 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeculative Interaction Agents: Building Real-Time Agents with Asynchronous I/O and Speculative Tool Calling
May 14, 2026There is a growing demand for agentic AI technologies for a range of downstream applications like customer service and personal assistants. For applications where the agent needs to interact with a person, real-time low-latency responsiveness is required; for example, with voice-controlled applications, under 1 second of latency is typically required for the interaction to feel seamless. However, if we want the LLM to reason and execute an agentic workflow with tool calling, this can add several seconds or more of latency, which is prohibitive for real-time latency-sensitive applications. In our work, we propose Speculative Interaction Agents to enable real-time interaction even for agents with complex multi-turn tool calling. We propose Asynchronous I/O, which decouples the core agent reason-and-act thread from waiting for additional information from either the user or environment, thereby allowing for overlapping agentic processing while waiting on external delays. We also propose Speculative Tool Calling as a method to manage task execution when the agent is still unsure if it has received the full information or if additional user information may later be provided. For strong cloud models, our method can be applied out-of-the-box to existing real-time cloud APIs, providing 1.3-1.7$\times$ speedups with minor accuracy loss. To enable real-time interaction with small edge-scale models, we also present a clock-based training methodology that adapts the model to handle streaming inputs and asynchronous responses, and demonstrate a synthetic data generation strategy for SFT. Altogether, this approach provides 1.6-2.2$\times$ speedups with the Qwen2.5-3B-Instruct and Llama-3.2-3B-Instruct models across multiple tool calling benchmarks.
High-Throughput SAT Sampling
Feb 12, 2025In this work, we present a novel technique for GPU-accelerated Boolean satisfiability (SAT) sampling. Unlike conventional sampling algorithms that directly operate on conjunctive normal form (CNF), our method transforms the logical constraints of SAT problems by factoring their CNF representations into simplified multi-level, multi-output Boolean functions. It then leverages gradient-based optimization to guide the search for a diverse set of valid solutions. Our method operates directly on the circuit structure of refactored SAT instances, reinterpreting the SAT problem as a supervised multi-output regression task. This differentiable technique enables independent bit-wise operations on each tensor element, allowing parallel execution of learning processes. As a result, we achieve GPU-accelerated sampling with significant runtime improvements ranging from $33.6\times$ to $523.6\times$ over state-of-the-art heuristic samplers. We demonstrate the superior performance of our sampling method through an extensive evaluation on $60$ instances from a public domain benchmark suite utilized in previous studies.
Chip Placement with Diffusion
Jul 17, 2024



Macro placement is a vital step in digital circuit design that defines the physical location of large collections of components, known as macros, on a 2-dimensional chip. The physical layout obtained during placement determines key performance metrics of the chip, such as power consumption, area, and performance. Existing learning-based methods typically fall short because of their reliance on reinforcement learning, which is slow and limits the flexibility of the agent by casting placement as a sequential process. Instead, we use a powerful diffusion model to place all components simultaneously. To enable such models to train at scale, we propose a novel architecture for the denoising model, as well as an algorithm to generate large synthetic datasets for pre-training. We empirically show that our model can tackle the placement task, and achieve competitive performance on placement benchmarks compared to state-of-the-art methods.
