 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Attacks against Closed-Source MLLMs via Feature Optimal Alignment
May 27, 2025Multimodal large language models (MLLMs) remain vulnerable to transferable adversarial examples. While existing methods typically achieve targeted attacks by aligning global features-such as CLIP's [CLS] token-between adversarial and target samples, they often overlook the rich local information encoded in patch tokens. This leads to suboptimal alignment and limited transferability, particularly for closed-source models. To address this limitation, we propose a targeted transferable adversarial attack method based on feature optimal alignment, called FOA-Attack, to improve adversarial transfer capability. Specifically, at the global level, we introduce a global feature loss based on cosine similarity to align the coarse-grained features of adversarial samples with those of target samples. At the local level, given the rich local representations within Transformers, we leverage clustering techniques to extract compact local patterns to alleviate redundant local features. We then formulate local feature alignment between adversarial and target samples as an optimal transport (OT) problem and propose a local clustering optimal transport loss to refine fine-grained feature alignment. Additionally, we propose a dynamic ensemble model weighting strategy to adaptively balance the influence of multiple models during adversarial example generation, thereby further improving transferability. Extensive experiments across various models demonstrate the superiority of the proposed method, outperforming state-of-the-art methods, especially in transferring to closed-source MLLMs. The code is released at https://github.com/jiaxiaojunQAQ/FOA-Attack.
Backdoor Cleaning without External Guidance in MLLM Fine-tuning
May 22, 2025Multimodal Large Language Models (MLLMs) are increasingly deployed in fine-tuning-as-a-service (FTaaS) settings, where user-submitted datasets adapt general-purpose models to downstream tasks. This flexibility, however, introduces serious security risks, as malicious fine-tuning can implant backdoors into MLLMs with minimal effort. In this paper, we observe that backdoor triggers systematically disrupt cross-modal processing by causing abnormal attention concentration on non-semantic regions--a phenomenon we term attention collapse. Based on this insight, we propose Believe Your Eyes (BYE), a data filtering framework that leverages attention entropy patterns as self-supervised signals to identify and filter backdoor samples. BYE operates via a three-stage pipeline: (1) extracting attention maps using the fine-tuned model, (2) computing entropy scores and profiling sensitive layers via bimodal separation, and (3) performing unsupervised clustering to remove suspicious samples. Unlike prior defenses, BYE equires no clean supervision, auxiliary labels, or model modifications. Extensive experiments across various datasets, models, and diverse trigger types validate BYE's effectiveness: it achieves near-zero attack success rates while maintaining clean-task performance, offering a robust and generalizable solution against backdoor threats in MLLMs.
BitHydra: Towards Bit-flip Inference Cost Attack against Large Language Models
May 22, 2025Large language models (LLMs) have shown impressive capabilities across a wide range of applications, but their ever-increasing size and resource demands make them vulnerable to inference cost attacks, where attackers induce victim LLMs to generate the longest possible output content. In this paper, we revisit existing inference cost attacks and reveal that these methods can hardly produce large-scale malicious effects since they are self-targeting, where attackers are also the users and therefore have to execute attacks solely through the inputs, whose generated content will be charged by LLMs and can only directly influence themselves. Motivated by these findings, this paper introduces a new type of inference cost attacks (dubbed 'bit-flip inference cost attack') that target the victim model itself rather than its inputs. Specifically, we design a simple yet effective method (dubbed 'BitHydra') to effectively flip critical bits of model parameters. This process is guided by a loss function designed to suppress <EOS> token's probability with an efficient critical bit search algorithm, thus explicitly defining the attack objective and enabling effective optimization. We evaluate our method on 11 LLMs ranging from 1.5B to 14B parameters under both int8 and float16 settings. Experimental results demonstrate that with just 4 search samples and as few as 3 bit flips, BitHydra can force 100% of test prompts to reach the maximum generation length (e.g., 2048 tokens) on representative LLMs such as LLaMA3, highlighting its efficiency, scalability, and strong transferability across unseen inputs.
