 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-GINEE: A Tensor-Based Multilayer Graph Representation Learning
May 27, 2026Traditional network analysis focuses on single-layer networks, real-world systems often form multilayer networks with multiple relationship types. However, existing methods typically fail to capture complex inter-layer dependencies by treating layers independently or aggregating them. To address this, we propose T-GINEE (Tensor-Based Generalized Multilayer-graph Estimating Equation), a statistical regularization framework combining tensor-based generalized estimating equations with task-specific loss to model cross-network correlations explicitly. Key innovations include: (1) CP tensor decomposition capturing structural dependencies via shared latent factors; (2) a generalized estimating equation framework modeling inter-layer correlations through working covariance matrices; and (3) a flexible link function accommodating characteristics like sparsity. Our theoretical analysis establishes consistency and asymptotic normality under mild conditions. Extensive experiments on synthetic and real-world datasets validate T-GINEE's effectiveness for multilayer network analysis.
UniRank: Unified List-wise Reranking via Confidence-Ordered Denoising
May 11, 2026List-wise reranking arranges a request-specific pool of candidate items into an ordered slate that maximizes user satisfaction. Existing generative rerankers fall into two paradigms: Autoregressive (AR) rerankers construct the slate left to right and capture inter-item dependencies in the exposure list, but they suffer from error propagation because early mistakes affect subsequent slots. Non-autoregressive (NAR) rerankers predict all slots in parallel and avoid error propagation, but they weaken inter-item interaction modeling under a slot independence assumption. This raises a central question: is there a unified architecture that combines the strengths of both paradigms and delivers stronger reranking performance? We answer this question with UniRank, a unified list-wise reranking framework whose inference time variants recover AR and NAR rerankers as special cases. UniRank integrates bidirectional slate modeling into an iterative denoising process and fills the most confident slot at each step. To instantiate this framework for reranking, we introduce the Task Grounded Diffusion Interface (TGD), which performs denoising at the item level and restricts prediction to the request-specific candidate pool. TGD aggregates each item's semantic tokens into a single item embedding and scores each slot directly against the candidate pool. Experiments on Amazon Books, MovieLens-1M, and an industrial short video dataset show that UniRank consistently outperforms state-of-the-art baselines. Online A/B tests on a real-world industrial platform further validate its effectiveness, yielding significant improvements of +0.159% in user average app-time and +1.016% in share-rate.
SEARCH-R: Structured Entity-Aware Retrieval with Chain-of-Reasoning Navigator for Multi-hop Question Answering
Apr 27, 2026Multi-hop Question Answering (MHQA) aims to answer questions that require multi-step reasoning. It presents two key challenges: generating correct reasoning paths in response to the complex user queries, and accurately retrieving essential knowledge in the face of potential limitations in large language models (LLMs). Existing approaches primarily rely on prompt-based methods to generate reasoning paths, which are further combined with traditional sparse or dense retrieval to produce the final answer. However, the generation of reasoning paths commonly lacks effective control over the generative process, thus leading the reasoning astray. Meanwhile, the retrieval methods over-rely on knowledge matching or similarity scores rather than evaluating the practical utility of the information, resulting in retrieving homogeneous or non-useful information. Therefore, we propose a Structured Entity-Aware Retrieval with Chain-of-Reasoning Navigator framework named SEARCH-R. Specifically, SEARCH-R trains an end-to-end reasoning path navigator, which is able to provide a powerful sub-question decomposer by fine-tuning the Llama3.1-8B model. Moreover, a novel dependency tree-based retrieval is designed to evaluate the informational contribution of the document quantitatively. Extensive experiments on three challenging multi-hop datasets validate the effectiveness of the proposed framework. The code and dataset are available at: https://github.com/Applied-Machine-Learning-Lab/ACL2026_SEARCH-R.
SubFlow: Sub-mode Conditioned Flow Matching for Diverse One-Step Generation
Apr 14, 2026Flow matching has emerged as a powerful generative framework, with recent few-step methods achieving remarkable inference acceleration. However, we identify a critical yet overlooked limitation: these models suffer from severe diversity degradation, concentrating samples on dominant modes while neglecting rare but valid variations of the target distribution. We trace this degradation to averaging distortion: when trained with MSE objectives, class-conditional flows learn a frequency-weighted mean over intra-class sub-modes, causing the model to over-represent high-density modes while systematically neglecting low-density ones. To address this, we propose SubFlow, Sub-mode Conditioned Flow Matching, which eliminates averaging distortion by decomposing each class into fine-grained sub-modes via semantic clustering and conditioning the flow on sub-mode indices. Each conditioned sub-distribution is approximately unimodal, so the learned flow accurately targets individual modes with no averaging distortion, restoring full mode coverage in a single inference step. Crucially, SubFlow is entirely plug-and-play: it integrates seamlessly into existing one-step models such as MeanFlow and Shortcut Models without any architectural modifications. Extensive experiments on ImageNet-256 demonstrate that SubFlow yields substantial gains in generation diversity (Recall) while maintaining competitive image quality (FID), confirming its broad applicability across different one-step generation frameworks. Project page: https://yexionglin.github.io/subflow.
