 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyBit: Dynamic Bit-Precision Numbers for Efficient Quantized Neural Network Inference
Feb 24, 2023To accelerate the inference of deep neural networks (DNNs), quantization with low-bitwidth numbers is actively researched. A prominent challenge is to quantize the DNN models into low-bitwidth numbers without significant accuracy degradation, especially at very low bitwidths (< 8 bits). This work targets an adaptive data representation with variable-length encoding called DyBit. DyBit can dynamically adjust the precision and range of separate bit-field to be adapted to the DNN weights/activations distribution. We also propose a hardware-aware quantization framework with a mixed-precision accelerator to trade-off the inference accuracy and speedup. Experimental results demonstrate that the inference accuracy via DyBit is 1.997% higher than the state-of-the-art at 4-bit quantization, and the proposed framework can achieve up to 8.1x speedup compared with the original model.
COTS: Collaborative Two-Stream Vision-Language Pre-Training Model for Cross-Modal Retrieval
Apr 15, 2022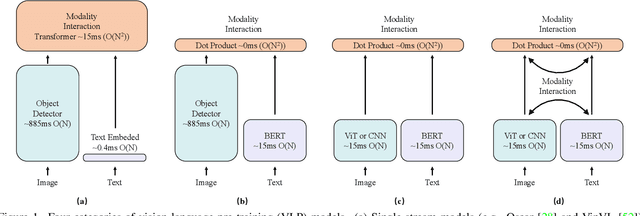
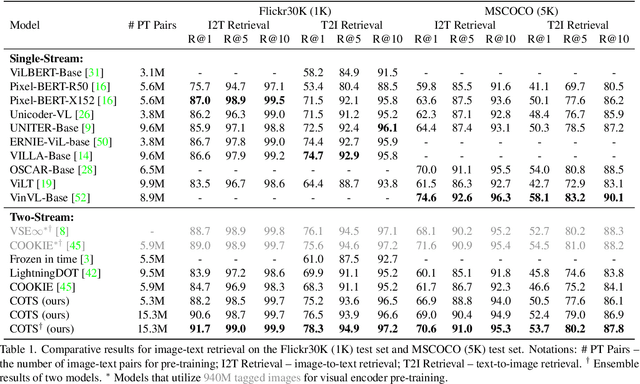
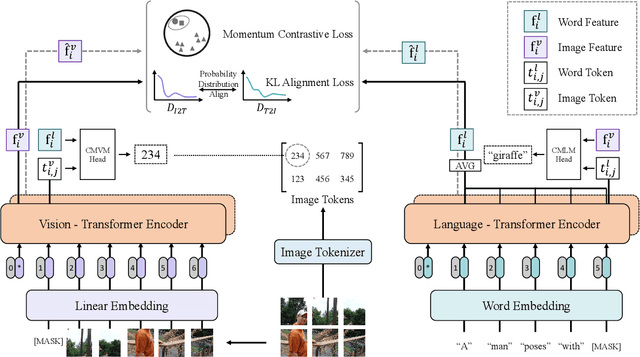
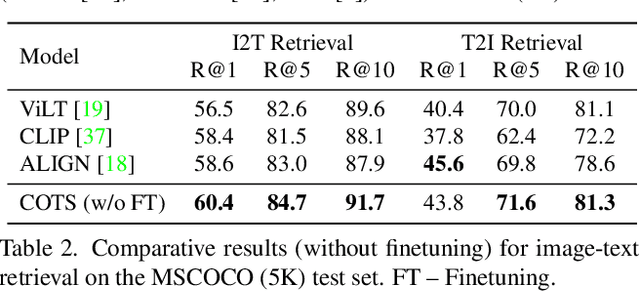
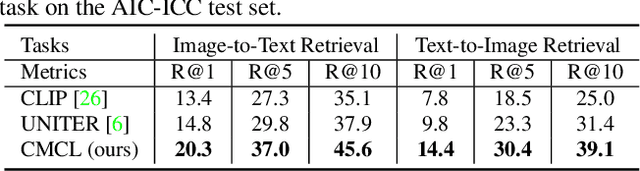
Large-scale single-stream pre-training has shown dramatic performance in image-text retrieval. Regrettably, it faces low inference efficiency due to heavy attention layers. Recently, two-stream methods like CLIP and ALIGN with high inference efficiency have also shown promising performance, however, they only consider instance-level alignment between the two streams (thus there is still room for improvement). To overcome these limitations, we propose a novel COllaborative Two-Stream vision-language pretraining model termed COTS for image-text retrieval by enhancing cross-modal interaction. In addition to instance level alignment via momentum contrastive learning, we leverage two extra levels of cross-modal interactions in our COTS: (1) Token-level interaction - a masked visionlanguage modeling (MVLM) learning objective is devised without using a cross-stream network module, where variational autoencoder is imposed on the visual encoder to generate visual tokens for each image. (2) Task-level interaction - a KL-alignment learning objective is devised between text-to-image and image-to-text retrieval tasks, where the probability distribution per task is computed with the negative queues in momentum contrastive learning. Under a fair comparison setting, our COTS achieves the highest performance among all two-stream methods and comparable performance (but with 10,800X faster in inference) w.r.t. the latest single-stream methods. Importantly, our COTS is also applicable to text-to-video retrieval, yielding new state-ofthe-art on the widely-used MSR-VTT dataset.