CoSA: Scheduling by Constrained Optimization for Spatial Accelerators
May 05, 2021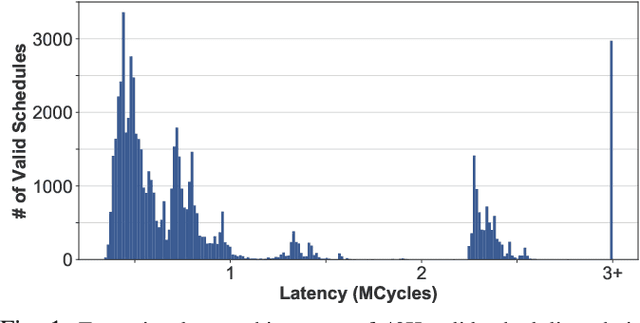
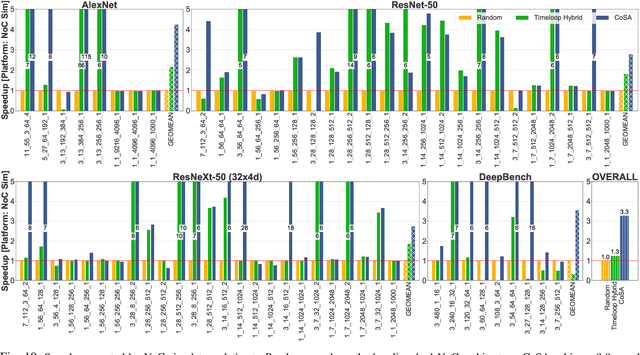
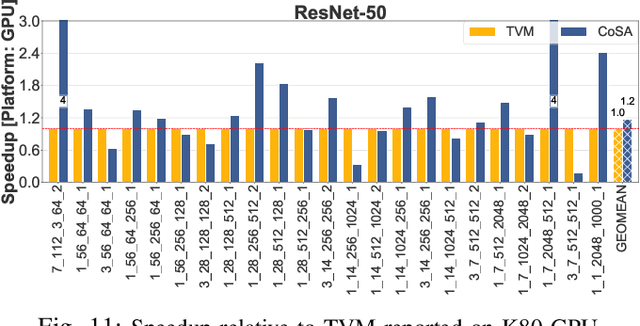
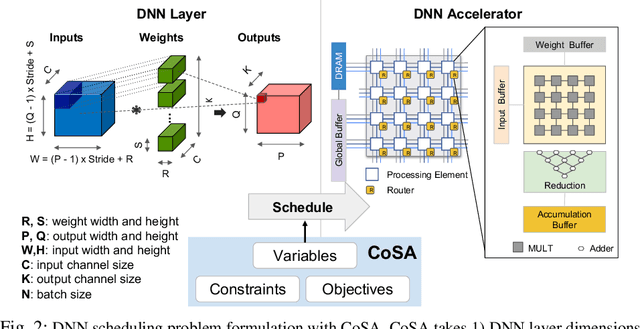
Recent advances in Deep Neural Networks (DNNs) have led to active development of specialized DNN accelerators, many of which feature a large number of processing elements laid out spatially, together with a multi-level memory hierarchy and flexible interconnect. While DNN accelerators can take advantage of data reuse and achieve high peak throughput, they also expose a large number of runtime parameters to the programmers who need to explicitly manage how computation is scheduled both spatially and temporally. In fact, different scheduling choices can lead to wide variations in performance and efficiency, motivating the need for a fast and efficient search strategy to navigate the vast scheduling space. To address this challenge, we present CoSA, a constrained-optimization-based approach for scheduling DNN accelerators. As opposed to existing approaches that either rely on designers' heuristics or iterative methods to navigate the search space, CoSA expresses scheduling decisions as a constrained-optimization problem that can be deterministically solved using mathematical optimization techniques. Specifically, CoSA leverages the regularities in DNN operators and hardware to formulate the DNN scheduling space into a mixed-integer programming (MIP) problem with algorithmic and architectural constraints, which can be solved to automatically generate a highly efficient schedule in one shot. We demonstrate that CoSA-generated schedules significantly outperform state-of-the-art approaches by a geometric mean of up to 2.5x across a wide range of DNN networks while improving the time-to-solution by 90x.
