 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPRM: A Dual Implicit Process Reward Model in Multi-Hop Question Answering
Nov 11, 2025In multi-hop question answering (MHQA) tasks, Chain of Thought (CoT) improves the quality of generation by guiding large language models (LLMs) through multi-step reasoning, and Knowledge Graphs (KGs) reduce hallucinations via semantic matching. Outcome Reward Models (ORMs) provide feedback after generating the final answers but fail to evaluate the process for multi-step reasoning. Traditional Process Reward Models (PRMs) evaluate the reasoning process but require costly human annotations or rollout generation. While implicit PRM is trained only with outcome signals and derives step rewards through reward parameterization without explicit annotations, it is more suitable for multi-step reasoning in MHQA tasks. However, existing implicit PRM has only been explored for plain text scenarios. When adapting to MHQA tasks, it cannot handle the graph structure constraints in KGs and capture the potential inconsistency between CoT and KG paths. To address these limitations, we propose the DPRM (Dual Implicit Process Reward Model). It trains two implicit PRMs for CoT and KG reasoning in MHQA tasks. Both PRMs, namely KG-PRM and CoT-PRM, derive step-level rewards from outcome signals via reward parameterization without additional explicit annotations. Among them, KG-PRM uses preference pairs to learn structural constraints from KGs. DPRM further introduces a consistency constraint between CoT and KG reasoning steps, making the two PRMs mutually verify and collaboratively optimize the reasoning paths. We also provide a theoretical demonstration of the derivation of process rewards. Experimental results show that our method outperforms 13 baselines on multiple datasets with up to 16.6% improvement on Hit@1.
A Multi-Scale Graph Neural Process with Cross-Drug Co-Attention for Drug-Drug Interactions Prediction
Sep 18, 2025



Accurate prediction of drug-drug interactions (DDI) is crucial for medication safety and effective drug development. However, existing methods often struggle to capture structural information across different scales, from local functional groups to global molecular topology, and typically lack mechanisms to quantify prediction confidence. To address these limitations, we propose MPNP-DDI, a novel Multi-scale Graph Neural Process framework. The core of MPNP-DDI is a unique message-passing scheme that, by being iteratively applied, learns a hierarchy of graph representations at multiple scales. Crucially, a cross-drug co-attention mechanism then dynamically fuses these multi-scale representations to generate context-aware embeddings for interacting drug pairs, while an integrated neural process module provides principled uncertainty estimation. Extensive experiments demonstrate that MPNP-DDI significantly outperforms state-of-the-art baselines on benchmark datasets. By providing accurate, generalizable, and uncertainty-aware predictions built upon multi-scale structural features, MPNP-DDI represents a powerful computational tool for pharmacovigilance, polypharmacy risk assessment, and precision medicine.
MetaMolGen: A Neural Graph Motif Generation Model for De Novo Molecular Design
Apr 22, 2025Molecular generation plays an important role in drug discovery and materials science, especially in data-scarce scenarios where traditional generative models often struggle to achieve satisfactory conditional generalization. To address this challenge, we propose MetaMolGen, a first-order meta-learning-based molecular generator designed for few-shot and property-conditioned molecular generation. MetaMolGen standardizes the distribution of graph motifs by mapping them to a normalized latent space, and employs a lightweight autoregressive sequence model to generate SMILES sequences that faithfully reflect the underlying molecular structure. In addition, it supports conditional generation of molecules with target properties through a learnable property projector integrated into the generative process.Experimental results demonstrate that MetaMolGen consistently generates valid and diverse SMILES sequences under low-data regimes, outperforming conventional baselines. This highlights its advantage in fast adaptation and efficient conditional generation for practical molecular design.
