 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOVE: Efficient One-Step Diffusion Model for Real-World Video Super-Resolution
May 22, 2025Diffusion models have demonstrated promising performance in real-world video super-resolution (VSR). However, the dozens of sampling steps they require, make inference extremely slow. Sampling acceleration techniques, particularly single-step, provide a potential solution. Nonetheless, achieving one step in VSR remains challenging, due to the high training overhead on video data and stringent fidelity demands. To tackle the above issues, we propose DOVE, an efficient one-step diffusion model for real-world VSR. DOVE is obtained by fine-tuning a pretrained video diffusion model (*i.e.*, CogVideoX). To effectively train DOVE, we introduce the latent-pixel training strategy. The strategy employs a two-stage scheme to gradually adapt the model to the video super-resolution task. Meanwhile, we design a video processing pipeline to construct a high-quality dataset tailored for VSR, termed HQ-VSR. Fine-tuning on this dataset further enhances the restoration capability of DOVE. Extensive experiments show that DOVE exhibits comparable or superior performance to multi-step diffusion-based VSR methods. It also offers outstanding inference efficiency, achieving up to a **28$\times$** speed-up over existing methods such as MGLD-VSR. Code is available at: https://github.com/zhengchen1999/DOVE.
PMQ-VE: Progressive Multi-Frame Quantization for Video Enhancement
May 18, 2025



Multi-frame video enhancement tasks aim to improve the spatial and temporal resolution and quality of video sequences by leveraging temporal information from multiple frames, which are widely used in streaming video processing, surveillance, and generation. Although numerous Transformer-based enhancement methods have achieved impressive performance, their computational and memory demands hinder deployment on edge devices. Quantization offers a practical solution by reducing the bit-width of weights and activations to improve efficiency. However, directly applying existing quantization methods to video enhancement tasks often leads to significant performance degradation and loss of fine details. This stems from two limitations: (a) inability to allocate varying representational capacity across frames, which results in suboptimal dynamic range adaptation; (b) over-reliance on full-precision teachers, which limits the learning of low-bit student models. To tackle these challenges, we propose a novel quantization method for video enhancement: Progressive Multi-Frame Quantization for Video Enhancement (PMQ-VE). This framework features a coarse-to-fine two-stage process: Backtracking-based Multi-Frame Quantization (BMFQ) and Progressive Multi-Teacher Distillation (PMTD). BMFQ utilizes a percentile-based initialization and iterative search with pruning and backtracking for robust clipping bounds. PMTD employs a progressive distillation strategy with both full-precision and multiple high-bit (INT) teachers to enhance low-bit models' capacity and quality. Extensive experiments demonstrate that our method outperforms existing approaches, achieving state-of-the-art performance across multiple tasks and benchmarks.The code will be made publicly available at: https://github.com/xiaoBIGfeng/PMQ-VE.
Low-bit Model Quantization for Deep Neural Networks: A Survey
May 08, 2025

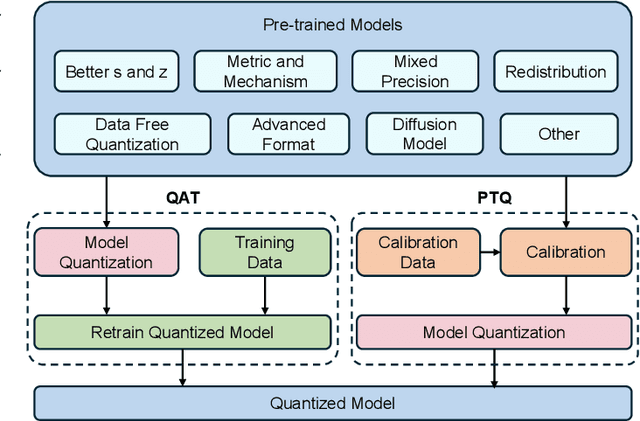
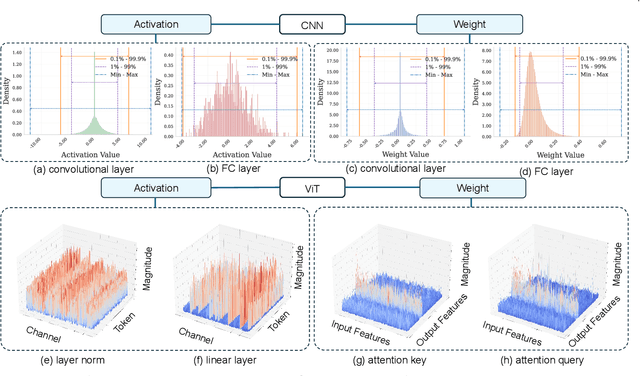
With unprecedented rapid development, deep neural networks (DNNs) have deeply influenced almost all fields. However, their heavy computation costs and model sizes are usually unacceptable in real-world deployment. Model quantization, an effective weight-lighting technique, has become an indispensable procedure in the whole deployment pipeline. The essence of quantization acceleration is the conversion from continuous floating-point numbers to discrete integer ones, which significantly speeds up the memory I/O and calculation, i.e., addition and multiplication. However, performance degradation also comes with the conversion because of the loss of precision. Therefore, it has become increasingly popular and critical to investigate how to perform the conversion and how to compensate for the information loss. This article surveys the recent five-year progress towards low-bit quantization on DNNs. We discuss and compare the state-of-the-art quantization methods and classify them into 8 main categories and 24 sub-categories according to their core techniques. Furthermore, we shed light on the potential research opportunities in the field of model quantization. A curated list of model quantization is provided at https://github.com/Kai-Liu001/Awesome-Model-Quantization.
Turbo2K: Towards Ultra-Efficient and High-Quality 2K Video Synthesis
Apr 20, 2025