A Roadmap for Big Model
Apr 02, 2022



With the rapid development of deep learning, training Big Models (BMs) for multiple downstream tasks becomes a popular paradigm. Researchers have achieved various outcomes in the construction of BMs and the BM application in many fields. At present, there is a lack of research work that sorts out the overall progress of BMs and guides the follow-up research. In this paper, we cover not only the BM technologies themselves but also the prerequisites for BM training and applications with BMs, dividing the BM review into four parts: Resource, Models, Key Technologies and Application. We introduce 16 specific BM-related topics in those four parts, they are Data, Knowledge, Computing System, Parallel Training System, Language Model, Vision Model, Multi-modal Model, Theory&Interpretability, Commonsense Reasoning, Reliability&Security, Governance, Evaluation, Machine Translation, Text Generation, Dialogue and Protein Research. In each topic, we summarize clearly the current studies and propose some future research directions. At the end of this paper, we conclude the further development of BMs in a more general view.
WenLan 2.0: Make AI Imagine via a Multimodal Foundation Model
Oct 27, 2021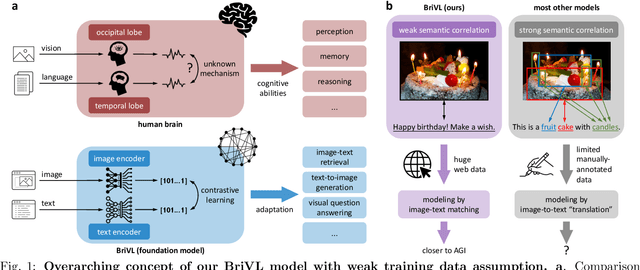


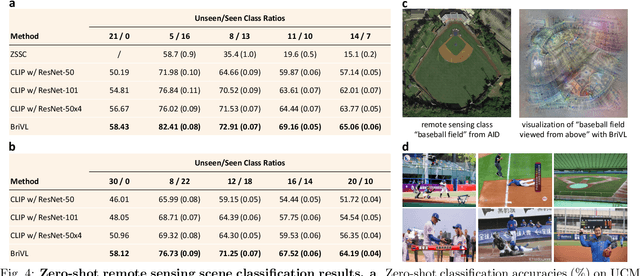
The fundamental goal of artificial intelligence (AI) is to mimic the core cognitive activities of human including perception, memory, and reasoning. Although tremendous success has been achieved in various AI research fields (e.g., computer vision and natural language processing), the majority of existing works only focus on acquiring single cognitive ability (e.g., image classification, reading comprehension, or visual commonsense reasoning). To overcome this limitation and take a solid step to artificial general intelligence (AGI), we develop a novel foundation model pre-trained with huge multimodal (visual and textual) data, which is able to be quickly adapted for a broad class of downstream cognitive tasks. Such a model is fundamentally different from the multimodal foundation models recently proposed in the literature that typically make strong semantic correlation assumption and expect exact alignment between image and text modalities in their pre-training data, which is often hard to satisfy in practice thus limiting their generalization abilities. To resolve this issue, we propose to pre-train our foundation model by self-supervised learning with weak semantic correlation data crawled from the Internet and show that state-of-the-art results can be obtained on a wide range of downstream tasks (both single-modal and cross-modal). Particularly, with novel model-interpretability tools developed in this work, we demonstrate that strong imagination ability (even with hints of commonsense) is now possessed by our foundation model. We believe our work makes a transformative stride towards AGI and will have broad impact on various AI+ fields (e.g., neuroscience and healthcare).