Learn to Disguise: Avoid Refusal Responses in LLM's Defense via a Multi-agent Attacker-Disguiser Game
Apr 03, 2024



With the enhanced performance of large models on natural language processing tasks, potential moral and ethical issues of large models arise. There exist malicious attackers who induce large models to jailbreak and generate information containing illegal, privacy-invasive information through techniques such as prompt engineering. As a result, large models counter malicious attackers' attacks using techniques such as safety alignment. However, the strong defense mechanism of the large model through rejection replies is easily identified by attackers and used to strengthen attackers' capabilities. In this paper, we propose a multi-agent attacker-disguiser game approach to achieve a weak defense mechanism that allows the large model to both safely reply to the attacker and hide the defense intent. First, we construct a multi-agent framework to simulate attack and defense scenarios, playing different roles to be responsible for attack, disguise, safety evaluation, and disguise evaluation tasks. After that, we design attack and disguise game algorithms to optimize the game strategies of the attacker and the disguiser and use the curriculum learning process to strengthen the capabilities of the agents. The experiments verify that the method in this paper is more effective in strengthening the model's ability to disguise the defense intent compared with other methods. Moreover, our approach can adapt any black-box large model to assist the model in defense and does not suffer from model version iterations.
LLM-based Privacy Data Augmentation Guided by Knowledge Distillation with a Distribution Tutor for Medical Text Classification
Feb 26, 2024



As sufficient data are not always publically accessible for model training, researchers exploit limited data with advanced learning algorithms or expand the dataset via data augmentation (DA). Conducting DA in private domain requires private protection approaches (i.e. anonymization and perturbation), but those methods cannot provide protection guarantees. Differential privacy (DP) learning methods theoretically bound the protection but are not skilled at generating pseudo text samples with large models. In this paper, we transfer DP-based pseudo sample generation task to DP-based generated samples discrimination task, where we propose a DP-based DA method with a LLM and a DP-based discriminator for text classification on private domains. We construct a knowledge distillation model as the DP-based discriminator: teacher models, accessing private data, teaches students how to select private samples with calibrated noise to achieve DP. To constrain the distribution of DA's generation, we propose a DP-based tutor that models the noised private distribution and controls samples' generation with a low privacy cost. We theoretically analyze our model's privacy protection and empirically verify our model.
Improving Meta-learning for Low-resource Text Classification and Generation via Memory Imitation
Mar 22, 2022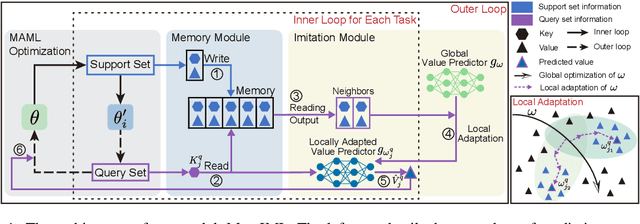
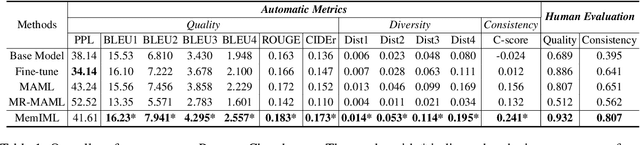
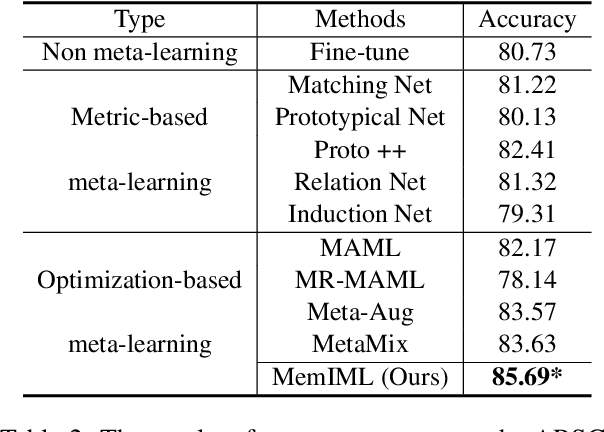
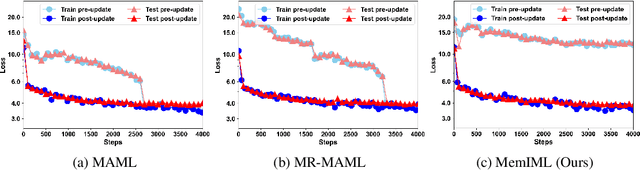
Building models of natural language processing (NLP) is challenging in low-resource scenarios where only limited data are available. Optimization-based meta-learning algorithms achieve promising results in low-resource scenarios by adapting a well-generalized model initialization to handle new tasks. Nonetheless, these approaches suffer from the memorization overfitting issue, where the model tends to memorize the meta-training tasks while ignoring support sets when adapting to new tasks. To address this issue, we propose a memory imitation meta-learning (MemIML) method that enhances the model's reliance on support sets for task adaptation. Specifically, we introduce a task-specific memory module to store support set information and construct an imitation module to force query sets to imitate the behaviors of some representative support-set samples stored in the memory. A theoretical analysis is provided to prove the effectiveness of our method, and empirical results also demonstrate that our method outperforms competitive baselines on both text classification and generation tasks.
