 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Elasticity in Tensor Ranks for Compressing Neural Networks
May 10, 2021
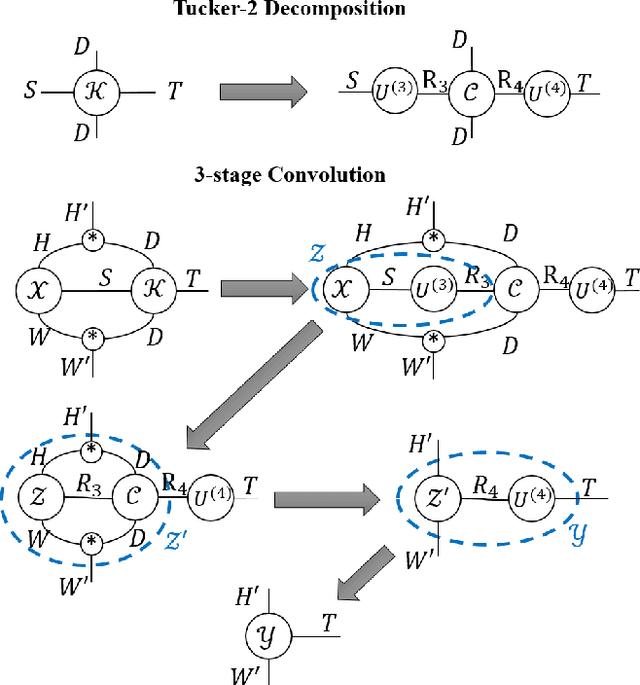
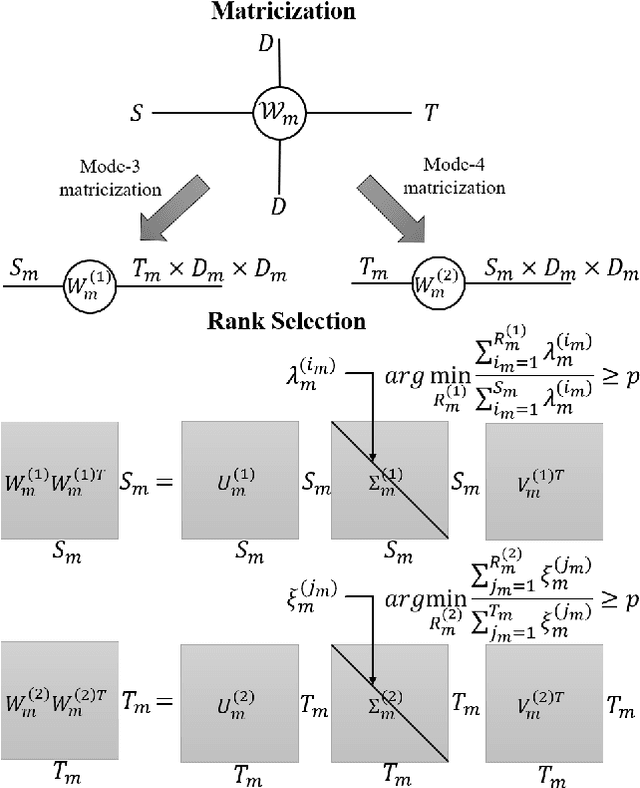
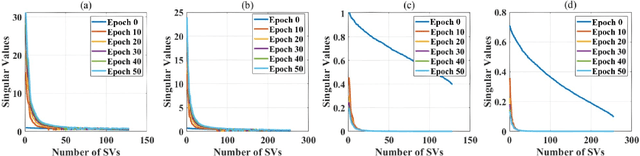
Elasticities in depth, width, kernel size and resolution have been explored in compressing deep neural networks (DNNs). Recognizing that the kernels in a convolutional neural network (CNN) are 4-way tensors, we further exploit a new elasticity dimension along the input-output channels. Specifically, a novel nuclear-norm rank minimization factorization (NRMF) approach is proposed to dynamically and globally search for the reduced tensor ranks during training. Correlation between tensor ranks across multiple layers is revealed, and a graceful tradeoff between model size and accuracy is obtained. Experiments then show the superiority of NRMF over the previous non-elastic variational Bayesian matrix factorization (VBMF) scheme.
