 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Passive and Active: Enhancing Conversation Starter Recommendation via Active Expression Modeling
May 07, 2026Large Language Model (LLM)-driven conversational search is shifting information retrieval from reactive keyword matching to proactive, open-ended dialogues. In this context, Conversation Starters are widely deployed to provide personalized query recommendations that help users initiate dialogues. Conventionally, recommending these starters relies on a closed "exposure-click" loop. Yet, this feedback loop mechanism traps the system in an echo chamber where, compounded by data sparsity, it fails to capture the dynamic nature of conversational search intents shaped by the open world. As a result, the system skews towards popular but generic suggestions.In this work, we uncover an untapped paradigm shift to shatter this harmful feedback loop: harnessing user "free will" through active user expressions. Unlike traditional recommendations, conversational search empowers users to bypass menus entirely through manually typed queries. The open-world intents in active queries hold the key to breaking this loop. However, incorporating them is non-trivial: (1) there exists an inherent distribution shift between active queries and formulated starters. (2) Furthermore, the "non-ID-able" nature of open text renders traditional item-based popularity statistics ineffective for large-scale industrial streaming training. To this end, we propose Passive-Active Bridge (PA-Bridge), a novel framework that employs an adversarial distribution aligner to bridge the distributional gap between passively recommended starters and active expressions. Moreover, we introduce a semantic discretizer to enable the deployment of popularity debiasing algorithms. Online A/B tests on our platform, demonstrate that PA-Bridge significantly boosts the Feature Penetration Rate by 0.54% and User Active Days
CDC: Causal Domain Clustering for Multi-Domain Recommendation
Jul 09, 2025Multi-domain recommendation leverages domain-general knowledge to improve recommendations across several domains. However, as platforms expand to dozens or hundreds of scenarios, training all domains in a unified model leads to performance degradation due to significant inter-domain differences. Existing domain grouping methods, based on business logic or data similarities, often fail to capture the true transfer relationships required for optimal grouping. To effectively cluster domains, we propose Causal Domain Clustering (CDC). CDC models domain transfer patterns within a large number of domains using two distinct effects: the Isolated Domain Affinity Matrix for modeling non-interactive domain transfers, and the Hybrid Domain Affinity Matrix for considering dynamic domain synergy or interference under joint training. To integrate these two transfer effects, we introduce causal discovery to calculate a cohesion-based coefficient that adaptively balances their contributions. A Co-Optimized Dynamic Clustering algorithm iteratively optimizes target domain clustering and source domain selection for training. CDC significantly enhances performance across over 50 domains on public datasets and in industrial settings, achieving a 4.9% increase in online eCPM. Code is available at https://github.com/Chrissie-Law/Causal-Domain-Clustering-for-Multi-Domain-Recommendation
Measure Domain's Gap: A Similar Domain Selection Principle for Multi-Domain Recommendation
May 26, 2025Multi-Domain Recommendation (MDR) achieves the desirable recommendation performance by effectively utilizing the transfer information across different domains. Despite the great success, most existing MDR methods adopt a single structure to transfer complex domain-shared knowledge. However, the beneficial transferring information should vary across different domains. When there is knowledge conflict between domains or a domain is of poor quality, unselectively leveraging information from all domains will lead to a serious Negative Transfer Problem (NTP). Therefore, how to effectively model the complex transfer relationships between domains to avoid NTP is still a direction worth exploring. To address these issues, we propose a simple and dynamic Similar Domain Selection Principle (SDSP) for multi-domain recommendation in this paper. SDSP presents the initial exploration of selecting suitable domain knowledge for each domain to alleviate NTP. Specifically, we propose a novel prototype-based domain distance measure to effectively model the complexity relationship between domains. Thereafter, the proposed SDSP can dynamically find similar domains for each domain based on the supervised signals of the domain metrics and the unsupervised distance measure from the learned domain prototype. We emphasize that SDSP is a lightweight method that can be incorporated with existing MDR methods for better performance while not introducing excessive time overheads. To the best of our knowledge, it is the first solution that can explicitly measure domain-level gaps and dynamically select appropriate domains in the MDR field. Extensive experiments on three datasets demonstrate the effectiveness of our proposed method.
One for Dozens: Adaptive REcommendation for All Domains with Counterfactual Augmentation
Dec 16, 2024



Multi-domain recommendation (MDR) aims to enhance recommendation performance across various domains. However, real-world recommender systems in online platforms often need to handle dozens or even hundreds of domains, far exceeding the capabilities of traditional MDR algorithms, which typically focus on fewer than five domains. Key challenges include a substantial increase in parameter count, high maintenance costs, and intricate knowledge transfer patterns across domains. Furthermore, minor domains often suffer from data sparsity, leading to inadequate training in classical methods. To address these issues, we propose Adaptive REcommendation for All Domains with counterfactual augmentation (AREAD). AREAD employs a hierarchical structure with a limited number of expert networks at several layers, to effectively capture domain knowledge at different granularities. To adaptively capture the knowledge transfer pattern across domains, we generate and iteratively prune a hierarchical expert network selection mask for each domain during training. Additionally, counterfactual assumptions are used to augment data in minor domains, supporting their iterative mask pruning. Our experiments on two public datasets, each encompassing over twenty domains, demonstrate AREAD's effectiveness, especially in data-sparse domains. Source code is available at https://github.com/Chrissie-Law/AREAD-Multi-Domain-Recommendation.
Unified Dual-Intent Translation for Joint Modeling of Search and Recommendation
Jul 01, 2024



