 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualized Streaming End-to-End Speech Recognition with Trie-Based Deep Biasing and Shallow Fusion
Apr 05, 2021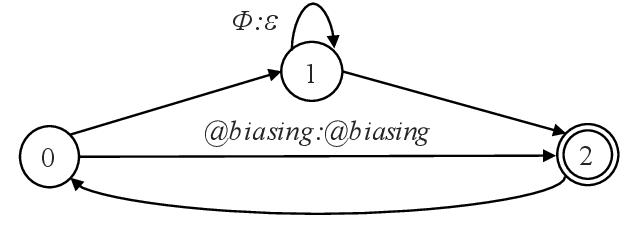
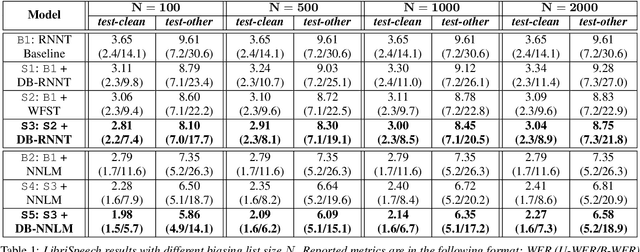
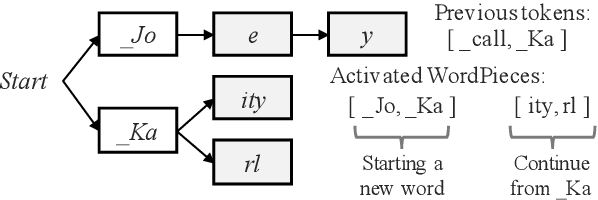
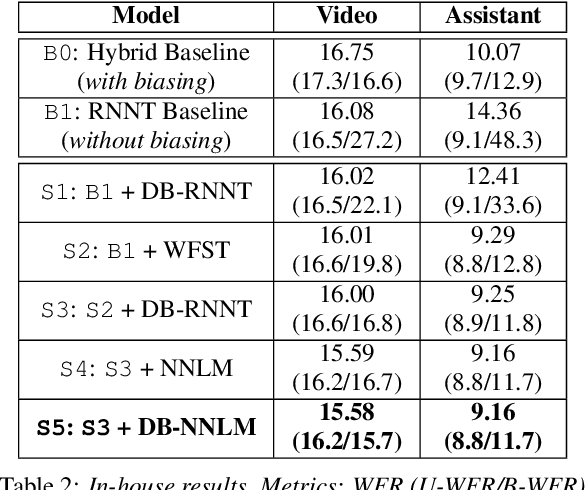
How to leverage dynamic contextual information in end-to-end speech recognition has remained an active research area. Previous solutions to this problem were either designed for specialized use cases that did not generalize well to open-domain scenarios, did not scale to large biasing lists, or underperformed on rare long-tail words. We address these limitations by proposing a novel solution that combines shallow fusion, trie-based deep biasing, and neural network language model contextualization. These techniques result in significant 19.5% relative Word Error Rate improvement over existing contextual biasing approaches and 5.4%-9.3% improvement compared to a strong hybrid baseline on both open-domain and constrained contextualization tasks, where the targets consist of mostly rare long-tail words. Our final system remains lightweight and modular, allowing for quick modification without model re-training.
