 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBabelBench: An Omni Benchmark for Code-Driven Analysis of Multimodal and Multistructured Data
Oct 01, 2024



Large language models (LLMs) have become increasingly pivotal across various domains, especially in handling complex data types. This includes structured data processing, as exemplified by ChartQA and ChatGPT-Ada, and multimodal unstructured data processing as seen in Visual Question Answering (VQA). These areas have attracted significant attention from both industry and academia. Despite this, there remains a lack of unified evaluation methodologies for these diverse data handling scenarios. In response, we introduce BabelBench, an innovative benchmark framework that evaluates the proficiency of LLMs in managing multimodal multistructured data with code execution. BabelBench incorporates a dataset comprising 247 meticulously curated problems that challenge the models with tasks in perception, commonsense reasoning, logical reasoning, and so on. Besides the basic capabilities of multimodal understanding, structured data processing as well as code generation, these tasks demand advanced capabilities in exploration, planning, reasoning and debugging. Our experimental findings on BabelBench indicate that even cutting-edge models like ChatGPT 4 exhibit substantial room for improvement. The insights derived from our comprehensive analysis offer valuable guidance for future research within the community. The benchmark data can be found at https://github.com/FFD8FFE/babelbench.
ViTAR: Vision Transformer with Any Resolution
Mar 28, 2024



This paper tackles a significant challenge faced by Vision Transformers (ViTs): their constrained scalability across different image resolutions. Typically, ViTs experience a performance decline when processing resolutions different from those seen during training. Our work introduces two key innovations to address this issue. Firstly, we propose a novel module for dynamic resolution adjustment, designed with a single Transformer block, specifically to achieve highly efficient incremental token integration. Secondly, we introduce fuzzy positional encoding in the Vision Transformer to provide consistent positional awareness across multiple resolutions, thereby preventing overfitting to any single training resolution. Our resulting model, ViTAR (Vision Transformer with Any Resolution), demonstrates impressive adaptability, achieving 83.3\% top-1 accuracy at a 1120x1120 resolution and 80.4\% accuracy at a 4032x4032 resolution, all while reducing computational costs. ViTAR also shows strong performance in downstream tasks such as instance and semantic segmentation and can easily combined with self-supervised learning techniques like Masked AutoEncoder. Our work provides a cost-effective solution for enhancing the resolution scalability of ViTs, paving the way for more versatile and efficient high-resolution image processing.
$\mathbf{}$-Puzzle: A Cost-Efficient Testbed for Benchmarking Reinforcement Learning Algorithms in Generative Language Model
Mar 11, 2024



Recent advances in reinforcement learning (RL) algorithms aim to enhance the performance of language models at scale. Yet, there is a noticeable absence of a cost-effective and standardized testbed tailored to evaluating and comparing these algorithms. To bridge this gap, we present a generalized version of the 24-Puzzle: the $(N,K)$-Puzzle, which challenges language models to reach a target value $K$ with $N$ integers. We evaluate the effectiveness of established RL algorithms such as Proximal Policy Optimization (PPO), alongside novel approaches like Identity Policy Optimization (IPO) and Direct Policy Optimization (DPO).
InfiMM-HD: A Leap Forward in High-Resolution Multimodal Understanding
Mar 03, 2024Multimodal Large Language Models (MLLMs) have experienced significant advancements recently. Nevertheless, challenges persist in the accurate recognition and comprehension of intricate details within high-resolution images. Despite being indispensable for the development of robust MLLMs, this area remains underinvestigated. To tackle this challenge, our work introduces InfiMM-HD, a novel architecture specifically designed for processing images of different resolutions with low computational overhead. This innovation facilitates the enlargement of MLLMs to higher-resolution capabilities. InfiMM-HD incorporates a cross-attention module and visual windows to reduce computation costs. By integrating this architectural design with a four-stage training pipeline, our model attains improved visual perception efficiently and cost-effectively. Empirical study underscores the robustness and effectiveness of InfiMM-HD, opening new avenues for exploration in related areas. Codes and models can be found at https://huggingface.co/Infi-MM/infimm-hd
Video-Teller: Enhancing Cross-Modal Generation with Fusion and Decoupling
Oct 11, 2023This paper proposes Video-Teller, a video-language foundation model that leverages multi-modal fusion and fine-grained modality alignment to significantly enhance the video-to-text generation task. Video-Teller boosts the training efficiency by utilizing frozen pretrained vision and language modules. It capitalizes on the robust linguistic capabilities of large language models, enabling the generation of both concise and elaborate video descriptions. To effectively integrate visual and auditory information, Video-Teller builds upon the image-based BLIP-2 model and introduces a cascaded Q-Former which fuses information across frames and ASR texts. To better guide video summarization, we introduce a fine-grained modality alignment objective, where the cascaded Q-Former's output embedding is trained to align with the caption/summary embedding created by a pretrained text auto-encoder. Experimental results demonstrate the efficacy of our proposed video-language foundation model in accurately comprehending videos and generating coherent and precise language descriptions. It is worth noting that the fine-grained alignment enhances the model's capabilities (4% improvement of CIDEr score on MSR-VTT) with only 13% extra parameters in training and zero additional cost in inference.
Video-CSR: Complex Video Digest Creation for Visual-Language Models
Oct 08, 2023