HAO: Hardware-aware neural Architecture Optimization for Efficient Inference
Apr 26, 2021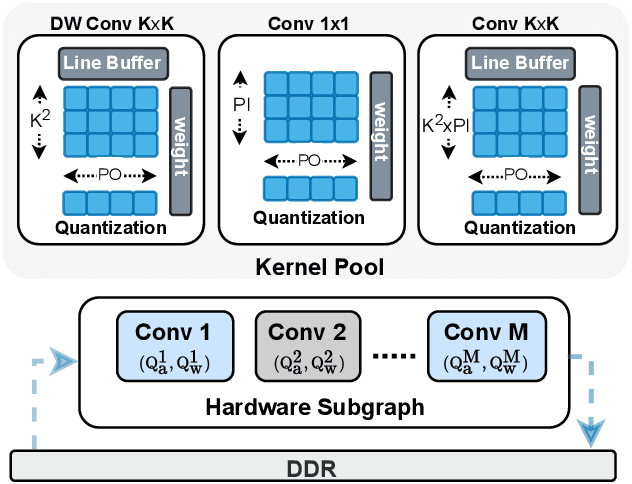
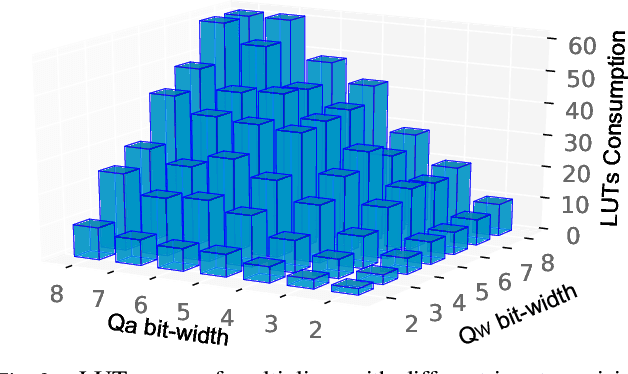
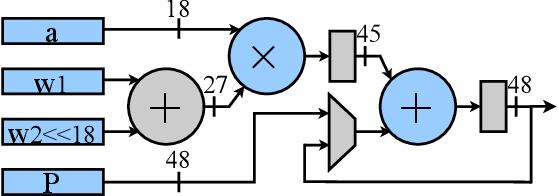
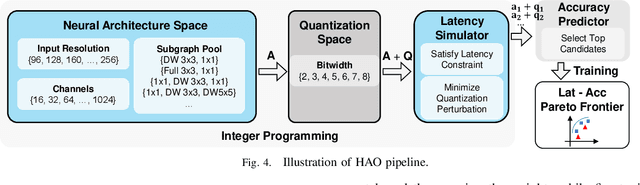
Automatic algorithm-hardware co-design for DNN has shown great success in improving the performance of DNNs on FPGAs. However, this process remains challenging due to the intractable search space of neural network architectures and hardware accelerator implementation. Differing from existing hardware-aware neural architecture search (NAS) algorithms that rely solely on the expensive learning-based approaches, our work incorporates integer programming into the search algorithm to prune the design space. Given a set of hardware resource constraints, our integer programming formulation directly outputs the optimal accelerator configuration for mapping a DNN subgraph that minimizes latency. We use an accuracy predictor for different DNN subgraphs with different quantization schemes and generate accuracy-latency pareto frontiers. With low computational cost, our algorithm can generate quantized networks that achieve state-of-the-art accuracy and hardware performance on Xilinx Zynq (ZU3EG) FPGA for image classification on ImageNet dataset. The solution searched by our algorithm achieves 72.5% top-1 accuracy on ImageNet at framerate 50, which is 60% faster than MnasNet and 135% faster than FBNet with comparable accuracy.
WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training
Mar 19, 2021
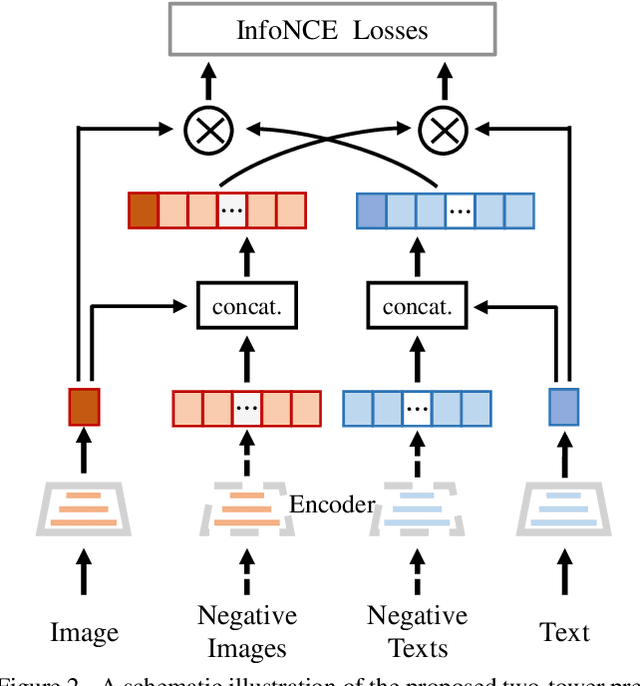
Multi-modal pre-training models have been intensively explored to bridge vision and language in recent years. However, most of them explicitly model the cross-modal interaction between image-text pairs, by assuming that there exists strong semantic correlation between the text and image modalities. Since this strong assumption is often invalid in real-world scenarios, we choose to implicitly model the cross-modal correlation for large-scale multi-modal pre-training, which is the focus of the Chinese project `WenLan' led by our team. Specifically, with the weak correlation assumption over image-text pairs, we propose a two-tower pre-training model called BriVL within the cross-modal contrastive learning framework. Unlike OpenAI CLIP that adopts a simple contrastive learning method, we devise a more advanced algorithm by adapting the latest method MoCo into the cross-modal scenario. By building a large queue-based dictionary, our BriVL can incorporate more negative samples in limited GPU resources. We further construct a large Chinese multi-source image-text dataset called RUC-CAS-WenLan for pre-training our BriVL model. Extensive experiments demonstrate that the pre-trained BriVL model outperforms both UNITER and OpenAI CLIP on various downstream tasks.
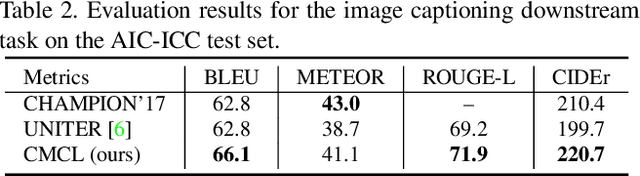
Contrastive Prototype Learning with Augmented Embeddings for Few-Shot Learning
Jan 23, 2021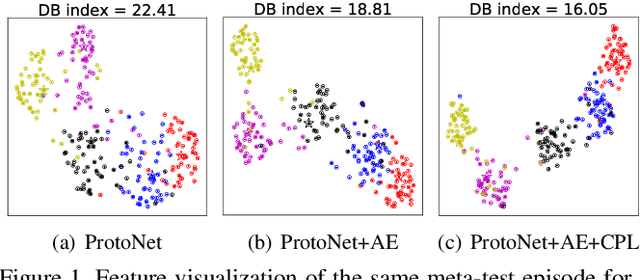
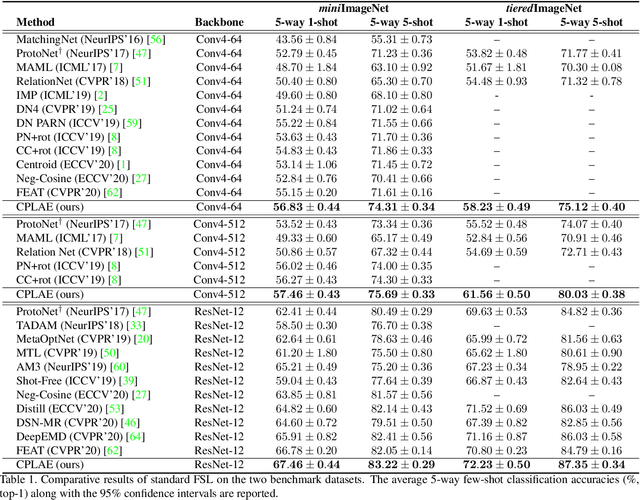
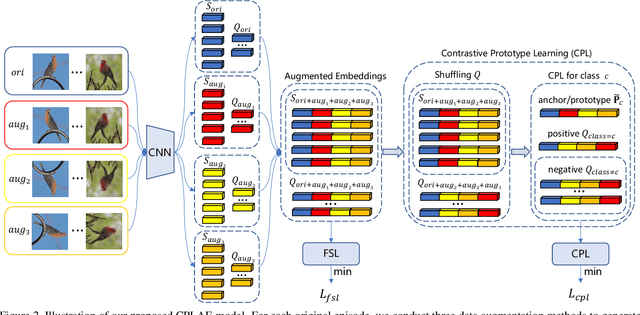

Most recent few-shot learning (FSL) methods are based on meta-learning with episodic training. In each meta-training episode, a discriminative feature embedding and/or classifier are first constructed from a support set in an inner loop, and then evaluated in an outer loop using a query set for model updating. This query set sample centered learning objective is however intrinsically limited in addressing the lack of training data problem in the support set. In this paper, a novel contrastive