 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatbots for Mental Health Support: Exploring the Impact of Emohaa on Reducing Mental Distress in China
Sep 21, 2022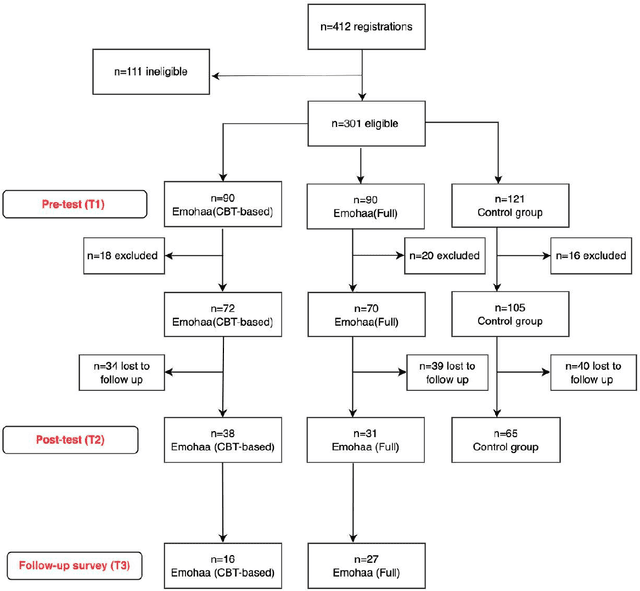

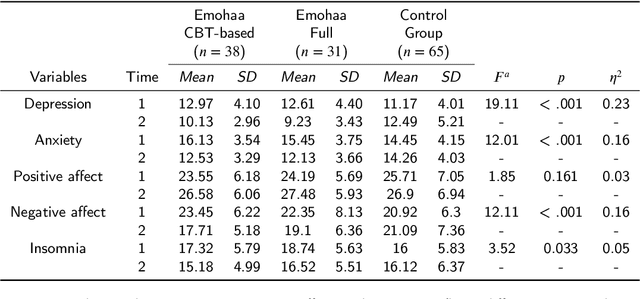
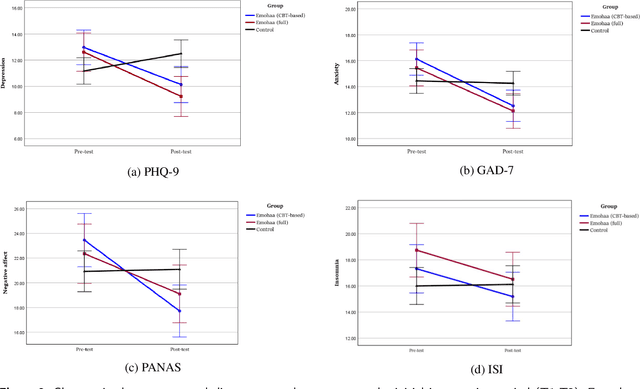
The growing demand for mental health support has highlighted the importance of conversational agents as human supporters worldwide and in China. These agents could increase availability and reduce the relative costs of mental health support. The provided support can be divided into two main types: cognitive and emotional support. Existing work on this topic mainly focuses on constructing agents that adopt Cognitive Behavioral Therapy (CBT) principles. Such agents operate based on pre-defined templates and exercises to provide cognitive support. However, research on emotional support using such agents is limited. In addition, most of the constructed agents operate in English, highlighting the importance of conducting such studies in China. In this study, we analyze the effectiveness of Emohaa in reducing symptoms of mental distress. Emohaa is a conversational agent that provides cognitive support through CBT-based exercises and guided conversations. It also emotionally supports users by enabling them to vent their desired emotional problems. The study included 134 participants, split into three groups: Emohaa (CBT-based), Emohaa (Full), and control. Experimental results demonstrated that compared to the control group, participants who used Emohaa experienced considerably more significant improvements in symptoms of mental distress. We also found that adding the emotional support agent had a complementary effect on such improvements, mainly depression and insomnia. Based on the obtained results and participants' satisfaction with the platform, we concluded that Emohaa is a practical and effective tool for reducing mental distress.
