between the resulting user representation and stored item embeddings. To avoid the significant memory overhead of storing large item sets, the generative recommendation paradigm instead models each item as a series of discrete semantic codes. Here, the next item is predicted by an autoregressive model that generates the code sequence corresponding to the predicted item. However, despite promising ranking capabilities on small datasets, these methods have yet to surpass traditional sequential recommenders on large item sets, limiting their adoption in the very scenarios they were designed to address. To resolve this, we propose MSCGRec, a Multimodal Semantic and Collaborative Generative Recommender. MSCGRec incorporates multiple semantic modalities and introduces a novel self-supervised quantization learning approach for images based on the DINO framework. Additionally, MSCGRec fuses collaborative and semantic signals by extracting collaborative features from sequential recommenders and treating them as a separate modality. Finally, we propose constrained sequence learning that restricts the large output space during training to the set of permissible tokens. We empirically demonstrate on three large real-world datasets that MSCGRec outperforms both sequential and generative recommendation baselines and provide an extensive ablation study to validate the impact of each component.
Mitigating Unintended Memorization in Language Models via Alternating Teaching
Oct 13, 2022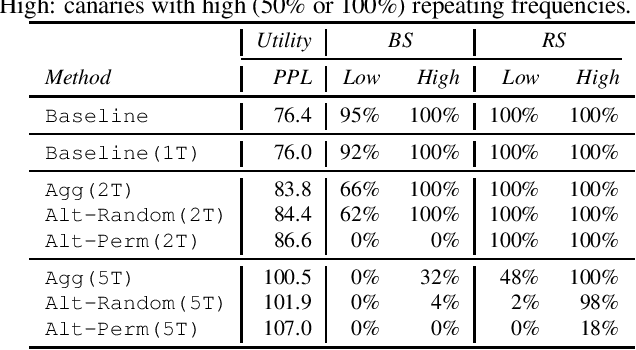
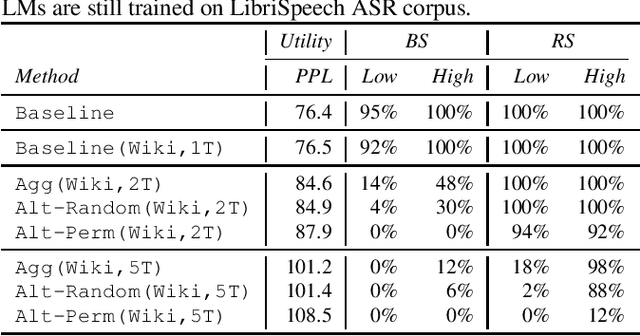
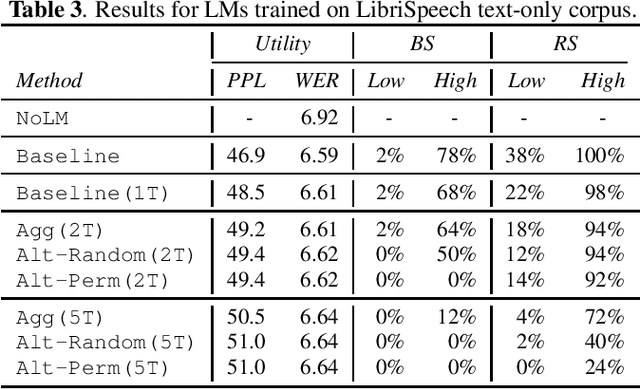
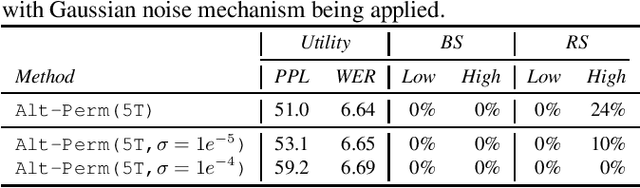
Recent research has shown that language models have a tendency to memorize rare or unique sequences in the training corpora which can thus leak sensitive attributes of user data. We employ a teacher-student framework and propose a novel approach called alternating teaching to mitigate unintended memorization in sequential modeling. In our method, multiple teachers are trained on disjoint training sets whose privacy one wishes to protect, and teachers' predictions supervise the training of a student model in an alternating manner at each time step. Experiments on LibriSpeech datasets show that the proposed method achieves superior privacy-preserving results than other counterparts. In comparison with no prevention for unintended memorization, the overall utility loss is small when training records are sufficient.