HAO: Hardware-aware neural Architecture Optimization for Efficient Inference
Apr 26, 2021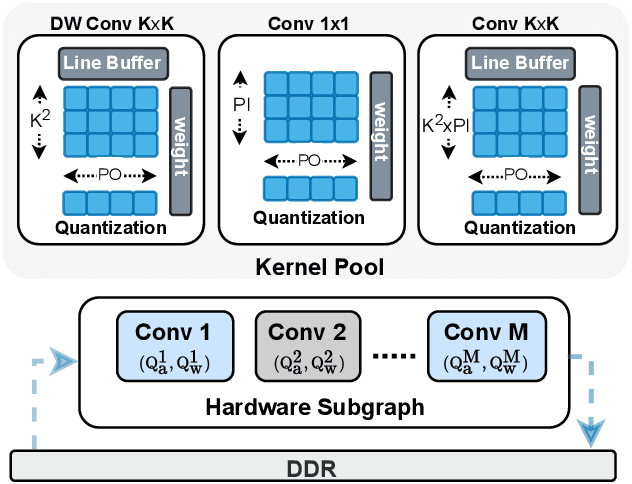
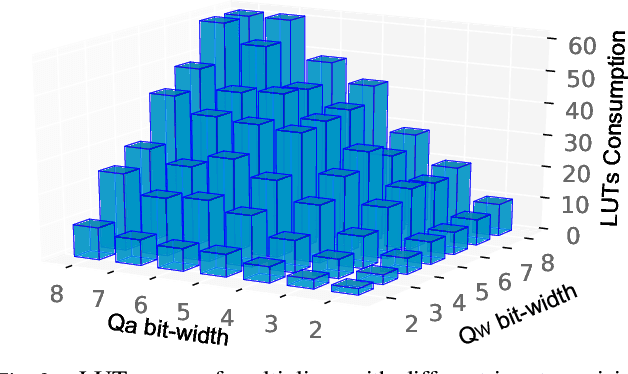
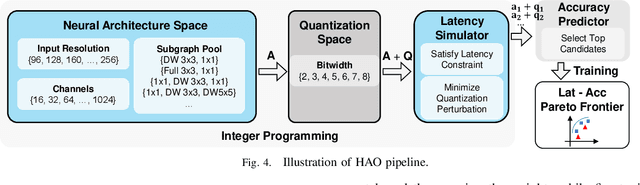
Automatic algorithm-hardware co-design for DNN has shown great success in improving the performance of DNNs on FPGAs. However, this process remains challenging due to the intractable search space of neural network architectures and hardware accelerator implementation. Differing from existing hardware-aware neural architecture search (NAS) algorithms that rely solely on the expensive learning-based approaches, our work incorporates integer programming into the search algorithm to prune the design space. Given a set of hardware resource constraints, our integer programming formulation directly outputs the optimal accelerator configuration for mapping a DNN subgraph that minimizes latency. We use an accuracy predictor for different DNN subgraphs with different quantization schemes and generate accuracy-latency pareto frontiers. With low computational cost, our algorithm can generate quantized networks that achieve state-of-the-art accuracy and hardware performance on Xilinx Zynq (ZU3EG) FPGA for image classification on ImageNet dataset. The solution searched by our algorithm achieves 72.5% top-1 accuracy on ImageNet at framerate 50, which is 60% faster than MnasNet and 135% faster than FBNet with comparable accuracy.
CoDeNet: Algorithm-hardware Co-design for Deformable Convolution
Jun 12, 2020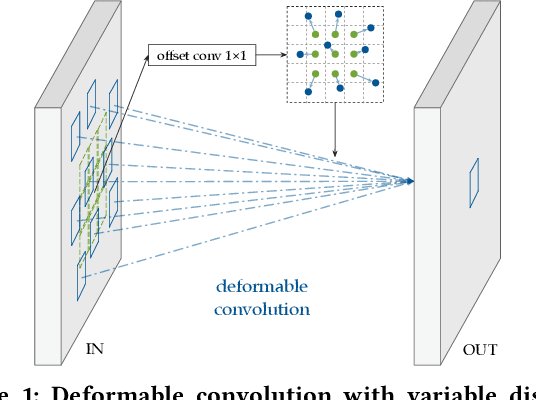
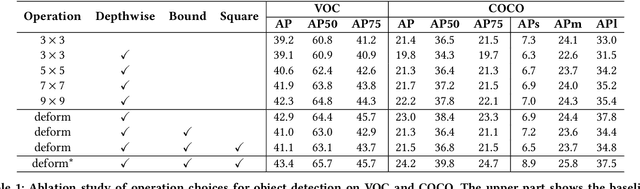
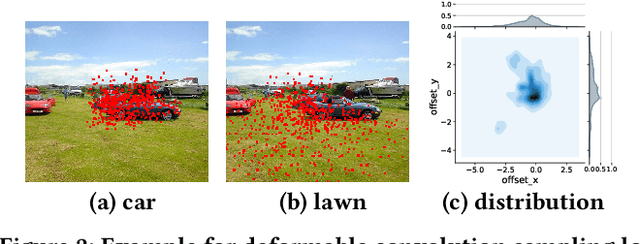
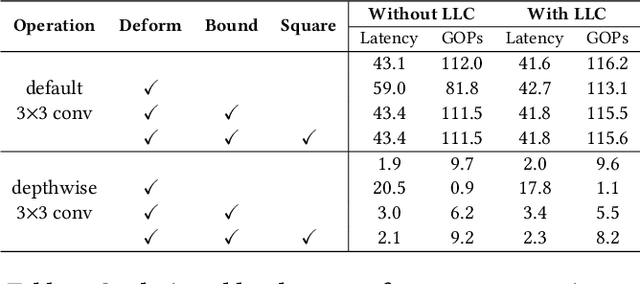
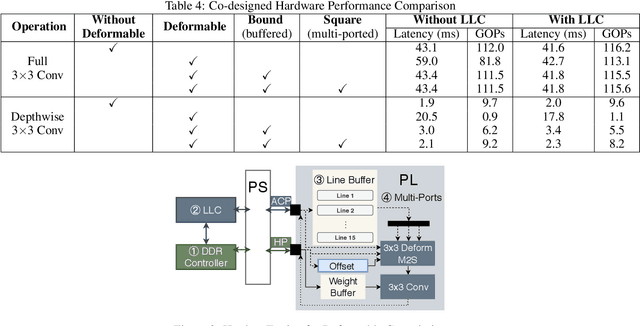
Deploying deep learning models on embedded systems for computer vision tasks has been challenging due to limited compute resources and strict energy budgets. The majority of existing work focuses on accelerating image classification, while other fundamental vision problems, such as object detection, have not been adequately addressed. Compared with image