Lifelong Learning for Question Answering with Hierarchical Prompts
Aug 31, 2022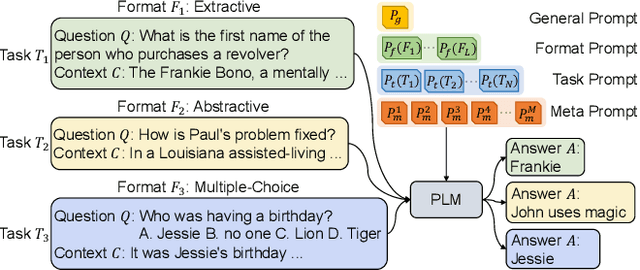
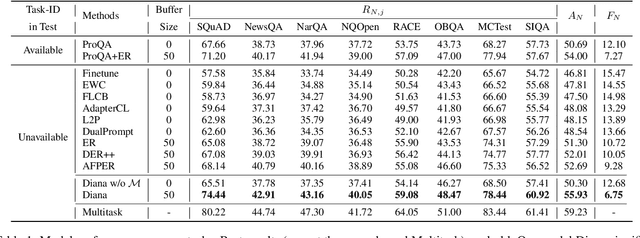
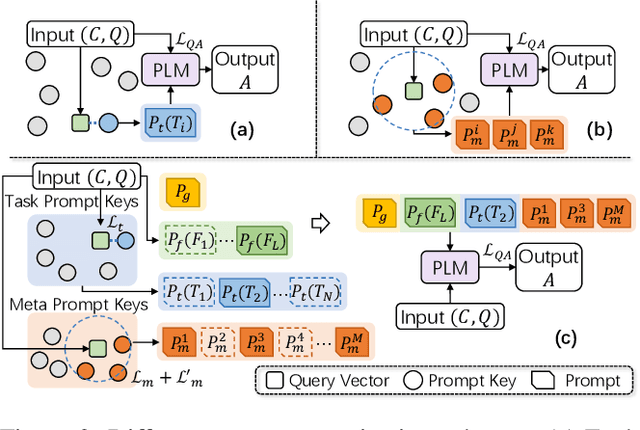
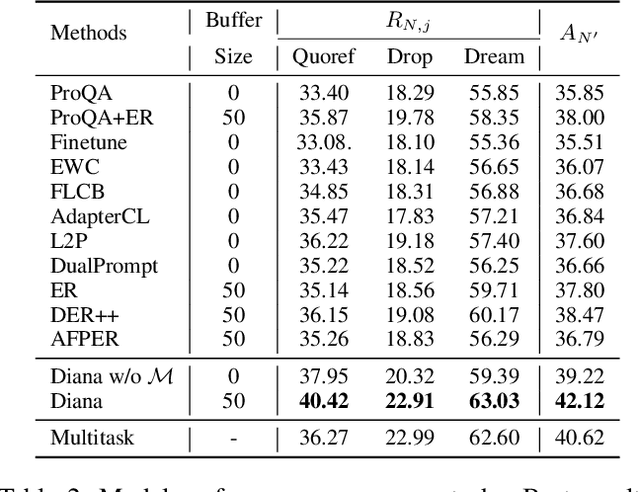
QA models with lifelong learning (LL) abilities are important for practical QA applications, and architecture-based LL methods are reported to be an effective implementation for these models. However, it is non-trivial to extend previous approaches to QA tasks since they either require access to task identities in the testing phase or do not explicitly model samples from unseen tasks. In this paper, we propose Diana: a dynamic architecture-based lifelong QA model that tries to learn a sequence of QA tasks with a prompt enhanced language model. Four types of hierarchically organized prompts are used in Diana to capture QA knowledge from different granularities. Specifically, we dedicate task-level prompts to capture task-specific knowledge to retain high LL performances and maintain instance-level prompts to learn knowledge shared across different input samples to improve the model's generalization performance. Moreover, we dedicate separate prompts to explicitly model unseen tasks and introduce a set of prompt key vectors to facilitate knowledge sharing between tasks. Extensive experiments demonstrate that Diana outperforms state-of-the-art lifelong QA models, especially in handling unseen tasks.
Accuracy on In-Domain Samples Matters When Building Out-of-Domain detectors: A Reply to Marek et al.