HAO: Hardware-aware neural Architecture Optimization for Efficient Inference
Apr 26, 2021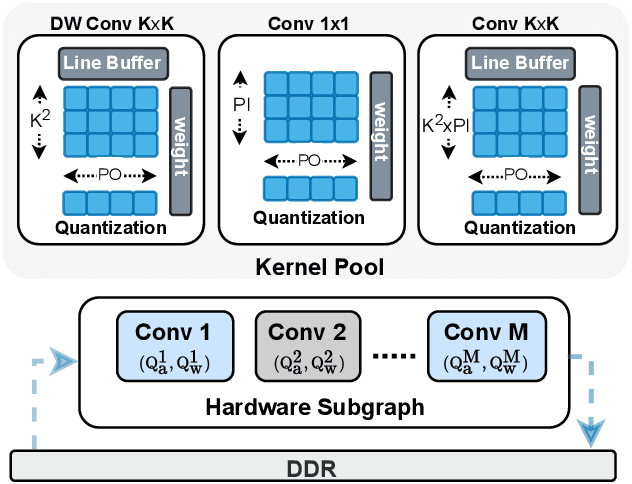
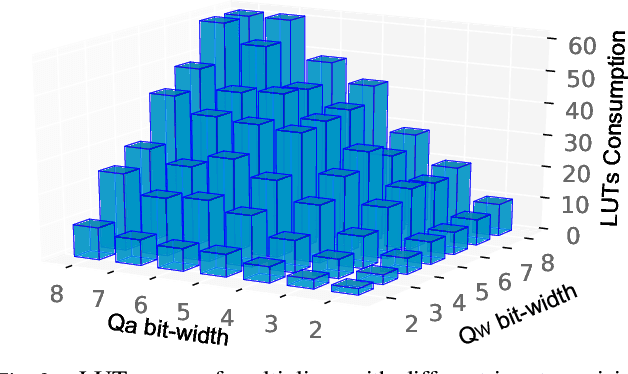
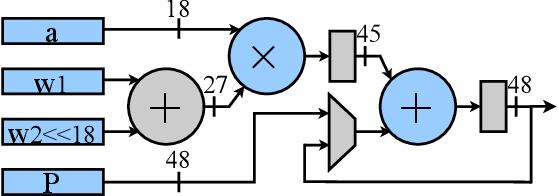
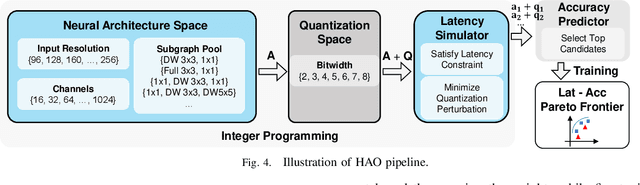
Automatic algorithm-hardware co-design for DNN has shown great success in improving the performance of DNNs on FPGAs. However, this process remains challenging due to the intractable search space of neural network architectures and hardware accelerator implementation. Differing from existing hardware-aware neural architecture search (NAS) algorithms that rely solely on the expensive learning-based approaches, our work incorporates integer programming into the search algorithm to prune the design space. Given a set of hardware resource constraints, our integer programming formulation directly outputs the optimal accelerator configuration for mapping a DNN subgraph that minimizes latency. We use an accuracy predictor for different DNN subgraphs with different quantization schemes and generate accuracy-latency pareto frontiers. With low computational cost, our algorithm can generate quantized networks that achieve state-of-the-art accuracy and hardware performance on Xilinx Zynq (ZU3EG) FPGA for image classification on ImageNet dataset. The solution searched by our algorithm achieves 72.5% top-1 accuracy on ImageNet at framerate 50, which is 60% faster than MnasNet and 135% faster than FBNet with comparable accuracy.