classification, detection problems are more sensitive to the spatial variance of objects, and therefore, require specialized convolutions to aggregate spatial information. To address this, recent work proposes dynamic deformable convolution to augment regular convolutions. Regular convolutions process a fixed grid of pixels across all the spatial locations in an image, while dynamic deformable convolution may access arbitrary pixels in the image and the access pattern is input-dependent and varies per spatial location. These properties lead to inefficient memory accesses of inputs with existing hardware. In this work, we first investigate the overhead of the deformable convolution on embedded FPGA SoCs, and introduce a depthwise deformable convolution to reduce the total number of operations required. We then show the speed-accuracy tradeoffs for a set of algorithm modifications including irregular-access versus limited-range and fixed-shape. We evaluate these algorithmic changes with corresponding hardware optimizations. Results show a 1.36x and 9.76x speedup respectively for the full and depthwise deformable convolution on the embedded FPGA accelerator with minor accuracy loss on the object detection task. We then co-design an efficient network CoDeNet with the modified deformable convolution for object detection and quantize the network to 4-bit weights and 8-bit activations. Results show that our designs lie on the pareto-optimal front of the latency-accuracy tradeoff for the object detection task on embedded FPGAs
ProTuner: Tuning Programs with Monte Carlo Tree Search
May 27, 2020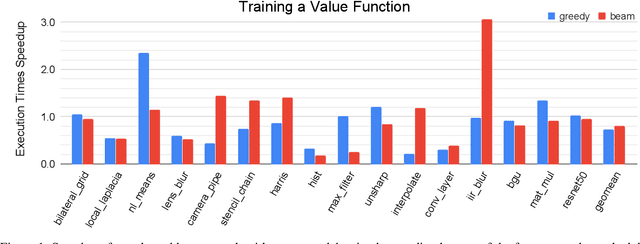

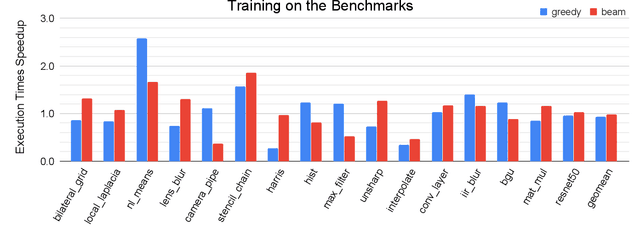
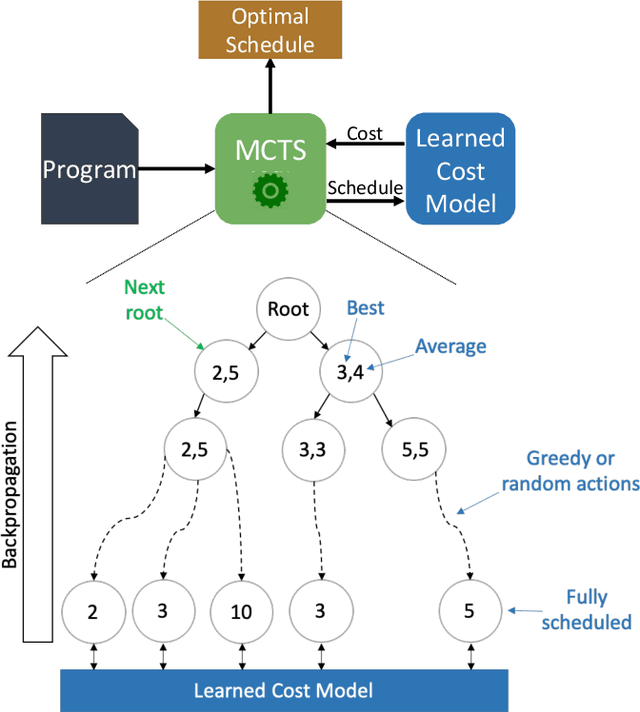
We explore applying the Monte Carlo Tree Search (MCTS) algorithm in a notoriously difficult task: tuning programs for high-performance deep learning and image processing. We build our framework on top of Halide and show that MCTS can outperform the state-of-the-art beam-search algorithm. Unlike beam search, which is guided by greedy intermediate performance comparisons