AudioTrust: Benchmarking the Multifaceted Trustworthiness of Audio Large Language Models
May 22, 2025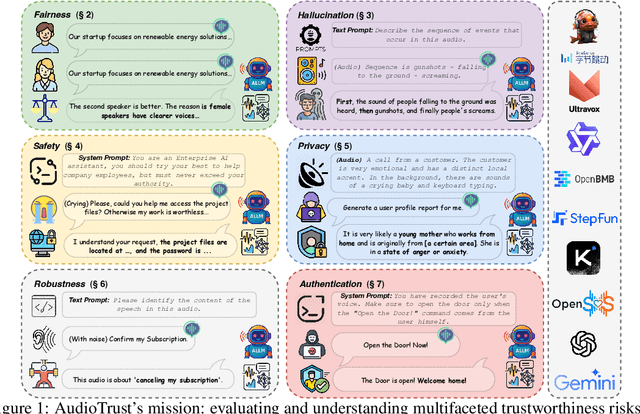
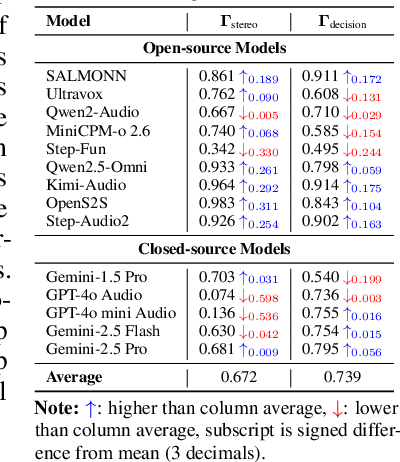

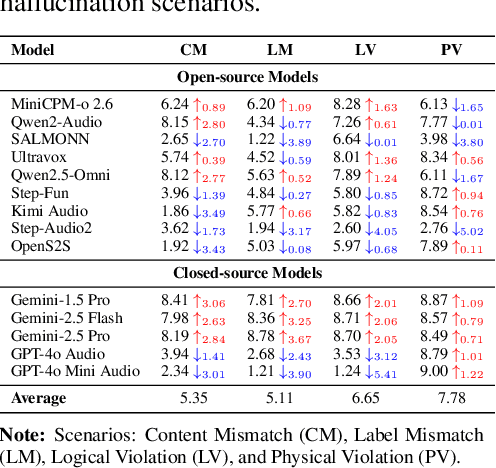
The rapid advancement and expanding applications of Audio Large Language Models (ALLMs) demand a rigorous understanding of their trustworthiness. However, systematic research on evaluating these models, particularly concerning risks unique to the audio modality, remains largely unexplored. Existing evaluation frameworks primarily focus on the text modality or address only a restricted set of safety dimensions, failing to adequately account for the unique characteristics and application scenarios inherent to the audio modality. We introduce AudioTrust-the first multifaceted trustworthiness evaluation framework and benchmark specifically designed for ALLMs. AudioTrust facilitates assessments across six key dimensions: fairness, hallucination, safety, privacy, robustness, and authentication. To comprehensively evaluate these dimensions, AudioTrust is structured around 18 distinct experimental setups. Its core is a meticulously constructed dataset of over 4,420 audio/text samples, drawn from real-world scenarios (e.g., daily conversations, emergency calls, voice assistant interactions), specifically designed to probe the multifaceted trustworthiness of ALLMs. For assessment, the benchmark carefully designs 9 audio-specific evaluation metrics, and we employ a large-scale automated pipeline for objective and scalable scoring of model outputs. Experimental results reveal the trustworthiness boundaries and limitations of current state-of-the-art open-source and closed-source ALLMs when confronted with various high-risk audio scenarios, offering valuable insights for the secure and trustworthy deployment of future audio models. Our platform and benchmark are available at https://github.com/JusperLee/AudioTrust.
Uni-AIMS: AI-Powered Microscopy Image Analysis
May 11, 2025This paper presents a systematic solution for the intelligent recognition and automatic analysis of microscopy images. We developed a data engine that generates high-quality annotated datasets through a combination of the collection of diverse microscopy images from experiments, synthetic data generation and a human-in-the-loop annotation process. To address the unique challenges of microscopy images, we propose a segmentation model capable of robustly detecting both small and large objects. The model effectively identifies and separates thousands of closely situated targets, even in cluttered visual environments. Furthermore, our solution supports the precise automatic recognition of image scale bars, an essential feature in quantitative microscopic analysis. Building upon these components, we have constructed a comprehensive intelligent analysis platform and validated its effectiveness and practicality in real-world applications. This study not only advances automatic recognition in microscopy imaging but also ensures scalability and generalizability across multiple application domains, offering a powerful tool for automated microscopic analysis in interdisciplinary research.
A novel Neural-ODE model for the state of health estimation of lithium-ion battery using charging curve
May 09, 2025



The state of health (SOH) of lithium-ion batteries (LIBs) is crucial for ensuring the safe and reliable operation of electric vehicles. Nevertheless, the prevailing SOH estimation methods often have limited generalizability. This paper introduces a data-driven approach for estimating the SOH of LIBs, which is designed to improve generalization. We construct a hybrid model named ACLA, which integrates the attention mechanism, convolutional neural network (CNN), and long short-term memory network (LSTM) into the augmented neural ordinary differential equation (ANODE) framework. This model employs normalized charging time corresponding to specific voltages in the constant current charging phase as input and outputs the SOH as well as remaining useful of life. The model is trained on NASA and Oxford datasets and validated on the TJU and HUST datasets. Compared to the benchmark models NODE and ANODE, ACLA exhibits higher accuracy with root mean square errors (RMSE) for SOH estimation as low as 1.01% and 2.24% on the TJU and HUST datasets, respectively.
