 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving N-gram Language Models with Pre-trained Deep Transformer
Paper and Code
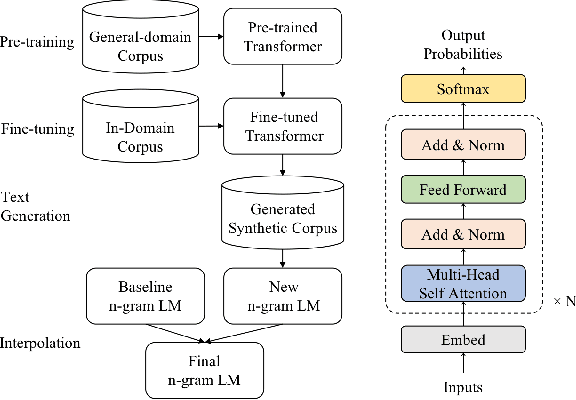

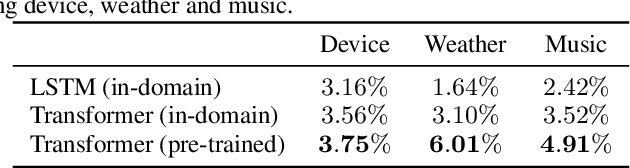
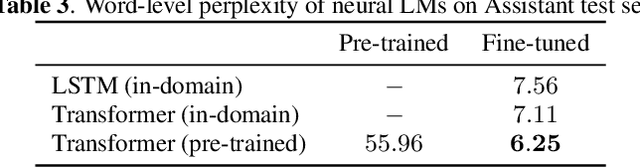
Although n-gram language models (LMs) have been outperformed by the state-of-the-art neural LMs, they are still widely used in speech recognition due to its high efficiency in inference. In this paper, we demonstrate that n-gram LM can be improved by neural LMs through a text generation based data augmentation method. In contrast to previous approaches, we employ a large-scale general domain pre-training followed by in-domain fine-tuning strategy to construct deep Transformer based neural LMs. Large amount of in-domain text data is generated with the well trained deep Transformer to construct new n-gram LMs, which are then interpolated with baseline n-gram systems. Empirical studies on different speech recognition tasks show that the proposed approach can effectively improve recognition accuracy. In particular, our proposed approach brings significant relative word error rate reduction up to 6.0% for domains with limited in-domain data.