prototype learning with augmented embeddings (CPLAE) model is proposed to overcome this limitation. First, data augmentations are introduced to both the support and query sets with each sample now being represented as an augmented embedding (AE) composed of concatenated embeddings of both the original and augmented versions. Second, a novel support set class prototype centered contrastive loss is proposed for contrastive prototype learning (CPL). With a class prototype as an anchor, CPL aims to pull the query samples of the same class closer and those of different classes further away. This support set sample centered loss is highly complementary to the existing query centered loss, fully exploiting the limited training data in each episode. Extensive experiments on several benchmarks demonstrate that our proposed CPLAE achieves new state-of-the-art.
CoDeNet: Algorithm-hardware Co-design for Deformable Convolution
Jun 12, 2020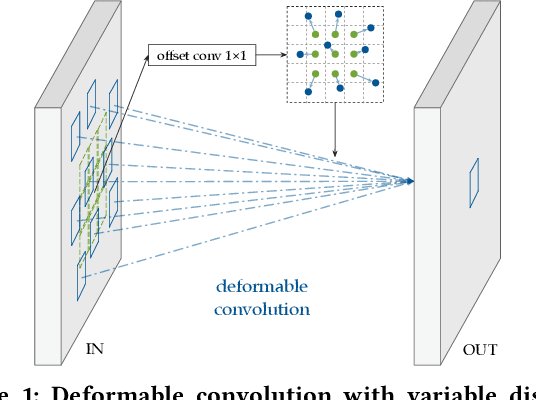
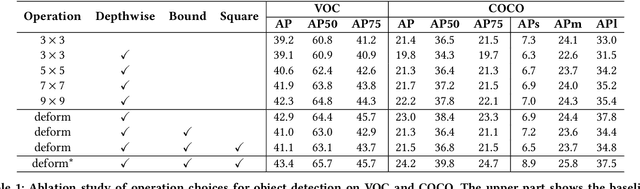
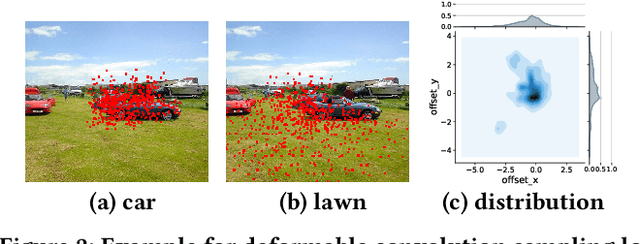
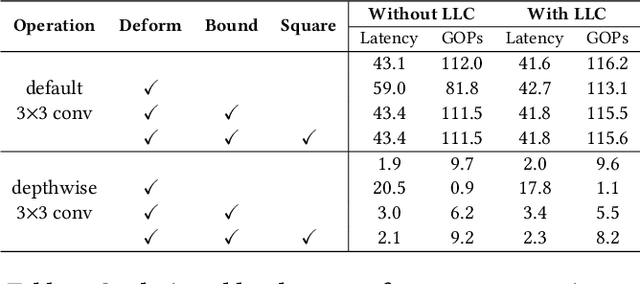
Deploying deep learning models on embedded systems for computer vision tasks has been challenging due to limited compute resources and strict energy budgets. The majority of existing work focuses on accelerating image classification, while other fundamental vision problems, such as object detection, have not been adequately addressed. Compared with image classification, detection problems are more sensitive to the spatial variance of objects, and therefore, require specialized convolutions to aggregate spatial information. To address this, recent work proposes dynamic deformable convolution to augment regular convolutions. Regular convolutions process a fixed grid of pixels across all the spatial locations in an image, while dynamic deformable convolution may access arbitrary pixels in the image and the access pattern is input-dependent and varies per spatial location. These properties lead to inefficient memory accesses of inputs with existing hardware. In this work, we first investigate the overhead of the deformable