Trivial bundle embeddings for learning graph representations
Dec 05, 2021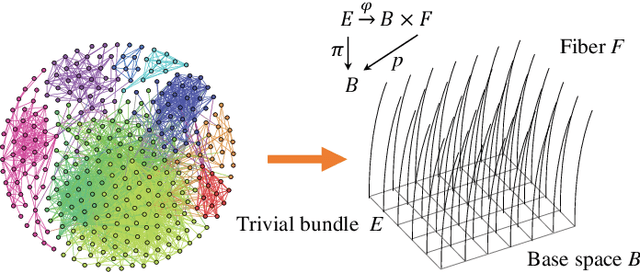
Embedding real-world networks presents challenges because it is not clear how to identify their latent geometries. Embedding some disassortative networks, such as scale-free networks, to the Euclidean space has been shown to incur distortions. Embedding scale-free networks to hyperbolic spaces offer an exciting alternative but incurs distortions when embedding assortative networks with latent geometries not hyperbolic. We propose an inductive model that leverages both the expressiveness of GCNs and trivial bundle to learn inductive node representations for networks with or without node features. A trivial bundle is a simple case of fiber bundles,a space that is globally a product space of its base space and fiber. The coordinates of base space and those of fiber can be used to express the assortative and disassortative factors in generating edges. Therefore, the model has the ability to learn embeddings that can express those factors. In practice, it reduces errors for link prediction and node classification when compared to the Euclidean and hyperbolic GCNs.
Learning from My Friends: Few-Shot Personalized Conversation Systems via Social Networks
May 21, 2021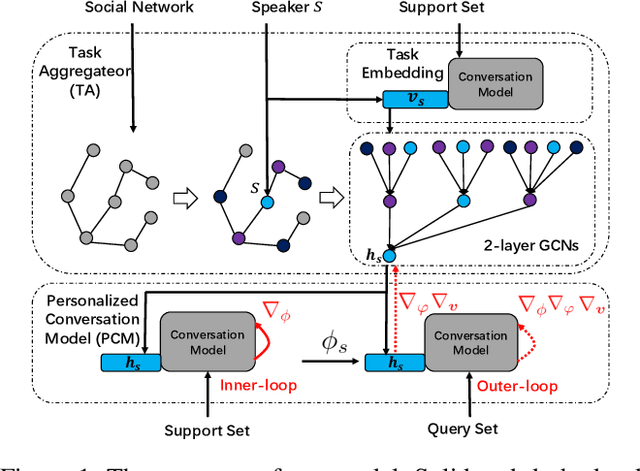
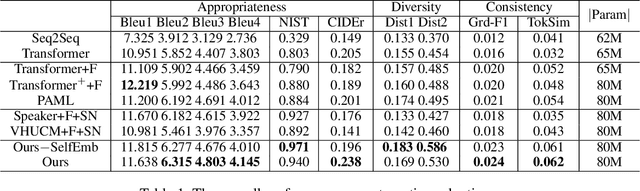


Personalized conversation models (PCMs) generate responses according to speaker preferences. Existing personalized conversation tasks typically require models to extract speaker preferences from user descriptions or their conversation histories, which are scarce for newcomers and inactive users. In this paper, we propose a few-shot personalized conversation task with an auxiliary social network. The task requires models to generate personalized responses for a speaker given a few conversations from the speaker and a social network. Existing methods are mainly designed to incorporate descriptions or conversation histories. Those methods can hardly model speakers with so few conversations or connections between speakers. To better cater for newcomers with few resources, we propose a personalized conversation model (PCM) that learns to adapt to new speakers as well as enabling new speakers to learn from resource-rich speakers. Particularly, based on a meta-learning based PCM, we propose a task aggregator (TA) to collect other speakers' information from the social network. The TA provides prior knowledge of the new speaker in its meta-learning. Experimental results show our methods outperform all baselines in appropriateness, diversity, and consistency with speakers.