Group Personalized Federated Learning
Oct 11, 2022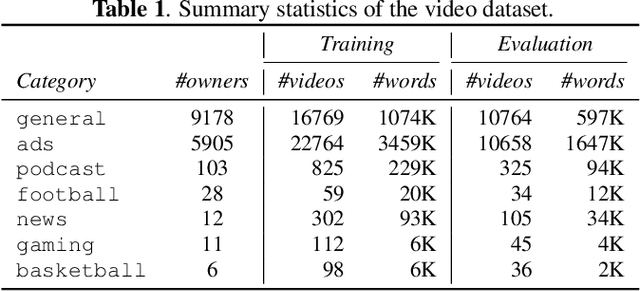
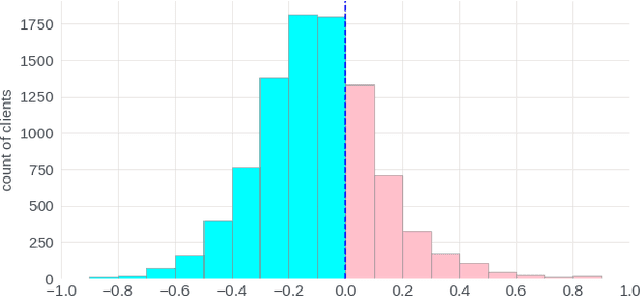

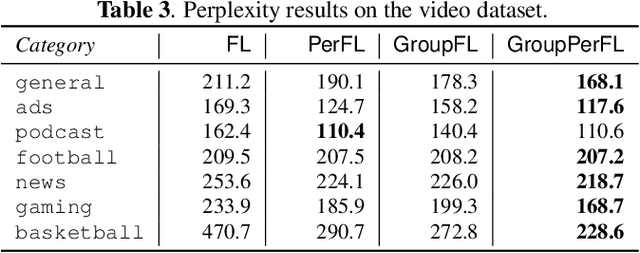
Federated learning (FL) can help promote data privacy by training a shared model in a de-centralized manner on the physical devices of clients. In the presence of highly heterogeneous distributions of local data, personalized FL strategy seeks to mitigate the potential client drift. In this paper, we present the group personalization approach for applications of FL in which there exist inherent partitions among clients that are significantly distinct. In our method, the global FL model is fine-tuned through another FL training process over each homogeneous group of clients, after which each group-specific FL model is further adapted and personalized for any client. The proposed method can be well interpreted from a Bayesian hierarchical modeling perspective. With experiments on two real-world datasets, we demonstrate this approach can achieve superior personalization performance than other FL counterparts.
Modeling Dependent Structure for Utterances in ASR Evaluation
Sep 07, 2022
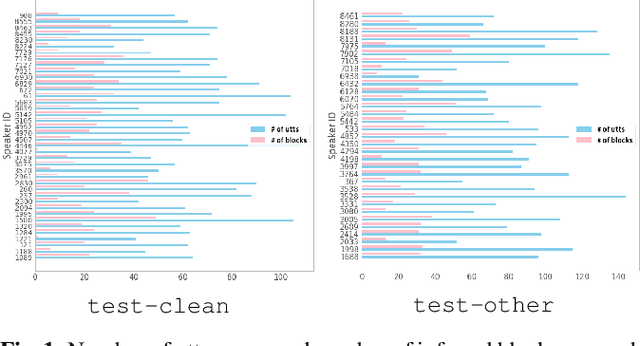
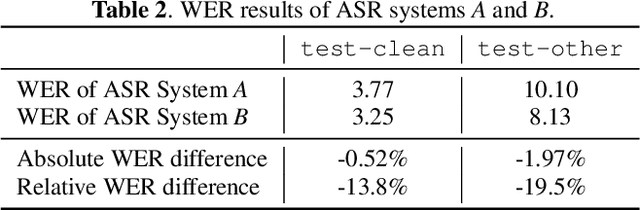
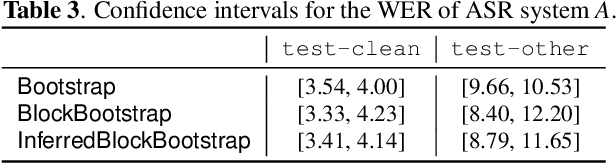
The bootstrap resampling method has been popular for performing significance analysis on word error rate (WER) in automatic speech recognition (ASR) evaluations. To deal with the issue of dependent speech data, the blockwise bootstrap approach is also proposed that by dividing utterances into uncorrelated blocks, it resamples these blocks instead of original data. However, it is always nontrivial to uncover the dependent structure among utterances, which could lead to subjective findings in statistical testing. In this paper, we present graphical lasso based methods to explicitly model such dependency and estimate the independent blocks of utterances in a rigorous way. Then the blockwise bootstrap is applied on top of the inferred blocks. We show that the resulting variance estimator for WER is consistent under mild conditions. We also demonstrate the validity of proposed approach on LibriSpeech data.