between partial and less meaningful schedules, MCTS compares complete schedules and looks ahead before making any intermediate scheduling decision. We further explore modifications to the standard MCTS algorithm as well as combining real execution time measurements with the cost model. Our results show that MCTS can outperform beam search on a suite of 16 real benchmarks.
AutoPhase: Juggling HLS Phase Orderings in Random Forests with Deep Reinforcement Learning
Mar 04, 2020


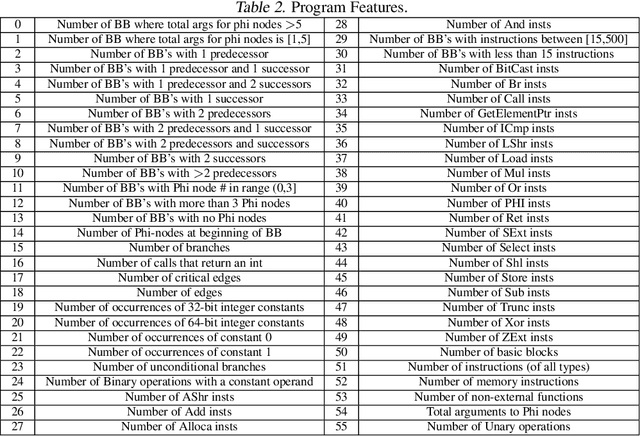
The performance of the code a compiler generates depends on the order in which it applies the optimization passes. Choosing a good order--often referred to as the phase-ordering problem, is an NP-hard problem. As a result, existing solutions rely on a variety of heuristics. In this paper, we evaluate a new technique to address the phase-ordering problem: deep reinforcement learning. To this end, we implement AutoPhase: a framework that takes a program and uses deep reinforcement learning to find a sequence of compilation passes that minimizes its execution time. Without loss of generality, we construct this framework in the context of the LLVM compiler toolchain and target high-level synthesis programs. We use random forests to quantify the correlation between the effectiveness of a given pass and the program's features. This helps us reduce the search space by avoiding phase orderings that are unlikely to improve the performance of a given program. We compare the performance of AutoPhase to state-of-the-art algorithms that address the phase-ordering problem. In our evaluation, we show that AutoPhase improves circuit performance by 28% when compared to using the -O3 compiler flag, and achieves competitive results compared to the state-of-the-art solutions, while requiring fewer samples. Furthermore, unlike existing state-of-the-art solutions, our deep reinforcement learning solution shows promising result in generalizing to real benchmarks and 12,874 different randomly generated programs, after training on a hundred randomly generated programs.