May 24, 2022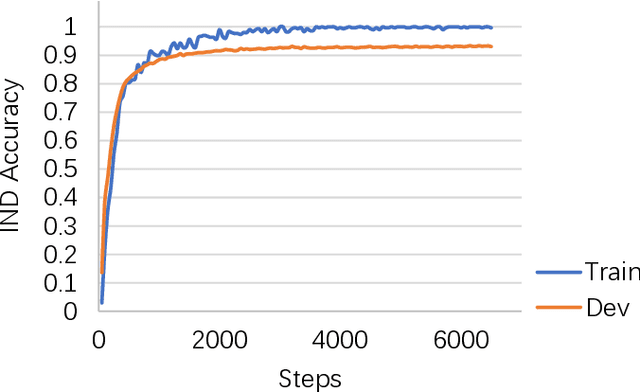
We have noticed that Marek et al. (2021) try to re-implement our paper Zheng et al. (2020a) in their work "OodGAN: Generative Adversarial Network for Out-of-Domain Data Generation". Our paper proposes a model to generate pseudo OOD samples that are akin to IN-Domain (IND) input utterances. These pseudo OOD samples can be used to improve the OOD detection performance by optimizing an entropy regularization term when building the IND classifier. Marek et al. (2021) report a large gap between their re-implemented results and ours on the CLINC150 dataset (Larson et al., 2019). This paper discusses some key observations that may have led to such a large gap. Most of these observations originate from our experiments because Marek et al. (2021) have not released their codes1. One of the most important observations is that stronger IND classifiers usually exhibit a more robust ability to detect OOD samples. We hope these observations help other researchers, including Marek et al. (2021), to develop better OOD detectors in their applications.
Rethinking and Refining the Distinct Metric
Apr 03, 2022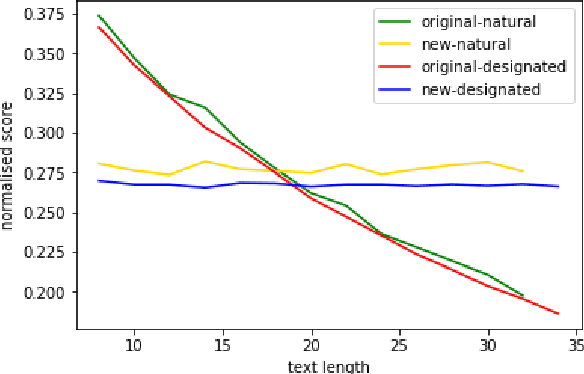

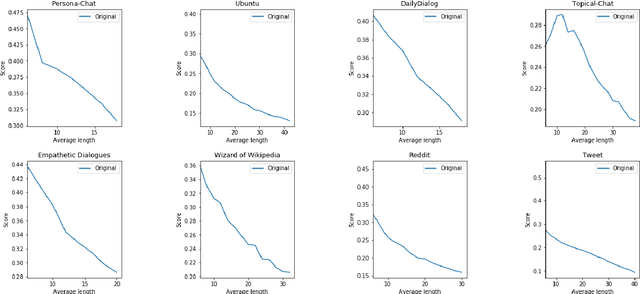
Distinct-$n$ score\cite{Li2016} is a widely used automatic metric for evaluating diversity in language generation tasks. However, we observed that the original approach for calculating distinct scores has evident biases that tend to assign higher penalties to longer sequences. We refine the calculation of distinct scores by scaling the number of distinct tokens based on their expectations. We provide both empirical and theoretical evidence to show that our method effectively removes the biases existing in the original distinct score. Our experiments show that our proposed metric, \textit{Expectation-Adjusted Distinct (EAD)}, correlates better with human judgment in evaluating response diversity. To foster future research, we provide an example implementation at \url{https://github.com/lsy641/Expectation-Adjusted-Distinct}.