Neural-FST Class Language Model for End-to-End Speech Recognition
Jan 31, 2022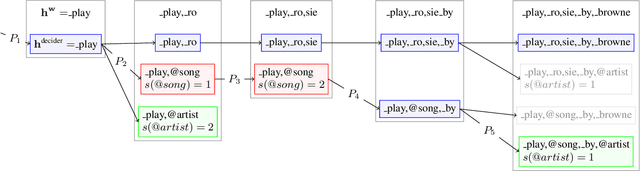
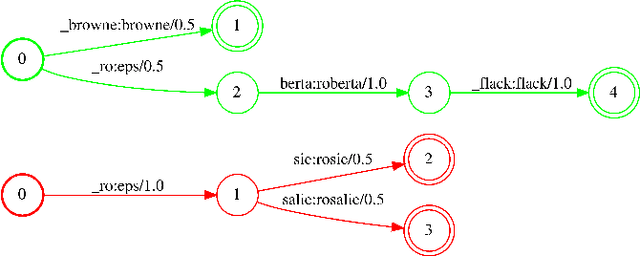
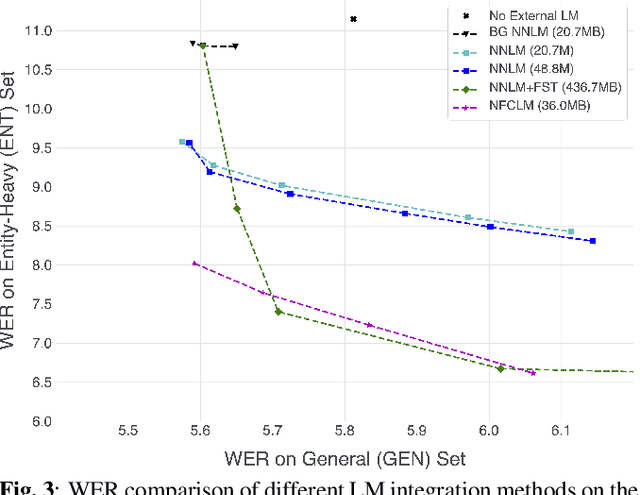
We propose Neural-FST Class Language Model (NFCLM) for end-to-end speech recognition, a novel method that combines neural network language models (NNLMs) and finite state transducers (FSTs) in a mathematically consistent framework. Our method utilizes a background NNLM which models generic background text together with a collection of domain-specific entities modeled as individual FSTs. Each output token is generated by a mixture of these components; the mixture weights are estimated with a separately trained neural decider. We show that NFCLM significantly outperforms NNLM by 15.8% relative in terms of Word Error Rate. NFCLM achieves similar performance as traditional NNLM and FST shallow fusion while being less prone to overbiasing and 12 times more compact, making it more suitable for on-device usage.