We present a novel task and human annotated dataset for evaluating the ability for visual-language models to generate captions and summaries for real-world video clips, which we call Video-CSR (Captioning, Summarization and Retrieval). The dataset contains 4.8K YouTube video clips of 20-60 seconds in duration and covers a wide range of topics and interests. Each video clip corresponds to 5 independently annotated captions (1 sentence) and summaries (3-10 sentences). Given any video selected from the dataset and its corresponding ASR information, we evaluate visual-language models on either caption or summary generation that is grounded in both the visual and auditory content of the video. Additionally, models are also evaluated on caption- and summary-based retrieval tasks, where the summary-based retrieval task requires the identification of a target video given excerpts of a corresponding summary. Given the novel nature of the paragraph-length video summarization task, we perform extensive comparative analyses of different existing evaluation metrics and their alignment with human preferences. Finally, we propose a foundation model with competitive generation and retrieval capabilities that serves as a baseline for the Video-CSR task. We aim for Video-CSR to serve as a useful evaluation set in the age of large language models and complex multi-modal tasks.
SimVLG: Simple and Efficient Pretraining of Visual Language Generative Models
Oct 07, 2023



In this paper, we propose ``SimVLG'', a streamlined framework for the pre-training of computationally intensive vision-language generative models, leveraging frozen pre-trained large language models (LLMs). The prevailing paradigm in vision-language pre-training (VLP) typically involves a two-stage optimization process: an initial resource-intensive phase dedicated to general-purpose vision-language representation learning, aimed at extracting and consolidating pertinent visual features, followed by a subsequent phase focusing on end-to-end alignment between visual and linguistic modalities. Our one-stage, single-loss framework circumvents the aforementioned computationally demanding first stage of training by gradually merging similar visual tokens during training. This gradual merging process effectively compacts the visual information while preserving the richness of semantic content, leading to fast convergence without sacrificing performance. Our experiments show that our approach can speed up the training of vision-language models by a factor $\times 5$ without noticeable impact on the overall performance. Additionally, we show that our models can achieve comparable performance to current vision-language models with only $1/10$ of the data. Finally, we demonstrate how our image-text models can be easily adapted to video-language generative tasks through a novel soft attentive temporal token merging modules.
$\mathcal{B}$-Coder: Value-Based Deep Reinforcement Learning for Program Synthesis
Oct 04, 2023



Program synthesis aims to create accurate, executable code from natural language descriptions. This field has leveraged the power of reinforcement learning (RL) in conjunction with large language models (LLMs), significantly enhancing code generation capabilities. This integration focuses on directly optimizing functional correctness, transcending conventional supervised losses. While current literature predominantly favors policy-based algorithms, attributes of program synthesis suggest a natural compatibility with value-based methods. This stems from rich collection of off-policy programs developed by human programmers, and the straightforward verification of generated programs through automated unit testing (i.e. easily obtainable rewards in RL language). Diverging from the predominant use of policy-based algorithms, our work explores the applicability of value-based approaches, leading to the development of our $\mathcal{B}$-Coder (pronounced Bellman coder). Yet, training value-based methods presents challenges due to the enormous search space inherent to program synthesis. To this end, we propose an initialization protocol for RL agents utilizing pre-trained LMs and a conservative Bellman operator to reduce training complexities. Moreover, we demonstrate how to leverage the learned value functions as a dual strategy to post-process generated programs. Our empirical evaluations demonstrated $\mathcal{B}$-Coder's capability in achieving state-of-the-art performance compared with policy-based methods. Remarkably, this achievement is reached with minimal reward engineering effort, highlighting the effectiveness of value-based RL, independent of reward designs.
DGRec: Graph Neural Network for Recommendation with Diversified Embedding Generation
Nov 27, 2022