Chat-Capsule: A Hierarchical Capsule for Dialog-level Emotion Analysis
Mar 23, 2022

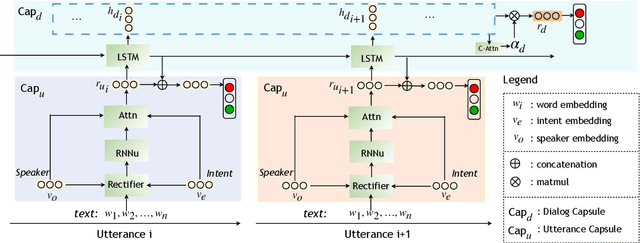
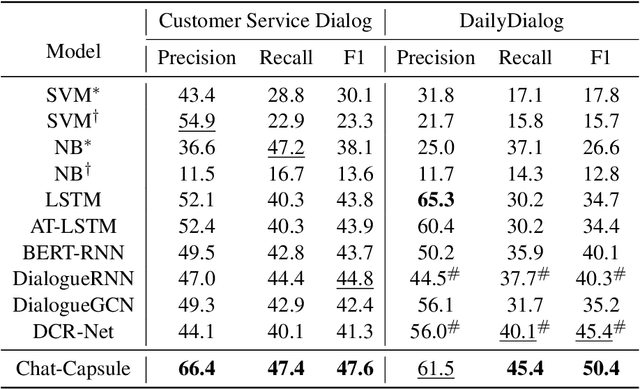
Many studies on dialog emotion analysis focus on utterance-level emotion only. These models hence are not optimized for dialog-level emotion detection, i.e. to predict the emotion category of a dialog as a whole. More importantly, these models cannot benefit from the context provided by the whole dialog. In real-world applications, annotations to dialog could fine-grained, including both utterance-level tags (e.g. speaker type, intent category, and emotion category), and dialog-level tags (e.g. user satisfaction, and emotion curve category). In this paper, we propose a Context-based Hierarchical Attention Capsule~(Chat-Capsule) model, which models both utterance-level and dialog-level emotions and their interrelations. On a dialog dataset collected from customer support of an e-commerce platform, our model is also able to predict user satisfaction and emotion curve category. Emotion curve refers to the change of emotions along the development of a conversation. Experiments show that the proposed Chat-Capsule outperform state-of-the-art baselines on both benchmark dataset and proprietary dataset. Source code will be released upon acceptance.
Improving Meta-learning for Low-resource Text Classification and Generation via Memory Imitation
Mar 22, 2022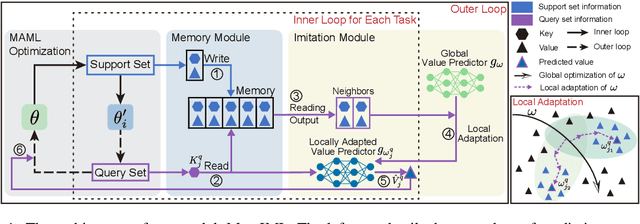
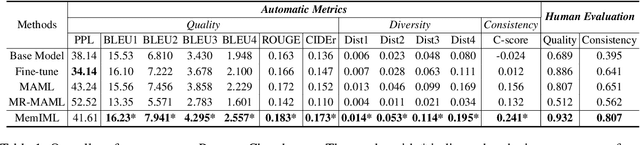
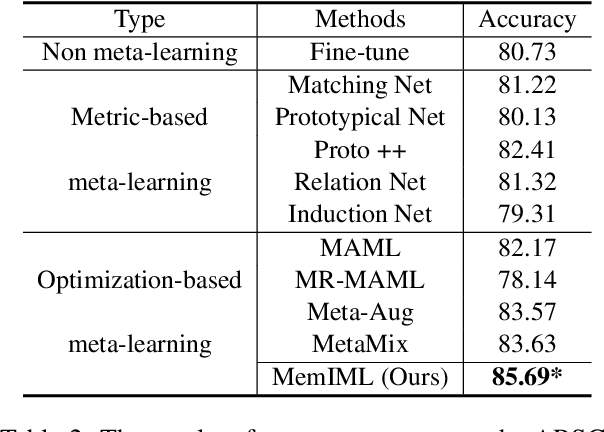
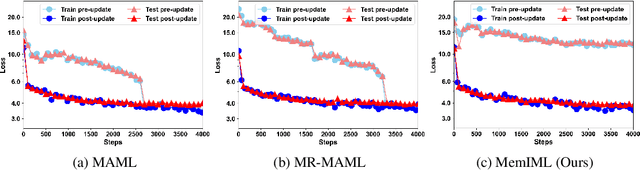
Building models of natural language processing (NLP) is challenging in low-resource scenarios where only limited data are available. Optimization-based meta-learning algorithms achieve promising results in low-resource scenarios by adapting a well-generalized model initialization to handle new tasks. Nonetheless, these approaches suffer from the memorization overfitting issue, where the model tends to memorize the meta-training tasks while ignoring support sets when adapting to new tasks. To address this issue, we propose a memory imitation meta-learning (MemIML) method that enhances the model's reliance on support sets for task adaptation. Specifically, we introduce a task-specific memory module to store support set information and construct an imitation module to force query sets to imitate the behaviors of some representative support-set samples stored in the memory. A theoretical analysis is provided to prove the effectiveness of our method, and empirical results also demonstrate that our method outperforms competitive baselines on both text classification and generation tasks.