Private Language Model Adaptation for Speech Recognition
Sep 28, 2021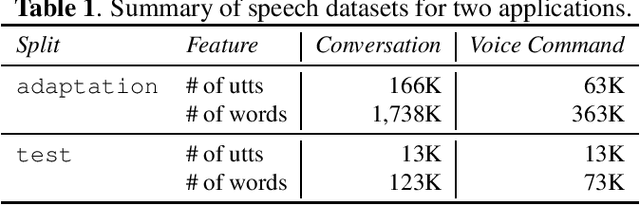
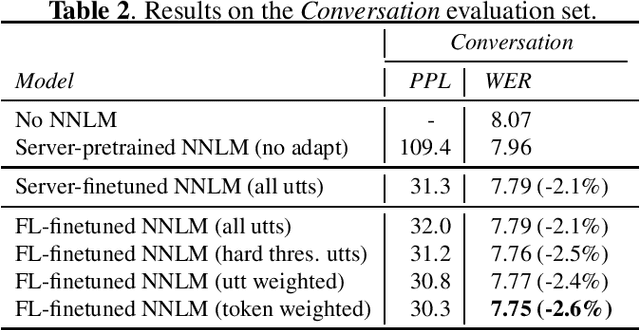
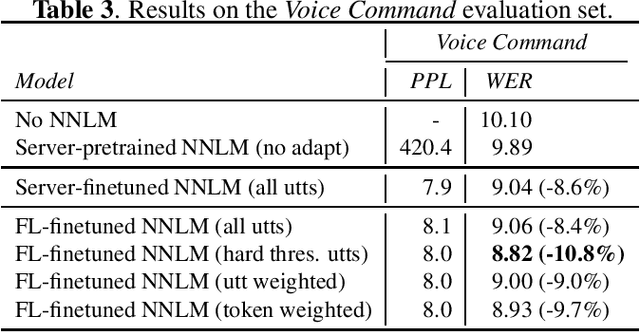
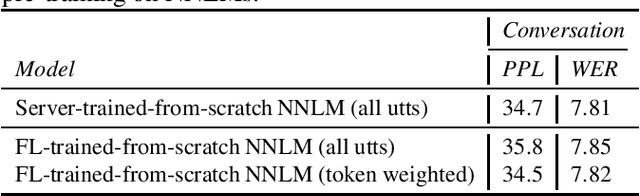
Speech model adaptation is crucial to handle the discrepancy between server-side proxy training data and actual data received on users' local devices. With the use of federated learning (FL), we introduce an efficient approach on continuously adapting neural network language models (NNLMs) on private devices with applications on automatic speech recognition (ASR). To address the potential speech transcription errors in the on-device training corpus, we perform empirical studies on comparing various strategies of leveraging token-level confidence scores to improve the NNLM quality in the FL settings. Experiments show that compared with no model adaptation, the proposed method achieves relative 2.6% and 10.8% word error rate (WER) reductions on two speech evaluation datasets, respectively. We also provide analysis in evaluating privacy guarantees of our presented procedure.
Model-Based Approach for Measuring the Fairness in ASR
Sep 19, 2021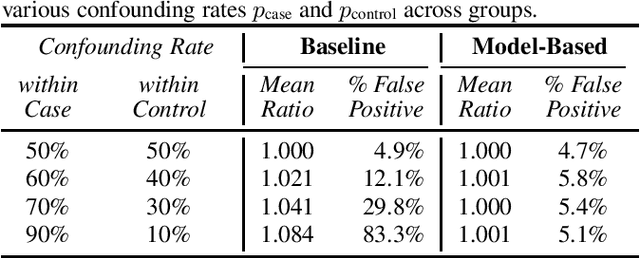
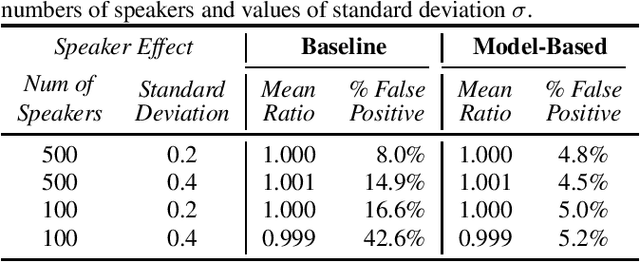
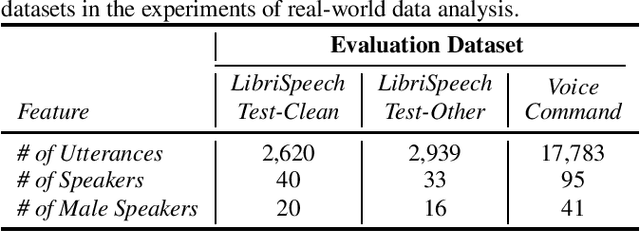
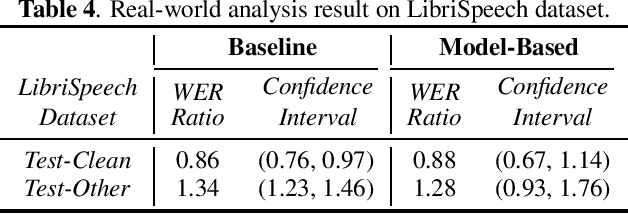
The issue of fairness arises when the automatic speech recognition (ASR) systems do not perform equally well for all subgroups of the population. In any fairness measurement studies for ASR, the open questions of how to control the nuisance factors, how to handle unobserved heterogeneity across speakers, and how to trace the source of any word error rate (WER) gap among different subgroups are especially important - if not appropriately accounted for, incorrect conclusions will be drawn. In this paper, we introduce mixed-effects Poisson regression to better measure and interpret any WER difference among subgroups of interest. Particularly, the presented method can effectively address the three problems raised above and is very flexible to use in practical disparity analyses. We demonstrate the validity of proposed model-based approach on both synthetic and real-world speech data.