NITI: Training Integer Neural Networks Using Integer-only Arithmetic
Sep 28, 2020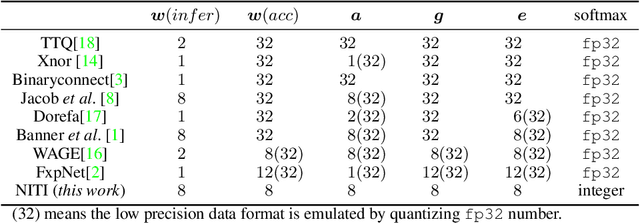
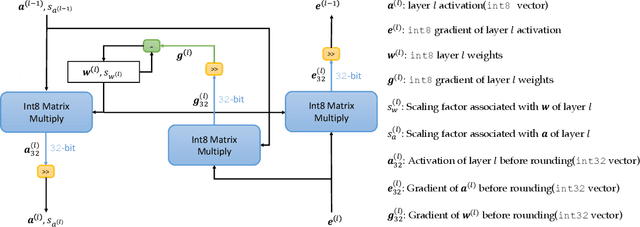
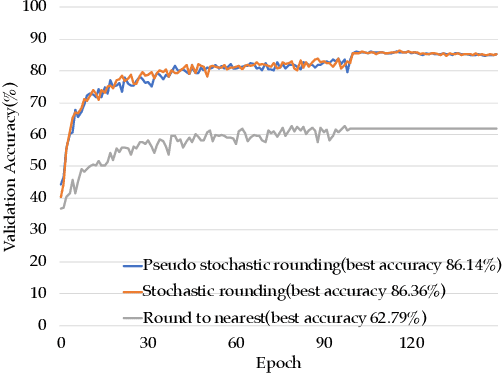

While integer arithmetic has been widely adopted for improved performance in deep quantized neural network inference, training remains a task primarily executed using floating point arithmetic. This is because both high dynamic range and numerical accuracy are central to the success of most modern training algorithms. However, due to its potential for computational, storage and energy advantages in hardware accelerators, neural network training methods that can be implemented with low precision integer-only arithmetic remains an active research challenge. In this paper, we present NITI, an efficient deep neural network training framework that stores all parameters and intermediate values as integers, and computes exclusively with integer arithmetic. A pseudo stochastic rounding scheme that eliminates the need for external random number generation is proposed to facilitate conversion from wider intermediate results to low precision storage. Furthermore, a cross-entropy loss backpropagation scheme computed with integer-only arithmetic is proposed. A proof-of-concept open-source software implementation of NITI that utilizes native 8-bit integer operations in modern GPUs to achieve end-to-end training is presented. When compared with an equivalent training setup implemented with floating point storage and arithmetic, NITI achieves negligible accuracy degradation on the MNIST and CIFAR10 datasets using 8-bit integer storage and computation. On ImageNet, 16-bit integers are needed for weight accumulation with an 8-bit datapath. This achieves training results comparable to all-floating-point implementations.
Dynamic Sparse Training: Find Efficient Sparse Network From Scratch With Trainable Masked Layers
May 14, 2020
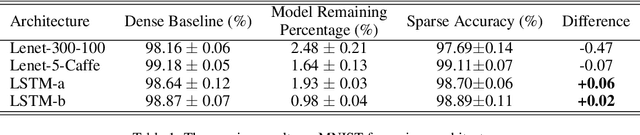

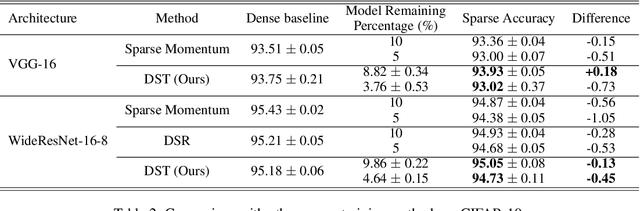
We present a novel network pruning algorithm called Dynamic Sparse Training that can jointly find the optimal network parameters and sparse network structure in a unified optimization process with trainable pruning thresholds. These thresholds can have fine-grained layer-wise adjustments dynamically via backpropagation. We demonstrate that our dynamic sparse training algorithm can easily train very sparse neural network models with little performance loss using the same number of training epochs as dense models. Dynamic Sparse Training achieves the state of the art performance compared with other sparse training algorithms on various network architectures. Additionally, we have several surprising observations that provide strong evidence for the effectiveness and efficiency of our algorithm. These observations reveal the underlying problems of traditional three-stage pruning algorithms and present the potential guidance provided by our algorithm to the design of more compact network architectures.