Demand for 2K video synthesis is rising with increasing consumer expectations for ultra-clear visuals. While diffusion transformers (DiTs) have demonstrated remarkable capabilities in high-quality video generation, scaling them to 2K resolution remains computationally prohibitive due to quadratic growth in memory and processing costs. In this work, we propose Turbo2K, an efficient and practical framework for generating detail-rich 2K videos while significantly improving training and inference efficiency. First, Turbo2K operates in a highly compressed latent space, reducing computational complexity and memory footprint, making high-resolution video synthesis feasible. However, the high compression ratio of the VAE and limited model size impose constraints on generative quality. To mitigate this, we introduce a knowledge distillation strategy that enables a smaller student model to inherit the generative capacity of a larger, more powerful teacher model. Our analysis reveals that, despite differences in latent spaces and architectures, DiTs exhibit structural similarities in their internal representations, facilitating effective knowledge transfer. Second, we design a hierarchical two-stage synthesis framework that first generates multi-level feature at lower resolutions before guiding high-resolution video generation. This approach ensures structural coherence and fine-grained detail refinement while eliminating redundant encoding-decoding overhead, further enhancing computational efficiency.Turbo2K achieves state-of-the-art efficiency, generating 5-second, 24fps, 2K videos with significantly reduced computational cost. Compared to existing methods, Turbo2K is up to 20$\times$ faster for inference, making high-resolution video generation more scalable and practical for real-world applications.
QArtSR: Quantization via Reverse-Module and Timestep-Retraining in One-Step Diffusion based Image Super-Resolution
Mar 07, 2025



One-step diffusion-based image super-resolution (OSDSR) models are showing increasingly superior performance nowadays. However, although their denoising steps are reduced to one and they can be quantized to 8-bit to reduce the costs further, there is still significant potential for OSDSR to quantize to lower bits. To explore more possibilities of quantized OSDSR, we propose an efficient method, Quantization via reverse-module and timestep-retraining for OSDSR, named QArtSR. Firstly, we investigate the influence of timestep value on the performance of quantized models. Then, we propose Timestep Retraining Quantization (TRQ) and Reversed Per-module Quantization (RPQ) strategies to calibrate the quantized model. Meanwhile, we adopt the module and image losses to update all quantized modules. We only update the parameters in quantization finetuning components, excluding the original weights. To ensure that all modules are fully finetuned, we add extended end-to-end training after per-module stage. Our 4-bit and 2-bit quantization experimental results indicate that QArtSR obtains superior effects against the recent leading comparison methods. The performance of 4-bit QArtSR is close to the full-precision one. Our code will be released at https://github.com/libozhu03/QArtSR.
CondiQuant: Condition Number Based Low-Bit Quantization for Image Super-Resolution
Feb 21, 2025Low-bit model quantization for image super-resolution (SR) is a longstanding task that is renowned for its surprising compression and acceleration ability. However, accuracy degradation is inevitable when compressing the full-precision (FP) model to ultra-low bit widths (2~4 bits). Experimentally, we observe that the degradation of quantization is mainly attributed to the quantization of activation instead of model weights. In numerical analysis, the condition number of weights could measure how much the output value can change for a small change in the input argument, inherently reflecting the quantization error. Therefore, we propose CondiQuant, a condition number based low-bit post-training quantization for image super-resolution. Specifically, we formulate the quantization error as the condition number of weight metrics. By decoupling the representation ability and the quantization sensitivity, we design an efficient proximal gradient descent algorithm to iteratively minimize the condition number and maintain the output still. With comprehensive experiments, we demonstrate that CondiQuant outperforms existing state-of-the-art post-training quantization methods in accuracy without computation overhead and gains the theoretically optimal compression ratio in model parameters. Our code and model are released at https://github.com/Kai-Liu001/CondiQuant.
One Diffusion Step to Real-World Super-Resolution via Flow Trajectory Distillation
Feb 04, 2025