Enhancing Cross-View UAV Geolocalization via LVLM-Driven Relational Modeling
Mar 09, 2026The primary objective of cross-view UAV geolocalization is to identify the exact spatial coordinates of drone-captured imagery by aligning it with extensive, geo-referenced satellite databases. Current approaches typically extract features independently from each perspective and rely on basic heuristics to compute similarity, thereby failing to explicitly capture the essential interactions between different views. To address this limitation, we introduce a novel, plug-and-play ranking architecture designed to explicitly perform joint relational modeling for improved UAV-to-satellite image matching. By harnessing the capabilities of a Large Vision-Language Model (LVLM), our framework effectively learns the deep visual-semantic correlations linking UAV and satellite imagery. Furthermore, we present a novel relational-aware loss function to optimize the training phase. By employing soft labels, this loss provides fine-grained supervision that avoids overly penalizing near-positive matches, ultimately boosting both the model's discriminative power and training stability. Comprehensive evaluations across various baseline architectures and standard benchmarks reveal that the proposed method substantially boosts the retrieval accuracy of existing models, yielding superior performance even under highly demanding conditions.
Renormalization Group Guided Tensor Network Structure Search
Dec 31, 2025Tensor network structure search (TN-SS) aims to automatically discover optimal network topologies and rank configurations for efficient tensor decomposition in high-dimensional data representation. Despite recent advances, existing TN-SS methods face significant limitations in computational tractability, structure adaptivity, and optimization robustness across diverse tensor characteristics. They struggle with three key challenges: single-scale optimization missing multi-scale structures, discrete search spaces hindering smooth structure evolution, and separated structure-parameter optimization causing computational inefficiency. We propose RGTN (Renormalization Group guided Tensor Network search), a physics-inspired framework transforming TN-SS via multi-scale renormalization group flows. Unlike fixed-scale discrete search methods, RGTN uses dynamic scale-transformation for continuous structure evolution across resolutions. Its core innovation includes learnable edge gates for optimization-stage topology modification and intelligent proposals based on physical quantities like node tension measuring local stress and edge information flow quantifying connectivity importance. Starting from low-complexity coarse scales and refining to finer ones, RGTN finds compact structures while escaping local minima via scale-induced perturbations. Extensive experiments on light field data, high-order synthetic tensors, and video completion tasks show RGTN achieves state-of-the-art compression ratios and runs 4-600$\times$ faster than existing methods, validating the effectiveness of our physics-inspired approach.
BlossomRec: Block-level Fused Sparse Attention Mechanism for Sequential Recommendations
Dec 15, 2025Transformer structures have been widely used in sequential recommender systems (SRS). However, as user interaction histories increase, computational time and memory requirements also grow. This is mainly caused by the standard attention mechanism. Although there exist many methods employing efficient attention and SSM-based models, these approaches struggle to effectively model long sequences and may exhibit unstable performance on short sequences. To address these challenges, we design a sparse attention mechanism, BlossomRec, which models both long-term and short-term user interests through attention computation to achieve stable performance across sequences of varying lengths. Specifically, we categorize user interests in recommendation systems into long-term and short-term interests, and compute them using two distinct sparse attention patterns, with the results combined through a learnable gated output. Theoretically, it significantly reduces the number of interactions participating in attention computation. Extensive experiments on four public datasets demonstrate that BlossomRec, when integrated with state-of-the-art Transformer-based models, achieves comparable or even superior performance while significantly reducing memory usage, providing strong evidence of BlossomRec's efficiency and effectiveness.The code is available at https://github.com/ronineume/BlossomRec.
ODMA: On-Demand Memory Allocation Framework for LLM Serving on LPDDR-Class Accelerators
Dec 10, 2025Serving large language models (LLMs) on accelerators with poor random-access bandwidth (e.g., LPDDR5-based) is limited by current memory managers. Static pre-allocation wastes memory, while fine-grained paging (e.g., PagedAttention) is ill-suited due to high random-access costs. Existing HBM-centric solutions do not exploit the characteristics of random-access-constrained memory (RACM) accelerators like Cambricon MLU370. We present ODMA, an on-demand memory allocation framework for RACM. ODMA addresses distribution drift and heavy-tailed requests by coupling a lightweight length predictor with dynamic bucket partitioning and a large-bucket safeguard. Boundaries are periodically updated from live traces to maximize utilization. On Alpaca and Google-NQ, ODMA improves prediction accuracy of prior work significantly (e.g., from 82.68% to 93.36%). Serving DeepSeek-R1-Distill-Qwen-7B on Cambricon MLU370-X4, ODMA raises memory utilization from 55.05% to 72.45% and improves RPS and TPS by 29% and 27% over static baselines. This demonstrates that hardware-aware allocation unlocks efficient LLM serving on RACM platforms.