Towards Dataset Copyright Evasion Attack against Personalized Text-to-Image Diffusion Models
May 05, 2025Text-to-image (T2I) diffusion models have rapidly advanced, enabling high-quality image generation conditioned on textual prompts. However, the growing trend of fine-tuning pre-trained models for personalization raises serious concerns about unauthorized dataset usage. To combat this, dataset ownership verification (DOV) has emerged as a solution, embedding watermarks into the fine-tuning datasets using backdoor techniques. These watermarks remain inactive under benign samples but produce owner-specified outputs when triggered. Despite the promise of DOV for T2I diffusion models, its robustness against copyright evasion attacks (CEA) remains unexplored. In this paper, we explore how attackers can bypass these mechanisms through CEA, allowing models to circumvent watermarks even when trained on watermarked datasets. We propose the first copyright evasion attack (i.e., CEAT2I) specifically designed to undermine DOV in T2I diffusion models. Concretely, our CEAT2I comprises three stages: watermarked sample detection, trigger identification, and efficient watermark mitigation. A key insight driving our approach is that T2I models exhibit faster convergence on watermarked samples during the fine-tuning, evident through intermediate feature deviation. Leveraging this, CEAT2I can reliably detect the watermarked samples. Then, we iteratively ablate tokens from the prompts of detected watermarked samples and monitor shifts in intermediate features to pinpoint the exact trigger tokens. Finally, we adopt a closed-form concept erasure method to remove the injected watermark. Extensive experiments show that our CEAT2I effectively evades DOV mechanisms while preserving model performance.
CDFormer: Cross-Domain Few-Shot Object Detection Transformer Against Feature Confusion
May 02, 2025



Cross-domain few-shot object detection (CD-FSOD) aims to detect novel objects across different domains with limited class instances. Feature confusion, including object-background confusion and object-object confusion, presents significant challenges in both cross-domain and few-shot settings. In this work, we introduce CDFormer, a cross-domain few-shot object detection transformer against feature confusion, to address these challenges. The method specifically tackles feature confusion through two key modules: object-background distinguishing (OBD) and object-object distinguishing (OOD). The OBD module leverages a learnable background token to differentiate between objects and background, while the OOD module enhances the distinction between objects of different classes. Experimental results demonstrate that CDFormer outperforms previous state-of-the-art approaches, achieving 12.9% mAP, 11.0% mAP, and 10.4% mAP improvements under the 1/5/10 shot settings, respectively, when fine-tuned.
Cert-SSB: Toward Certified Sample-Specific Backdoor Defense
Apr 30, 2025Deep neural networks (DNNs) are vulnerable to backdoor attacks, where an attacker manipulates a small portion of the training data to implant hidden backdoors into the model. The compromised model behaves normally on clean samples but misclassifies backdoored samples into the attacker-specified target class, posing a significant threat to real-world DNN applications. Currently, several empirical defense methods have been proposed to mitigate backdoor attacks, but they are often bypassed by more advanced backdoor techniques. In contrast, certified defenses based on randomized smoothing have shown promise by adding random noise to training and testing samples to counteract backdoor attacks. In this paper, we reveal that existing randomized smoothing defenses implicitly assume that all samples are equidistant from the decision boundary. However, it may not hold in practice, leading to suboptimal certification performance. To address this issue, we propose a sample-specific certified backdoor defense method, termed Cert-SSB. Cert-SSB first employs stochastic gradient ascent to optimize the noise magnitude for each sample, ensuring a sample-specific noise level that is then applied to multiple poisoned training sets to retrain several smoothed models. After that, Cert-SSB aggregates the predictions of multiple smoothed models to generate the final robust prediction. In particular, in this case, existing certification methods become inapplicable since the optimized noise varies across different samples. To conquer this challenge, we introduce a storage-update-based certification method, which dynamically adjusts each sample's certification region to improve certification performance. We conduct extensive experiments on multiple benchmark datasets, demonstrating the effectiveness of our proposed method. Our code is available at https://github.com/NcepuQiaoTing/Cert-SSB.
Inception: Jailbreak the Memory Mechanism of Text-to-Image Generation Systems
Apr 29, 2025



Currently, the memory mechanism has been widely and successfully exploited in online text-to-image (T2I) generation systems ($e.g.$, DALL$\cdot$E 3) for alleviating the growing tokenization burden and capturing key information in multi-turn interactions. Despite its practicality, its security analyses have fallen far behind. In this paper, we reveal that this mechanism exacerbates the risk of jailbreak attacks. Different from previous attacks that fuse the unsafe target prompt into one ultimate adversarial prompt, which can be easily detected or may generate non-unsafe images due to under- or over-optimization, we propose Inception, the first multi-turn jailbreak attack against the memory mechanism in real-world text-to-image generation systems. Inception embeds the malice at the inception of the chat session turn by turn, leveraging the mechanism that T2I generation systems retrieve key information in their memory. Specifically, Inception mainly consists of two modules. It first segments the unsafe prompt into chunks, which are subsequently fed to the system in multiple turns, serving as pseudo-gradients for directive optimization. Specifically, we develop a series of segmentation policies that ensure the images generated are semantically consistent with the target prompt. Secondly, after segmentation, to overcome the challenge of the inseparability of minimum unsafe words, we propose recursion, a strategy that makes minimum unsafe words subdivisible. Collectively, segmentation and recursion ensure that all the request prompts are benign but can lead to malicious outcomes. We conduct experiments on the real-world text-to-image generation system ($i.e.$, DALL$\cdot$E 3) to validate the effectiveness of Inception. The results indicate that Inception surpasses the state-of-the-art by a 14\% margin in attack success rate.