GALAXY: A Generative Pre-trained Model for Task-Oriented Dialog with Semi-Supervised Learning and Explicit Policy Injection
Dec 27, 2021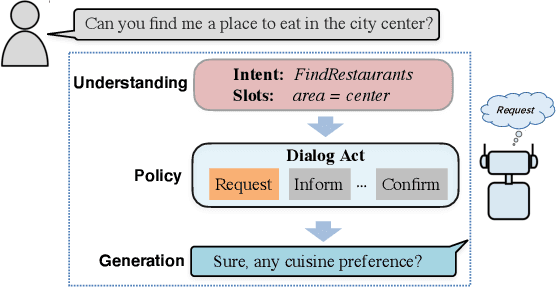
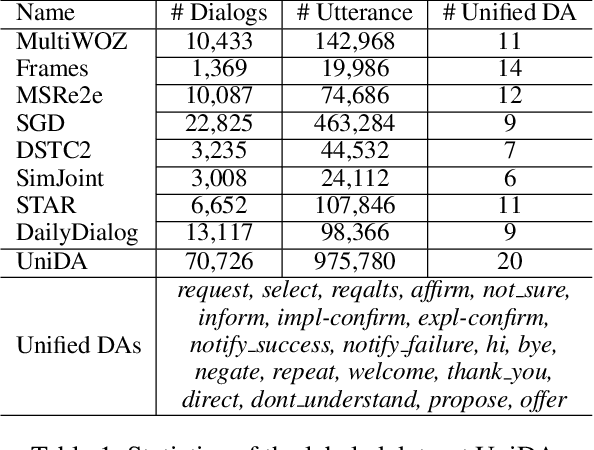

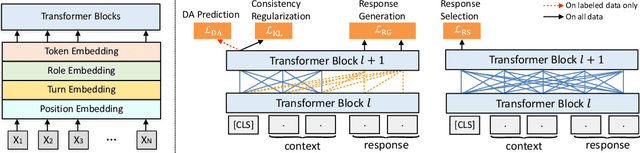
Pre-trained models have proved to be powerful in enhancing task-oriented dialog systems. However, current pre-training methods mainly focus on enhancing dialog understanding and generation tasks while neglecting the exploitation of dialog policy. In this paper, we propose GALAXY, a novel pre-trained dialog model that explicitly learns dialog policy from limited labeled dialogs and large-scale unlabeled dialog corpora via semi-supervised learning. Specifically, we introduce a dialog act prediction task for policy optimization during pre-training and employ a consistency regularization term to refine the learned representation with the help of unlabeled dialogs. We also implement a gating mechanism to weigh suitable unlabeled dialog samples. Empirical results show that GALAXY substantially improves the performance of task-oriented dialog systems, and achieves new state-of-the-art results on benchmark datasets: In-Car, MultiWOZ2.0 and MultiWOZ2.1, improving their end-to-end combined scores by 2.5, 5.3 and 5.5 points, respectively. We also show that GALAXY has a stronger few-shot ability than existing models under various low-resource settings.