Contextual RNN-T For Open Domain ASR
Jun 04, 2020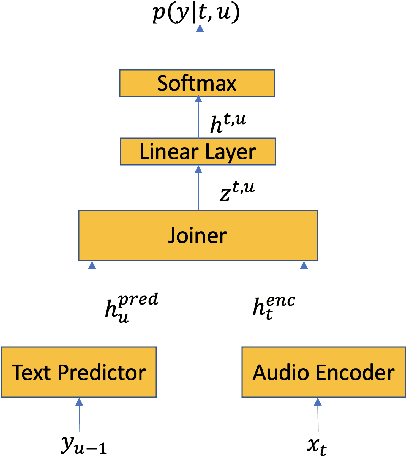
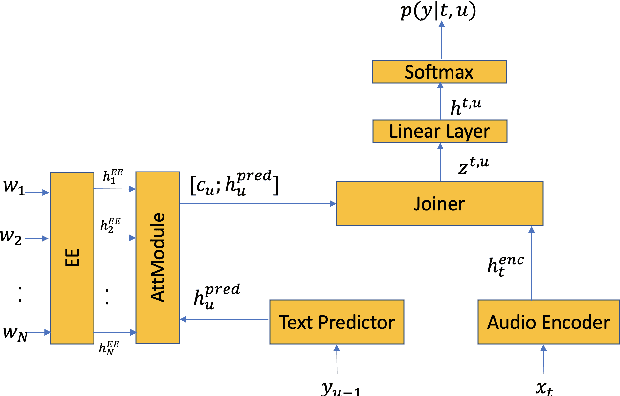
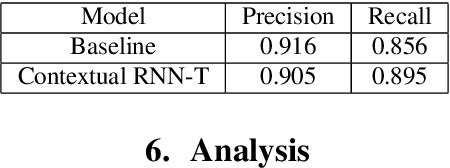

End-to-end (E2E) systems for automatic speech recognition (ASR), such as RNN Transducer (RNN-T) and Listen-Attend-Spell (LAS) blend the individual components of a traditional hybrid ASR system - acoustic model, language model, pronunciation model - into a single neural network. While this has some nice advantages, it limits the system to be trained using only paired audio and text. Because of this, E2E models tend to have difficulties with correctly recognizing rare words that are not frequently seen during training, such as entity names. In this paper, we propose modifications to the RNN-T model that allow the model to utilize additional metadata text with the objective of improving performance on these named entity words. We evaluate our approach on an in-house dataset sampled from de-identified public social media videos, which represent an open domain ASR task. By using an attention model to leverage the contextual metadata that accompanies a video, we observe a relative improvement of about 12% in Word Error Rate on Named Entities (WER-NE) for videos with related metadata.
AIPNet: Generative Adversarial Pre-training of Accent-invariant Networks for End-to-end Speech Recognition
Nov 27, 2019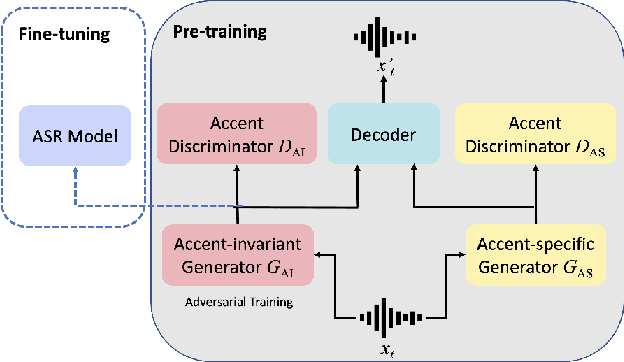
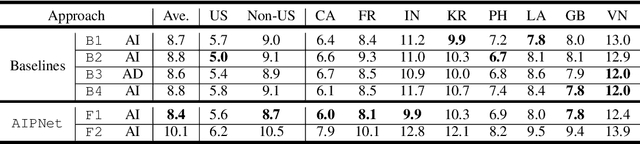
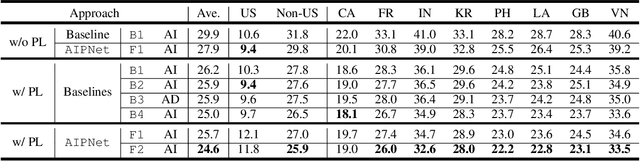
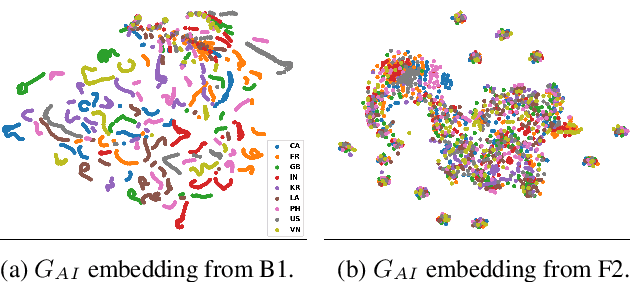
As one of the major sources in speech variability, accents have posed a grand challenge to the robustness of speech recognition systems. In this paper, our goal is to build a unified end-to-end speech recognition system that generalizes well across accents. For this purpose, we propose a novel pre-training framework AIPNet based on generative adversarial nets (GAN) for accent-invariant representation learning: Accent Invariant Pre-training Networks. We pre-train AIPNet to disentangle accent-invariant and accent-specific characteristics from acoustic features through adversarial training on accented data for which transcriptions are not necessarily available. We further fine-tune AIPNet by connecting the accent-invariant module with an attention-based encoder-decoder model for multi-accent speech recognition. In the experiments, our approach is compared against four baselines including both accent-dependent and accent-independent models. Experimental results on 9 English accents show that the proposed approach outperforms all the baselines by 2.3 \sim 4.5% relative reduction on average WER when transcriptions are available in all accents and by 1.6 \sim 6.1% relative reduction when transcriptions are only available in US accent.