Algorithm-hardware Co-design for Deformable Convolution
Feb 19, 2020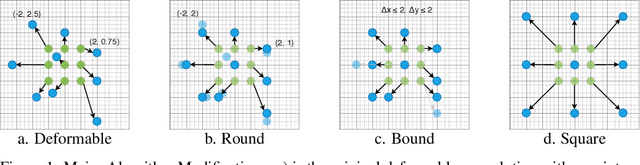
FPGAs provide a flexible and efficient platform to accelerate rapidly-changing algorithms for computer vision. The majority of existing work focuses on accelerating image classification, while other fundamental vision problems, including object detection and instance segmentation, have not been adequately addressed. Compared with image classification, detection problems are more sensitive to the spatial variance of objects, and therefore, require specialized convolutions to aggregate spatial information. To address this, recent work proposes dynamic deformable convolution to augment regular convolutions. Regular convolutions process a fixed grid of pixels across all the spatial locations in an image, while dynamic deformable convolutions may access arbitrary pixels in the image and the access pattern is input-dependent and varies per spatial location. These properties lead to inefficient memory accesses of inputs with existing hardware. In this work, we first investigate the overhead of the deformable convolution on embedded FPGA SoCs, and then show the accuracy-latency tradeoffs for a set of algorithm modifications including full versus depthwise, fixed-shape, and limited-range. These modifications benefit the energy efficiency for embedded devices in general as they reduce the compute complexity. We then build an efficient object detection network with modified deformable convolutions and quantize the network using state-of-the-art quantization methods. We implement a unified hardware engine on FPGA to support all the operations in the network. Preliminary experiments show that little accuracy is compromised and speedup can be achieved with our co-design optimization for the deformable convolution.
AutoPhase: Compiler Phase-Ordering for High Level Synthesis with Deep Reinforcement Learning
Jan 15, 2019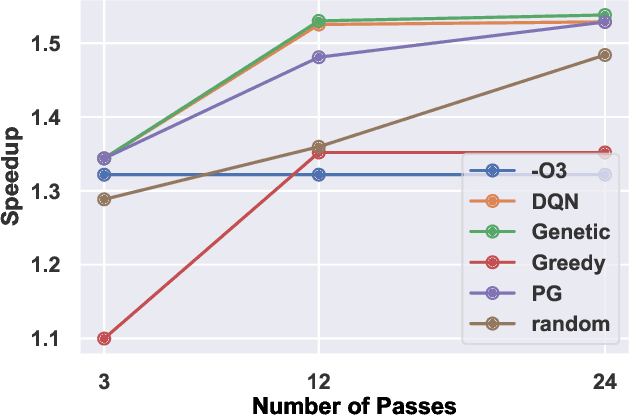
The performance of the code generated by a compiler depends on the order in which the optimization passes are applied. In the context of high-level synthesis, the quality of the generated circuit relates directly to the code generated by the front-end compiler. Unfortunately, choosing a good order--often referred to as the phase-ordering problem--is an NP-hard problem. As a result, existing solutions rely on a variety of sub-optimal heuristics. In this paper, we evaluate a new technique to address the phase-ordering problem: deep reinforcement learning. To this end, we implement a framework that takes any group of programs and finds a sequence of passes that optimize the performance of these programs. Without loss of generality, we instantiate this framework in the context of an LLVM compiler and target multiple High-Level Synthesis programs. We compare the performance of deep reinforcement learning to state-of-the-art algorithms that address the phase-ordering problem. Overall, our framework runs one to two orders of magnitude faster than these algorithms, and achieves a 16% improvement in circuit performance over the -O3 compiler flag.