Unsupervised Domain Adaptation with Adapter
Nov 01, 2021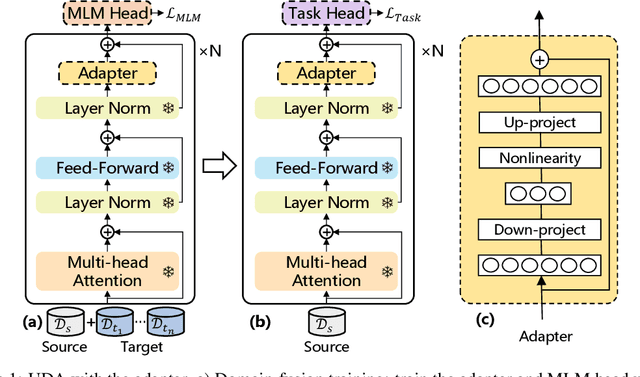
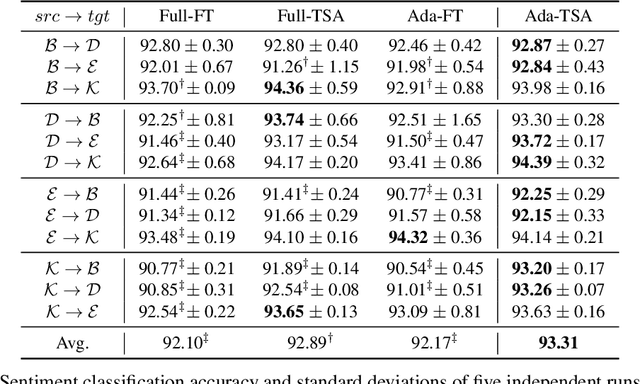
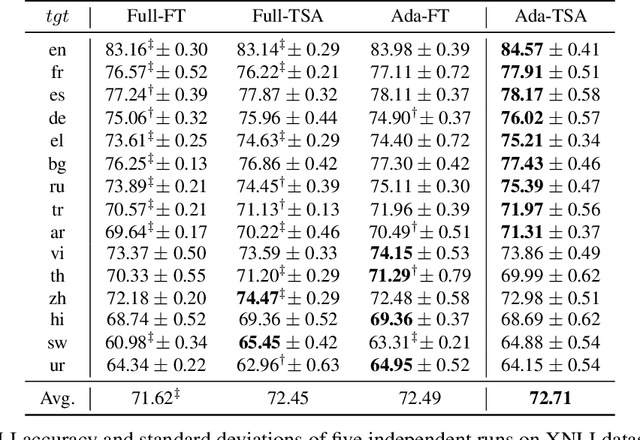
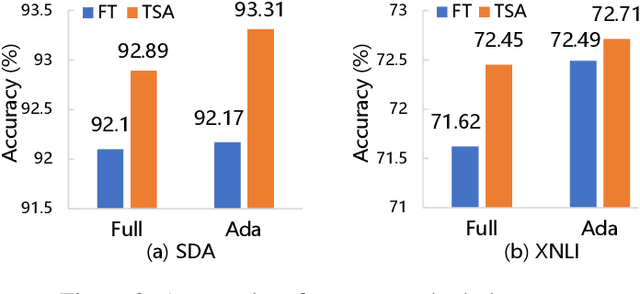
Unsupervised domain adaptation (UDA) with pre-trained language models (PrLM) has achieved promising results since these pre-trained models embed generic knowledge learned from various domains. However, fine-tuning all the parameters of the PrLM on a small domain-specific corpus distort the learned generic knowledge, and it is also expensive to deployment a whole fine-tuned PrLM for each domain. This paper explores an adapter-based fine-tuning approach for unsupervised domain adaptation. Specifically, several trainable adapter modules are inserted in a PrLM, and the embedded generic knowledge is preserved by fixing the parameters of the original PrLM at fine-tuning. A domain-fusion scheme is introduced to train these adapters using a mix-domain corpus to better capture transferable features. Elaborated experiments on two benchmark datasets are carried out, and the results demonstrate that our approach is effective with different tasks, dataset sizes, and domain similarities.