RNN-T For Latency Controlled ASR With Improved Beam Search
Nov 05, 2019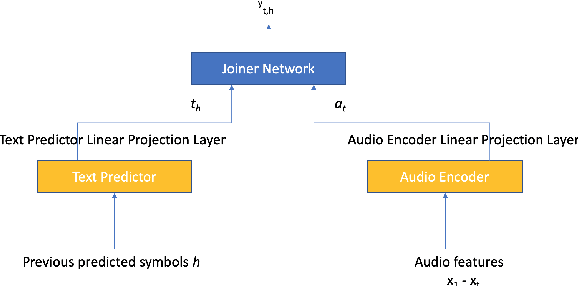

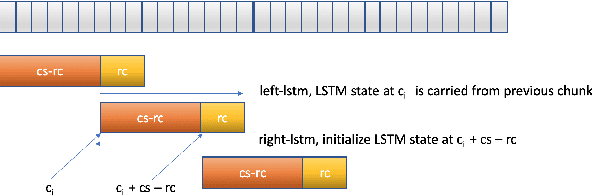
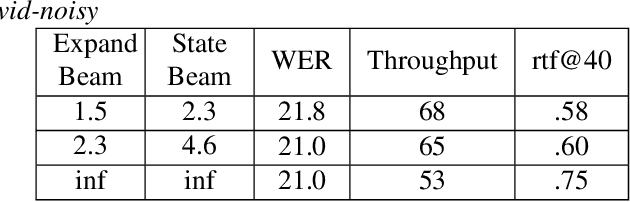
Neural transducer-based systems such as RNN Transducers (RNN-T) for automatic speech recognition (ASR) blend the individual components of a traditional hybrid ASR systems (acoustic model, language model, punctuation model, inverse text normalization) into one single model. This greatly simplifies training and inference and hence makes RNN-T a desirable choice for ASR systems. In this work, we investigate use of RNN-T in applications that require a tune-able latency budget during inference time. We also improved the decoding speed of the originally proposed RNN-T beam search algorithm. We evaluated our proposed system on English videos ASR dataset and show that neural RNN-T models can achieve comparable WER and better computational efficiency compared to a well tuned hybrid ASR baseline.
Transformer-Transducer: End-to-End Speech Recognition with Self-Attention
Oct 28, 2019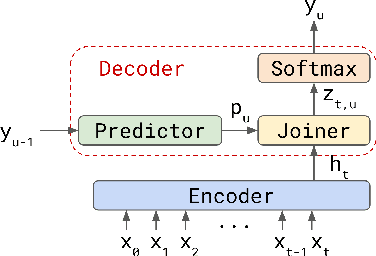
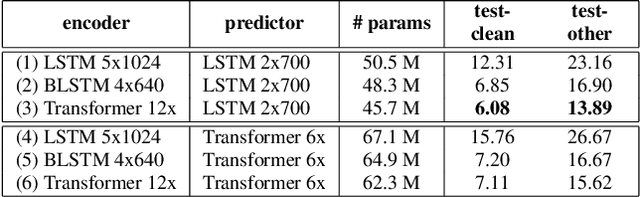
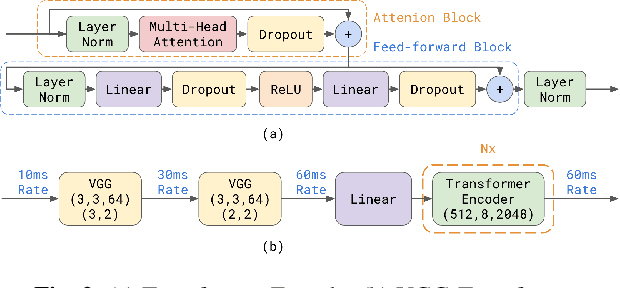
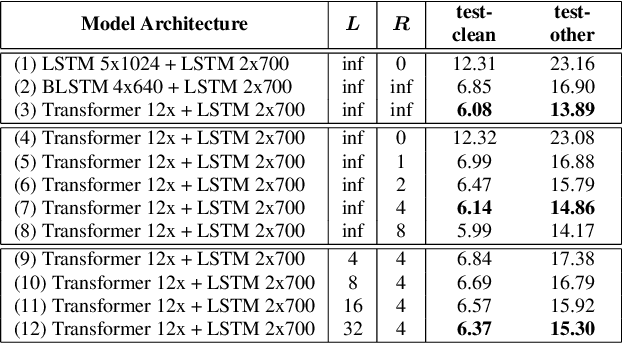
We explore options to use Transformer networks in neural transducer for end-to-end speech recognition. Transformer networks use self-attention for sequence modeling and comes with advantages in parallel computation and capturing contexts. We propose 1) using VGGNet with causal convolution to incorporate positional information and reduce frame rate for efficient inference 2) using truncated self-attention to enable streaming for Transformer and reduce computational complexity. All experiments are conducted on the public LibriSpeech corpus. The proposed Transformer-Transducer outperforms neural transducer with LSTM/BLSTM networks and achieved word error rates of 6.37 % on the test-clean set and 15.30 % on the test-other set, while remaining streamable, compact with 45.7M parameters for the entire system, and computationally efficient with complexity of O(T), where T is input sequence length.