convolution on embedded FPGA SoCs, and introduce a depthwise deformable convolution to reduce the total number of operations required. We then show the speed-accuracy tradeoffs for a set of algorithm modifications including irregular-access versus limited-range and fixed-shape. We evaluate these algorithmic changes with corresponding hardware optimizations. Results show a 1.36x and 9.76x speedup respectively for the full and depthwise deformable convolution on the embedded FPGA accelerator with minor accuracy loss on the object detection task. We then co-design an efficient network CoDeNet with the modified deformable convolution for object detection and quantize the network to 4-bit weights and 8-bit activations. Results show that our designs lie on the pareto-optimal front of the latency-accuracy tradeoff for the object detection task on embedded FPGAs
Meta-Learning across Meta-Tasks for Few-Shot Learning
Mar 09, 2020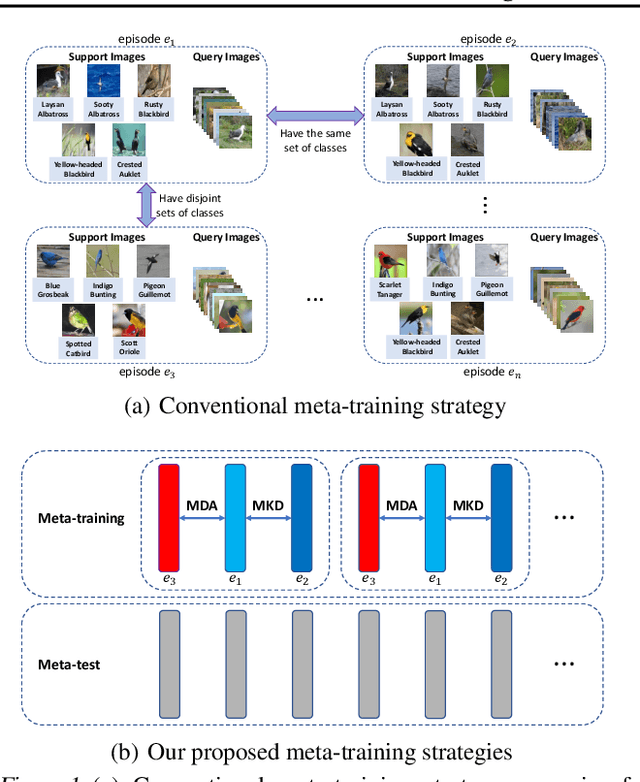
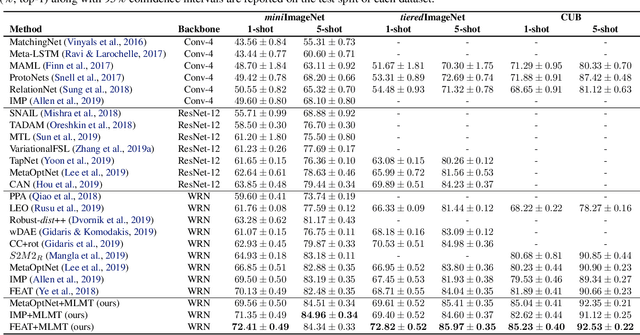
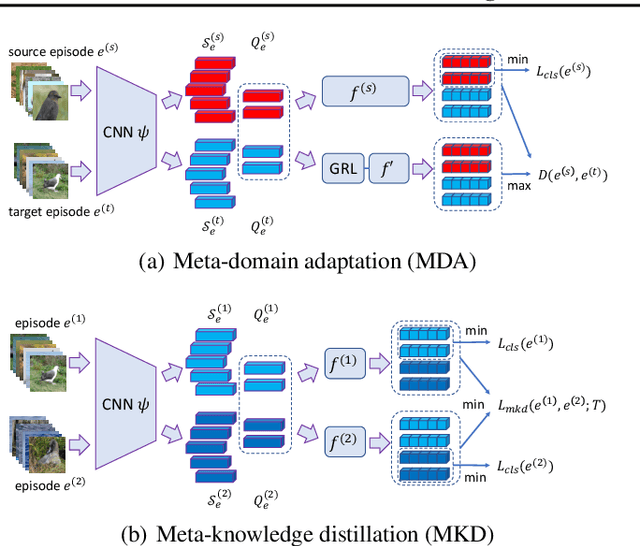
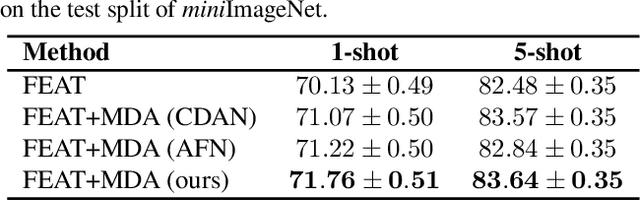
Existing meta-learning based few-shot learning (FSL) methods typically adopt an episodic training strategy whereby each episode contains a meta-task. Across episodes, these tasks are sampled randomly and their relationships are ignored. In this paper, we argue that the inter-meta-task relationships should be exploited and those tasks are sampled strategically to assist in meta-learning. Specifically, we consider the relationships defined over two types of meta-task pairs and propose different strategies to exploit them. (1) Two meta-tasks with disjoint sets of classes: this pair is interesting because it is reminiscent of the relationship between the source seen classes and target unseen classes, featured with domain gap caused by class differences. A novel learning objective termed meta-domain adaptation (MDA) is proposed to make the meta-learned model more robust to the domain gap. (2) Two meta-tasks with identical sets of classes: this pair is useful because it can be employed to learn models that are robust against poorly sampled few-shots. To that end, a novel meta-knowledge distillation (MKD) objective is formulated. Extensive experiments demonstrate that both MDA and MKD significantly boost the performance of a variety of FSL methods, resulting in new state-of-the-art on three benchmarks.