On lattice-free boosted MMI training of HMM and CTC-based full-context ASR models
Jul 09, 2021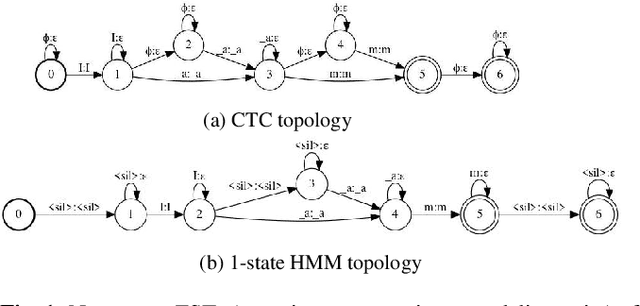
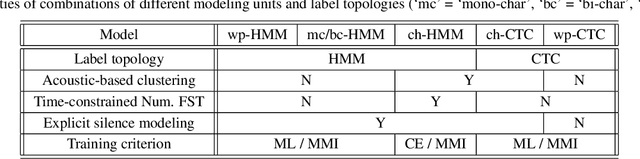
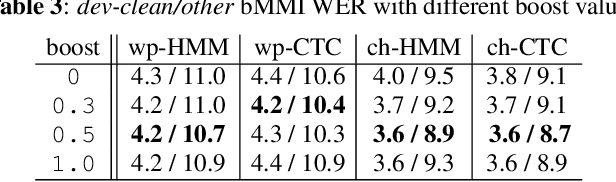
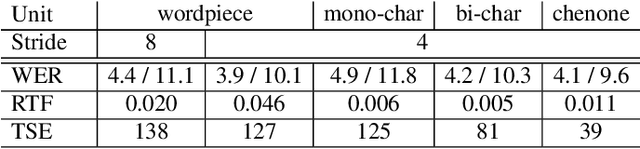
Hybrid automatic speech recognition (ASR) models are typically sequentially trained with CTC or LF-MMI criteria. However, they have vastly different legacies and are usually implemented in different frameworks. In this paper, by decoupling the concepts of modeling units and label topologies and building proper numerator/denominator graphs accordingly, we establish a generalized framework for hybrid acoustic modeling (AM). In this framework, we show that LF-MMI is a powerful training criterion applicable to both limited-context and full-context models, for wordpiece/mono-char/bi-char/chenone units, with both HMM/CTC topologies. From this framework, we propose three novel training schemes: chenone(ch)/wordpiece(wp)-CTC-bMMI, and wordpiece(wp)-HMM-bMMI with different advantages in training performance, decoding efficiency and decoding time-stamp accuracy. The advantages of different training schemes are evaluated comprehensively on Librispeech, and wp-CTC-bMMI and ch-CTC-bMMI are evaluated on two real world ASR tasks to show their effectiveness. Besides, we also show bi-char(bc) HMM-MMI models can serve as better alignment models than traditional non-neural GMM-HMMs.