Graph Neural Network (GNN) based recommender systems have been attracting more and more attention in recent years due to their excellent performance in accuracy. Representing user-item interactions as a bipartite graph, a GNN model generates user and item representations by aggregating embeddings of their neighbors. However, such an aggregation procedure often accumulates information purely based on the graph structure, overlooking the redundancy of the aggregated neighbors and resulting in poor diversity of the recommended list. In this paper, we propose diversifying GNN-based recommender systems by directly improving the embedding generation procedure. Particularly, we utilize the following three modules: submodular neighbor selection to find a subset of diverse neighbors to aggregate for each GNN node, layer attention to assign attention weights for each layer, and loss reweighting to focus on the learning of items belonging to long-tail categories. Blending the three modules into GNN, we present DGRec(Diversified GNN-based Recommender System) for diversified recommendation. Experiments on real-world datasets demonstrate that the proposed method can achieve the best diversity while keeping the accuracy comparable to state-of-the-art GNN-based recommender systems.
A Template-guided Hybrid Pointer Network for Knowledge-basedTask-oriented Dialogue Systems
Jun 10, 2021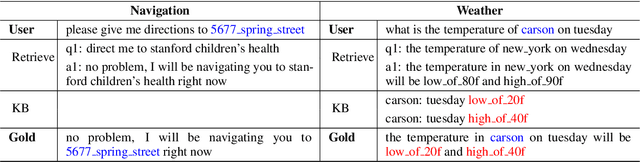
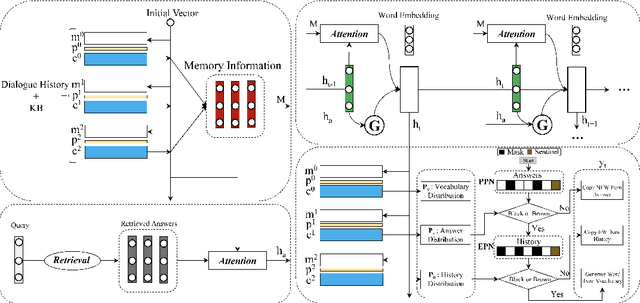
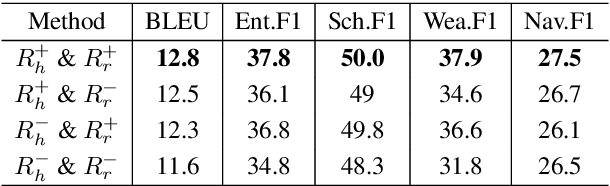
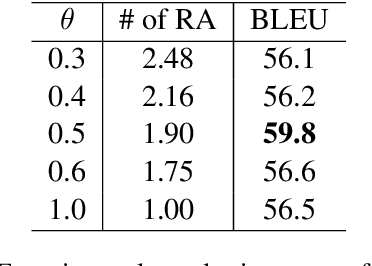
Most existing neural network based task-oriented dialogue systems follow encoder-decoder paradigm, where the decoder purely depends on the source texts to generate a sequence of words, usually suffering from instability and poor readability. Inspired by the traditional template-based generation approaches, we propose a template-guided hybrid pointer network for the knowledge-based task-oriented dialogue system, which retrieves several potentially relevant answers from a pre-constructed domain-specific conversational repository as guidance answers, and incorporates the guidance answers into both the encoding and decoding processes. Specifically, we design a memory pointer network model with a gating mechanism to fully exploit the semantic correlation between the retrieved answers and the ground-truth response. We evaluate our model on four widely used task-oriented datasets, including one simulated and three manually created datasets. The experimental results demonstrate that the proposed model achieves significantly better performance than the state-of-the-art methods over different automatic evaluation metrics.