Transferable Persona-Grounded Dialogues via Grounded Minimal Edits
Sep 16, 2021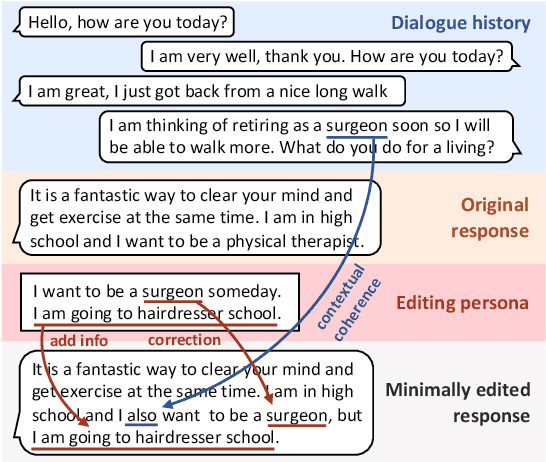

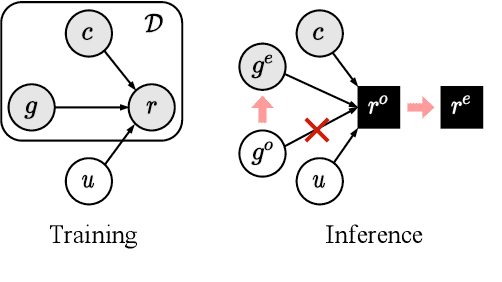
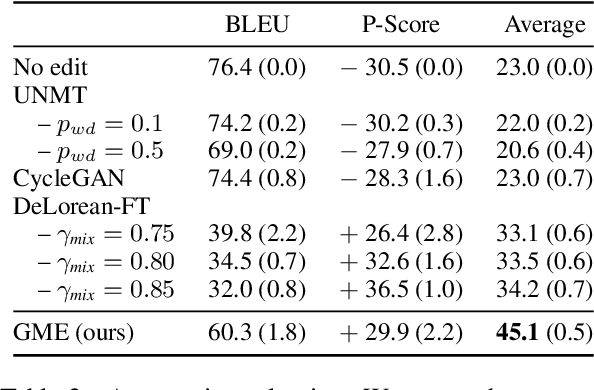
Grounded dialogue models generate responses that are grounded on certain concepts. Limited by the distribution of grounded dialogue data, models trained on such data face the transferability challenges in terms of the data distribution and the type of grounded concepts. To address the challenges, we propose the grounded minimal editing framework, which minimally edits existing responses to be grounded on the given concept. Focusing on personas, we propose Grounded Minimal Editor (GME), which learns to edit by disentangling and recombining persona-related and persona-agnostic parts of the response. To evaluate persona-grounded minimal editing, we present the PersonaMinEdit dataset, and experimental results show that GME outperforms competitive baselines by a large margin. To evaluate the transferability, we experiment on the test set of BlendedSkillTalk and show that GME can edit dialogue models' responses to largely improve their persona consistency while preserving the use of knowledge and empathy.
MMChat: Multi-Modal Chat Dataset on Social Media
Aug 16, 2021

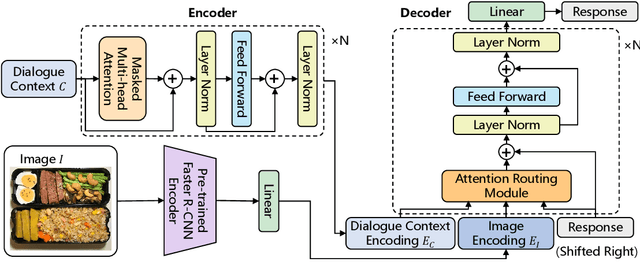
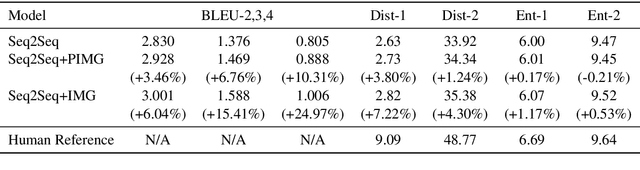
Incorporating multi-modal contexts in conversation is an important step for developing more engaging dialogue systems. In this work, we explore this direction by introducing MMChat: a large scale multi-modal dialogue corpus (32.4M raw dialogues and 120.84K filtered dialogues). Unlike previous corpora that are crowd-sourced or collected from fictitious movies, MMChat contains image-grounded dialogues collected from real conversations on social media, in which the sparsity issue is observed. Specifically, image-initiated dialogues in common communications may deviate to some non-image-grounded topics as the conversation proceeds. We develop a benchmark model to address this issue in dialogue generation tasks by adapting the attention routing mechanism on image features. Experiments demonstrate the usefulness of incorporating image features and the effectiveness in handling the sparsity of image features.