End-to-end contextual speech recognition using class language models and a token passing decoder
Dec 05, 2018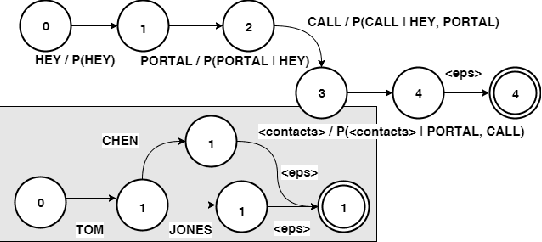
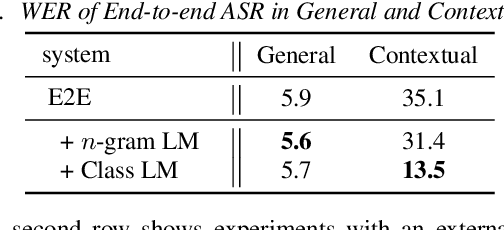
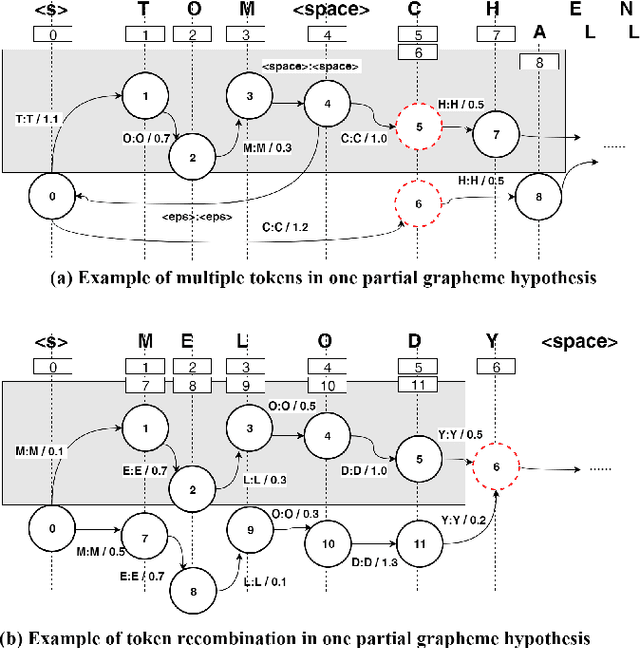
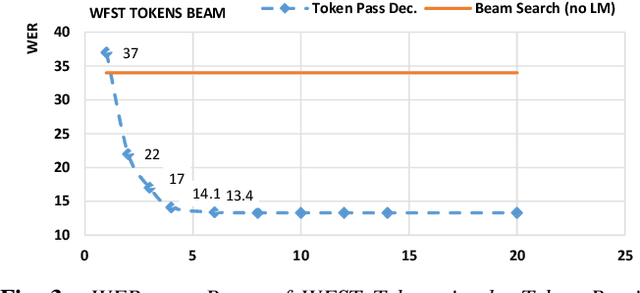
End-to-end modeling (E2E) of automatic speech recognition (ASR) blends all the components of a traditional speech recognition system into a unified model. Although it simplifies training and decoding pipelines, the unified model is hard to adapt when mismatch exists between training and test data. In this work, we focus on contextual speech recognition, which is particularly challenging for E2E models because it introduces significant mismatch between training and test data. To improve the performance in the presence of complex contextual information, we propose to use class-based language models(CLM) that can populate the classes with contextdependent information in real-time. To enable this approach to scale to a large number of class members and minimize search errors, we propose a token passing decoder with efficient token recombination for E2E systems for the first time. We evaluate the proposed system on general and contextual ASR, and achieve relative 62% Word Error Rate(WER) reduction for contextual ASR without hurting performance for general ASR. We show that the proposed method performs well without modification of the decoding hyper-parameters across tasks, making it a general solution for E2E ASR.