Recommendation systems, which assist users in discovering their preferred items among numerous options, have served billions of users across various online platforms. Intuitively, users' interactions with items are highly driven by their unchanging inherent intents (e.g., always preferring high-quality items) and changing demand intents (e.g., wanting a T-shirt in summer but a down jacket in winter). However, both types of intents are implicitly expressed in recommendation scenario, posing challenges in leveraging them for accurate intent-aware recommendations. Fortunately, in search scenario, often found alongside recommendation on the same online platform, users express their demand intents explicitly through their query words. Intuitively, in both scenarios, a user shares the same inherent intent and the interactions may be influenced by the same demand intent. It is therefore feasible to utilize the interaction data from both scenarios to reinforce the dual intents for joint intent-aware modeling. But the joint modeling should deal with two problems: 1) accurately modeling users' implicit demand intents in recommendation; 2) modeling the relation between the dual intents and the interactive items. To address these problems, we propose a novel model named Unified Dual-Intents Translation for joint modeling of Search and Recommendation (UDITSR). To accurately simulate users' demand intents in recommendation, we utilize real queries from search data as supervision information to guide its generation. To explicitly model the relation among the triplet <inherent intent, demand intent, interactive item>, we propose a dual-intent translation propagation mechanism to learn the triplet in the same semantic space via embedding translations. Extensive experiments demonstrate that UDITSR outperforms SOTA baselines both in search and recommendation tasks.
DFGNN: Dual-frequency Graph Neural Network for Sign-aware Feedback
May 24, 2024



The graph-based recommendation has achieved great success in recent years. However, most existing graph-based recommendations focus on capturing user preference based on positive edges/feedback, while ignoring negative edges/feedback (e.g., dislike, low rating) that widely exist in real-world recommender systems. How to utilize negative feedback in graph-based recommendations still remains underexplored. In this study, we first conducted a comprehensive experimental analysis and found that (1) existing graph neural networks are not well-suited for modeling negative feedback, which acts as a high-frequency signal in a user-item graph. (2) The graph-based recommendation suffers from the representation degeneration problem. Based on the two observations, we propose a novel model that models positive and negative feedback from a frequency filter perspective called Dual-frequency Graph Neural Network for Sign-aware Recommendation (DFGNN). Specifically, in DFGNN, the designed dual-frequency graph filter (DGF) captures both low-frequency and high-frequency signals that contain positive and negative feedback. Furthermore, the proposed signed graph regularization is applied to maintain the user/item embedding uniform in the embedding space to alleviate the representation degeneration problem. Additionally, we conduct extensive experiments on real-world datasets and demonstrate the effectiveness of the proposed model. Codes of our model will be released upon acceptance.
ID-centric Pre-training for Recommendation
May 07, 2024



Classical sequential recommendation models generally adopt ID embeddings to store knowledge learned from user historical behaviors and represent items. However, these unique IDs are challenging to be transferred to new domains. With the thriving of pre-trained language model (PLM), some pioneer works adopt PLM for pre-trained recommendation, where modality information (e.g., text) is considered universal across domains via PLM. Unfortunately, the behavioral information in ID embeddings is still verified to be dominating in PLM-based recommendation models compared to modality information and thus limits these models' performance. In this work, we propose a novel ID-centric recommendation pre-training paradigm (IDP), which directly transfers informative ID embeddings learned in pre-training domains to item representations in new domains. Specifically, in pre-training stage, besides the ID-based sequential model for recommendation, we also build a Cross-domain ID-matcher (CDIM) learned by both behavioral and modality information. In the tuning stage, modality information of new domain items is regarded as a cross-domain bridge built by CDIM. We first leverage the textual information of downstream domain items to retrieve behaviorally and semantically similar items from pre-training domains using CDIM. Next, these retrieved pre-trained ID embeddings, rather than certain textual embeddings, are directly adopted to generate downstream new items' embeddings. Through extensive experiments on real-world datasets, both in cold and warm settings, we demonstrate that our proposed model significantly outperforms all baselines. Codes will be released upon acceptance.
Modeling Dual Period-Varying Preferences for Takeaway Recommendation
Jun 16, 2023