Diffusion models (DMs) have significantly advanced the development of real-world image super-resolution (Real-ISR), but the computational cost of multi-step diffusion models limits their application. One-step diffusion models generate high-quality images in a one sampling step, greatly reducing computational overhead and inference latency. However, most existing one-step diffusion methods are constrained by the performance of the teacher model, where poor teacher performance results in image artifacts. To address this limitation, we propose FluxSR, a novel one-step diffusion Real-ISR technique based on flow matching models. We use the state-of-the-art diffusion model FLUX.1-dev as both the teacher model and the base model. First, we introduce Flow Trajectory Distillation (FTD) to distill a multi-step flow matching model into a one-step Real-ISR. Second, to improve image realism and address high-frequency artifact issues in generated images, we propose TV-LPIPS as a perceptual loss and introduce Attention Diversification Loss (ADL) as a regularization term to reduce token similarity in transformer, thereby eliminating high-frequency artifacts. Comprehensive experiments demonstrate that our method outperforms existing one-step diffusion-based Real-ISR methods. The code and model will be released at https://github.com/JianzeLi-114/FluxSR.
Beyond Pixels: Text Enhances Generalization in Real-World Image Restoration
Dec 01, 2024



Generalization has long been a central challenge in real-world image restoration. While recent diffusion-based restoration methods, which leverage generative priors from text-to-image models, have made progress in recovering more realistic details, they still encounter "generative capability deactivation" when applied to out-of-distribution real-world data. To address this, we propose using text as an auxiliary invariant representation to reactivate the generative capabilities of these models. We begin by identifying two key properties of text input: richness and relevance, and examine their respective influence on model performance. Building on these insights, we introduce Res-Captioner, a module that generates enhanced textual descriptions tailored to image content and degradation levels, effectively mitigating response failures. Additionally, we present RealIR, a new benchmark designed to capture diverse real-world scenarios. Extensive experiments demonstrate that Res-Captioner significantly enhances the generalization abilities of diffusion-based restoration models, while remaining fully plug-and-play.
Grounding-IQA: Multimodal Language Grounding Model for Image Quality Assessment
Nov 26, 2024



The development of multimodal large language models (MLLMs) enables the evaluation of image quality through natural language descriptions. This advancement allows for more detailed assessments. However, these MLLM-based IQA methods primarily rely on general contextual descriptions, sometimes limiting fine-grained quality assessment. To address this limitation, we introduce a new image quality assessment (IQA) task paradigm, grounding-IQA. This paradigm integrates multimodal referring and grounding with IQA to realize more fine-grained quality perception. Specifically, grounding-IQA comprises two subtasks: grounding-IQA-description (GIQA-DES) and visual question answering (GIQA-VQA). GIQA-DES involves detailed descriptions with precise locations (e.g., bounding boxes), while GIQA-VQA focuses on quality QA for local regions. To realize grounding-IQA, we construct a corresponding dataset, GIQA-160K, through our proposed automated annotation pipeline. Furthermore, we develop a well-designed benchmark, GIQA-Bench. The benchmark comprehensively evaluates the model grounding-IQA performance from three perspectives: description quality, VQA accuracy, and grounding precision. Experiments demonstrate that our proposed task paradigm, dataset, and benchmark facilitate the more fine-grained IQA application. Code: https://github.com/zhengchen1999/Grounding-IQA.
PassionSR: Post-Training Quantization with Adaptive Scale in One-Step Diffusion based Image Super-Resolution
Nov 26, 2024Diffusion-based image super-resolution (SR) models have shown superior performance at the cost of multiple denoising steps. However, even though the denoising step has been reduced to one, they require high computational costs and storage requirements, making it difficult for deployment on hardware devices. To address these issues, we propose a novel post-training quantization approach with adaptive scale in one-step diffusion (OSD) image SR, PassionSR. First, we simplify OSD model to two core components, UNet and Variational Autoencoder (VAE) by removing the CLIPEncoder. Secondly, we propose Learnable Boundary Quantizer (LBQ) and Learnable Equivalent Transformation (LET) to optimize the quantization process and manipulate activation distributions for better quantization. Finally, we design a Distributed Quantization Calibration (DQC) strategy that stabilizes the training of quantized parameters for rapid convergence. Comprehensive experiments demonstrate that PassionSR with 8-bit and 6-bit obtains comparable visual results with full-precision model. Moreover, our PassionSR achieves significant advantages over recent leading low-bit quantization methods for image SR. Our code will be at https://github.com/libozhu03/PassionSR.