Federated Marginal Personalization for ASR Rescoring
Dec 01, 2020

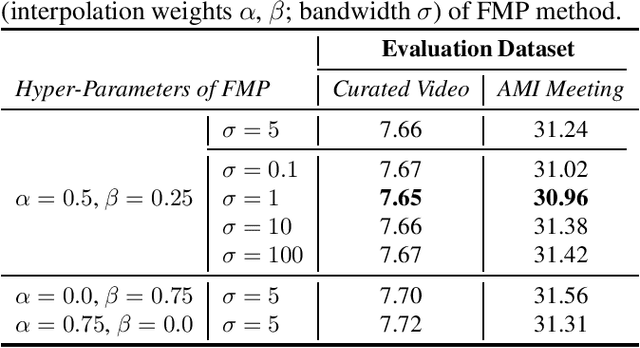
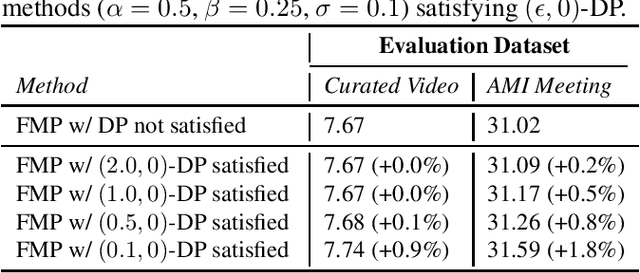
We introduce federated marginal personalization (FMP), a novel method for continuously updating personalized neural network language models (NNLMs) on private devices using federated learning (FL). Instead of fine-tuning the parameters of NNLMs on personal data, FMP regularly estimates global and personalized marginal distributions of words, and adjusts the probabilities from NNLMs by an adaptation factor that is specific to each word. Our presented approach can overcome the limitations of federated fine-tuning and efficiently learn personalized NNLMs on devices. We study the application of FMP on second-pass ASR rescoring tasks. Experiments on two speech evaluation datasets show modest word error rate (WER) reductions. We also demonstrate that FMP could offer reasonable privacy with only a negligible cost in speech recognition accuracy.
Improving N-gram Language Models with Pre-trained Deep Transformer
Nov 22, 2019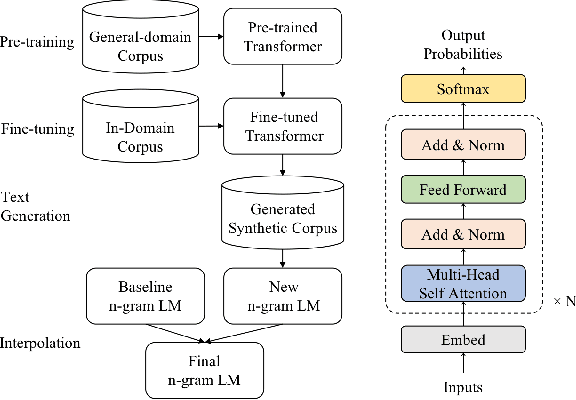

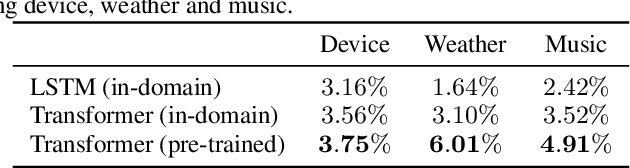
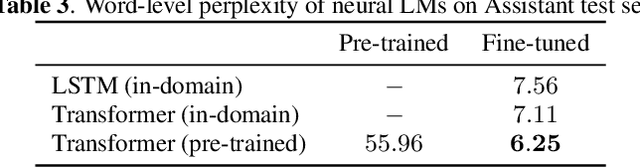
Although n-gram language models (LMs) have been outperformed by the state-of-the-art neural LMs, they are still widely used in speech recognition due to its high efficiency in inference. In this paper, we demonstrate that n-gram LM can be improved by neural LMs through a text generation based data augmentation method. In contrast to previous approaches, we employ a large-scale general domain pre-training followed by in-domain fine-tuning strategy to construct deep Transformer based neural LMs. Large amount of in-domain text data is generated with the well trained deep Transformer to construct new n-gram LMs, which are then interpolated with baseline n-gram systems. Empirical studies on different speech recognition tasks show that the proposed approach can effectively improve recognition accuracy. In particular, our proposed approach brings significant relative word error rate reduction up to 6.0% for domains with limited in-domain data.