 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmformer: Efficient Memory Transformer Based Acoustic Model For Low Latency Streaming Speech Recognition
Paper and Code
Oct 29, 2020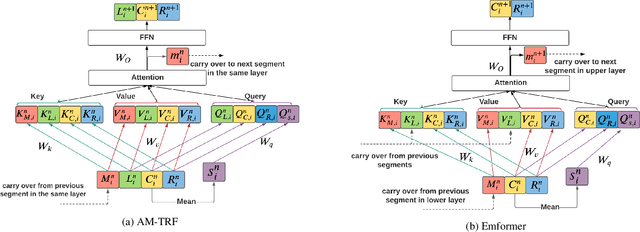
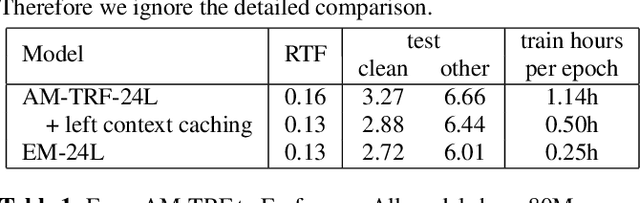
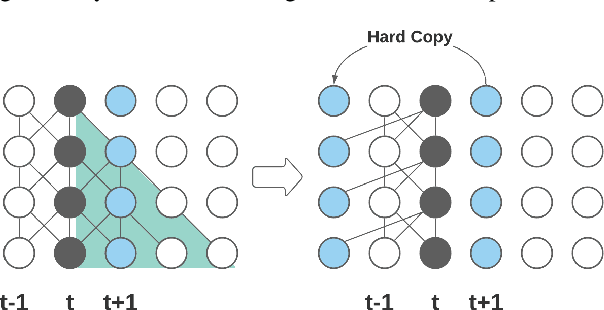
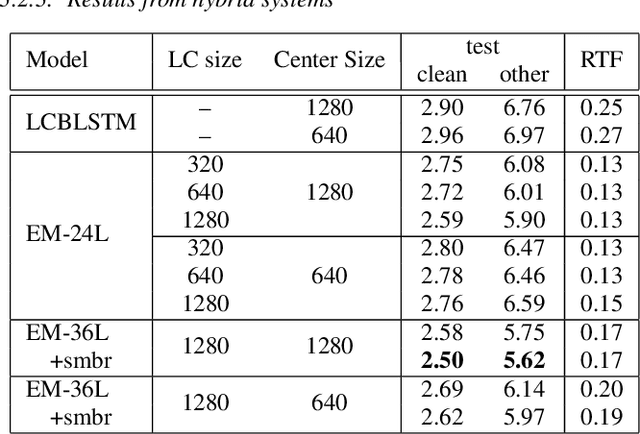
This paper proposes an efficient memory transformer Emformer for low latency streaming speech recognition. In Emformer, the long-range history context is distilled into an augmented memory bank to reduce self-attention's computation complexity. A cache mechanism saves the computation for the key and value in self-attention for the left context. Emformer applies a parallelized block processing in training to support low latency models. We carry out experiments on benchmark LibriSpeech data. Under average latency of 960 ms, Emformer gets WER $2.50\%$ on test-clean and $5.62\%$ on test-other. Comparing with a strong baseline augmented memory transformer (AM-TRF), Emformer gets $4.6$ folds training speedup and $18\%$ relative real-time factor (RTF) reduction in decoding with relative WER reduction $17\%$ on test-clean and $9\%$ on test-other. For a low latency scenario with an average latency of 80 ms, Emformer achieves WER $3.01\%$ on test-clean and $7.09\%$ on test-other. Comparing with the LSTM baseline with the same latency and model size, Emformer gets relative WER reduction $9\%$ and $16\%$ on test-clean and test-other, respectively.