When does MAML Work the Best? An Empirical Study on Model-Agnostic Meta-Learning in NLP Applications
May 24, 2020
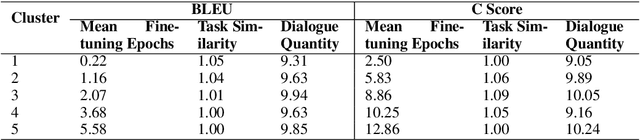
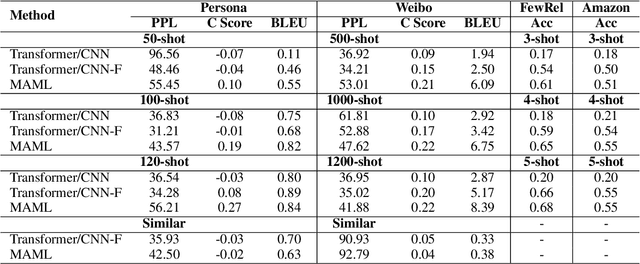
Model-Agnostic Meta-Learning (MAML), a model-agnostic meta-learning method, is successfully employed in NLP applications including few-shot text classification and multi-domain low-resource language generation. Many impacting factors, including data quantity, similarity among tasks, and the balance between general language model and task-specific adaptation, can affect the performance of MAML in NLP, but few works have thoroughly studied them. In this paper, we conduct an empirical study to investigate these impacting factors and conclude when MAML works the best based on the experimental results.
Response-Anticipated Memory for On-Demand Knowledge Integration in Response Generation
May 13, 2020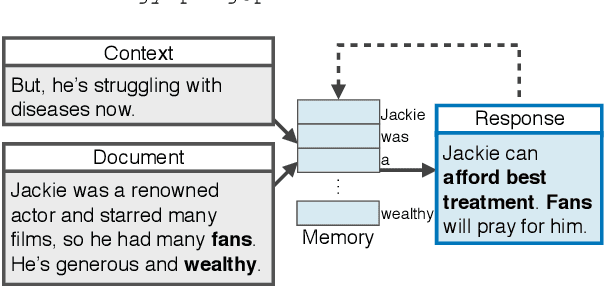
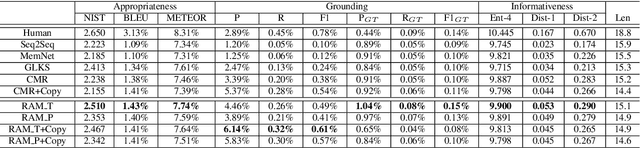
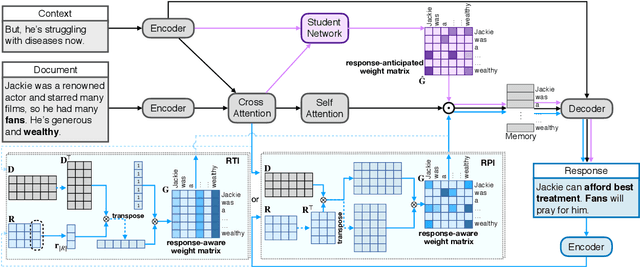

Neural conversation models are known to generate appropriate but non-informative responses in general. A scenario where informativeness can be significantly enhanced is Conversing by Reading (CbR), where conversations take place with respect to a given external document. In previous work, the external document is utilized by (1) creating a context-aware document memory that integrates information from the document and the conversational context, and then (2) generating responses referring to the memory. In this paper, we propose to create the document memory with some anticipated responses in mind. This is achieved using a teacher-student framework. The teacher is given the external document, the context, and the ground-truth response, and learns how to build a response-aware document memory from three sources of information. The student learns to construct a response-anticipated document memory from the first two sources, and the teacher's insight on memory creation. Empirical results show that our model outperforms the previous state-of-the-art for the CbR task.