Algorithm-hardware Co-design for Deformable Convolution
Feb 19, 2020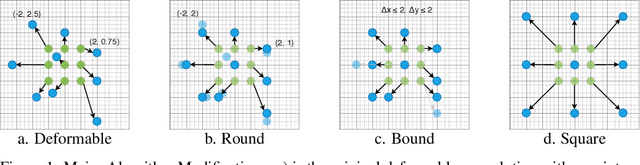
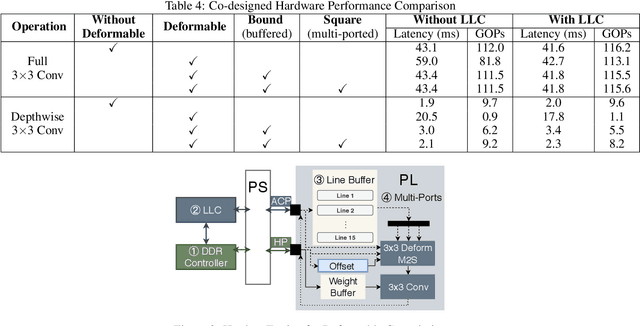
FPGAs provide a flexible and efficient platform to accelerate rapidly-changing algorithms for computer vision. The majority of existing work focuses on accelerating image classification, while other fundamental vision problems, including object detection and instance segmentation, have not been adequately addressed. Compared with image classification, detection problems are more sensitive to the spatial variance of objects, and therefore, require specialized convolutions to aggregate spatial information. To address this, recent work proposes dynamic deformable convolution to augment regular convolutions. Regular convolutions process a fixed grid of pixels across all the spatial locations in an image, while dynamic deformable convolutions may access arbitrary pixels in the image and the access pattern is input-dependent and varies per spatial location. These properties lead to inefficient memory accesses of inputs with existing hardware. In this work, we first investigate the overhead of the deformable convolution on embedded FPGA SoCs, and then show the accuracy-latency tradeoffs for a set of algorithm modifications including full versus depthwise, fixed-shape, and limited-range. These modifications benefit the energy efficiency for embedded devices in general as they reduce the compute complexity. We then build an efficient object detection network with modified deformable convolutions and quantize the network using state-of-the-art quantization methods. We implement a unified hardware engine on FPGA to support all the operations in the network. Preliminary experiments show that little accuracy is compromised and speedup can be achieved with our co-design optimization for the deformable convolution.