Model Merging for Knowledge Editing
Jun 14, 2025Large Language Models (LLMs) require continuous updates to maintain accurate and current knowledge as the world evolves. While existing knowledge editing approaches offer various solutions for knowledge updating, they often struggle with sequential editing scenarios and harm the general capabilities of the model, thereby significantly hampering their practical applicability. This paper proposes a two-stage framework combining robust supervised fine-tuning (R-SFT) with model merging for knowledge editing. Our method first fine-tunes the LLM to internalize new knowledge fully, then merges the fine-tuned model with the original foundation model to preserve newly acquired knowledge and general capabilities. Experimental results demonstrate that our approach significantly outperforms existing methods in sequential editing while better preserving the original performance of the model, all without requiring any architectural changes. Code is available at: https://github.com/Applied-Machine-Learning-Lab/MM4KE.
* 11 pages, 3 figures
Training-free LLM Merging for Multi-task Learning
Jun 14, 2025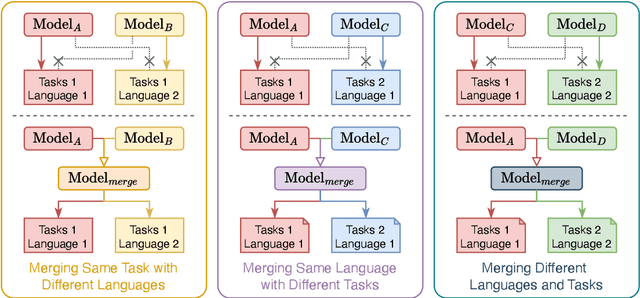
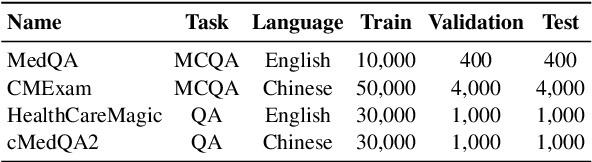
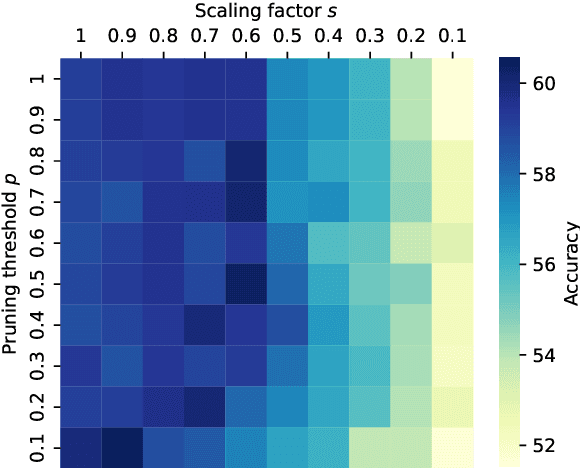
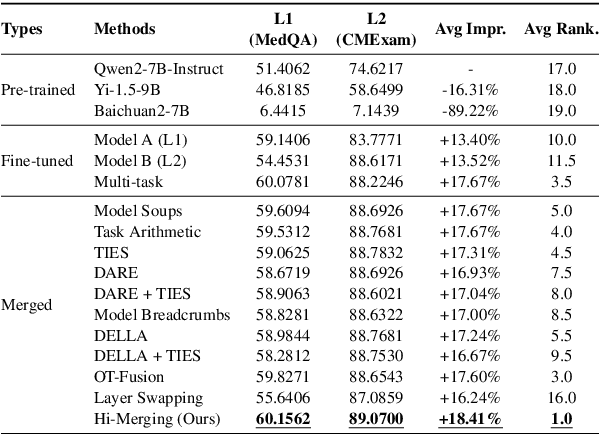
Large Language Models (LLMs) have demonstrated exceptional capabilities across diverse natural language processing (NLP) tasks. The release of open-source LLMs like LLaMA and Qwen has triggered the development of numerous fine-tuned models tailored for various tasks and languages. In this paper, we explore an important question: is it possible to combine these specialized models to create a unified model with multi-task capabilities. We introduces Hierarchical Iterative Merging (Hi-Merging), a training-free method for unifying different specialized LLMs into a single model. Specifically, Hi-Merging employs model-wise and layer-wise pruning and scaling, guided by contribution analysis, to mitigate parameter conflicts. Extensive experiments on multiple-choice and question-answering tasks in both Chinese and English validate Hi-Merging's ability for multi-task learning. The results demonstrate that Hi-Merging consistently outperforms existing merging techniques and surpasses the performance of models fine-tuned on combined datasets in most scenarios. Code is available at: https://github.com/Applied-Machine-Learning-Lab/Hi-Merging.
* 14 pages, 6 figures