Takeaway recommender systems, which aim to accurately provide stores that offer foods meeting users' interests, have served billions of users in our daily life. Different from traditional recommendation, takeaway recommendation faces two main challenges: (1) Dual Interaction-Aware Preference Modeling. Traditional recommendation commonly focuses on users' single preferences for items while takeaway recommendation needs to comprehensively consider users' dual preferences for stores and foods. (2) Period-Varying Preference Modeling. Conventional recommendation generally models continuous changes in users' preferences from a session-level or day-level perspective. However, in practical takeaway systems, users' preferences vary significantly during the morning, noon, night, and late night periods of the day. To address these challenges, we propose a Dual Period-Varying Preference modeling (DPVP) for takeaway recommendation. Specifically, we design a dual interaction-aware module, aiming to capture users' dual preferences based on their interactions with stores and foods. Moreover, to model various preferences in different time periods of the day, we propose a time-based decomposition module as well as a time-aware gating mechanism. Extensive offline and online experiments demonstrate that our model outperforms state-of-the-art methods on real-world datasets and it is capable of modeling the dual period-varying preferences. Moreover, our model has been deployed online on Meituan Takeaway platform, leading to an average improvement in GMV (Gross Merchandise Value) of 0.70%.
Attacking Pre-trained Recommendation
May 06, 2023Recently, a series of pioneer studies have shown the potency of pre-trained models in sequential recommendation, illuminating the path of building an omniscient unified pre-trained recommendation model for different downstream recommendation tasks. Despite these advancements, the vulnerabilities of classical recommender systems also exist in pre-trained recommendation in a new form, while the security of pre-trained recommendation model is still unexplored, which may threaten its widely practical applications. In this study, we propose a novel framework for backdoor attacking in pre-trained recommendation. We demonstrate the provider of the pre-trained model can easily insert a backdoor in pre-training, thereby increasing the exposure rates of target items to target user groups. Specifically, we design two novel and effective backdoor attacks: basic replacement and prompt-enhanced, under various recommendation pre-training usage scenarios. Experimental results on real-world datasets show that our proposed attack strategies significantly improve the exposure rates of target items to target users by hundreds of times in comparison to the clean model.
Personalized Prompts for Sequential Recommendation
May 19, 2022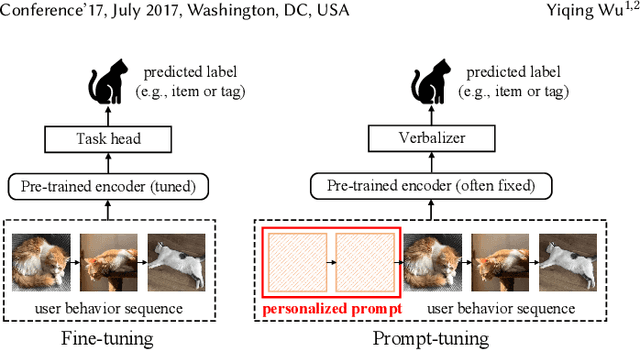
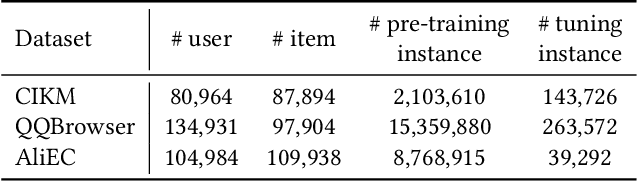
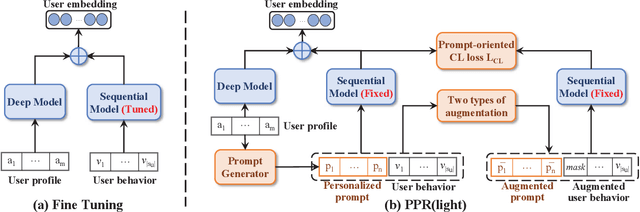
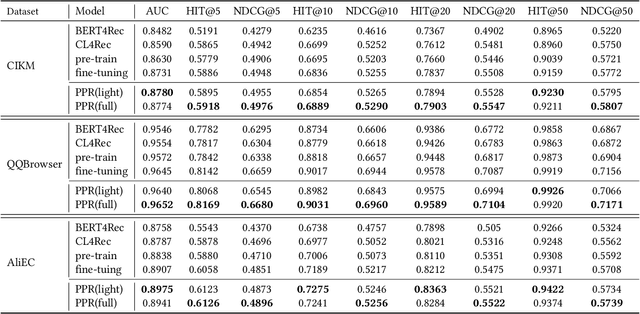
Pre-training models have shown their power in sequential recommendation. Recently, prompt has been widely explored and verified for tuning in NLP pre-training, which could help to more effectively and efficiently extract useful knowledge from pre-training models for downstream tasks, especially in cold-start scenarios. However, it is challenging to bring prompt-tuning from NLP to recommendation, since the tokens in recommendation (i.e., items) do not have explicit explainable semantics, and the sequence modeling should be personalized. In this work, we first introduces prompt to recommendation and propose a novel Personalized prompt-based recommendation (PPR) framework for cold-start recommendation. Specifically, we build the personalized soft prefix prompt via a prompt generator based on user profiles and enable a sufficient training of prompts via a prompt-oriented contrastive learning with both prompt- and behavior-based augmentations. We conduct extensive evaluations on various tasks. In both few-shot and zero-shot recommendation, PPR models achieve significant improvements over baselines on various metrics in three large-scale open datasets. We also conduct ablation tests and sparsity analysis for a better understanding of PPR. Moreover, We further verify PPR's universality on different pre-training models, and conduct explorations on PPR's other promising downstream tasks including cross-domain recommendation and user profile prediction.