 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensity-Guided Robust Counterfactual Explanations on Tabular Data under Model Multiplicity
May 29, 2026Counterfactual explanations (CEs) are essential for actionable recourse, yet their reliability is often compromised in low-density regions, where classifiers exhibit high variance. Unlike existing methods that rely on expensive ensemble intersections to define stability, we propose \textit{DensityFlow}, a generative framework that constructs robust CEs by adhering to the high-confidence data manifold. Specifically, we model the counterfactual generation as continuous-time dynamics parameterized by Neural ODE, guided by a differentiable density score to actively avoid uncertain, low-density areas. This density score is learned via Noise Contrastive Estimation, effectively leveraging a $(K{+}1)$-way discriminator to estimate density ratios. For black-box settings, we introduce a local proxy distillation mechanism that aligns a lightweight surrogate with the target model strictly within the trajectory of CE generation, enabling efficient gradient-based optimization with minimal queries. Experiments demonstrate that \textit{DensityFlow} achieves superior validity under model multiplicity while significantly reducing query costs compared to ensemble-based baselines. Our implementation is available at https://github.com/G-AILab/DensityFlow.
TELA: Text to Layer-wise 3D Clothed Human Generation
Apr 25, 2024



This paper addresses the task of 3D clothed human generation from textural descriptions. Previous works usually encode the human body and clothes as a holistic model and generate the whole model in a single-stage optimization, which makes them struggle for clothing editing and meanwhile lose fine-grained control over the whole generation process. To solve this, we propose a layer-wise clothed human representation combined with a progressive optimization strategy, which produces clothing-disentangled 3D human models while providing control capacity for the generation process. The basic idea is progressively generating a minimal-clothed human body and layer-wise clothes. During clothing generation, a novel stratified compositional rendering method is proposed to fuse multi-layer human models, and a new loss function is utilized to help decouple the clothing model from the human body. The proposed method achieves high-quality disentanglement, which thereby provides an effective way for 3D garment generation. Extensive experiments demonstrate that our approach achieves state-of-the-art 3D clothed human generation while also supporting cloth editing applications such as virtual try-on. Project page: http://jtdong.com/tela_layer/
LiDAR-based 4D Occupancy Completion and Forecasting
Oct 17, 2023



Scene completion and forecasting are two popular perception problems in research for mobile agents like autonomous vehicles. Existing approaches treat the two problems in isolation, resulting in a separate perception of the two aspects. In this paper, we introduce a novel LiDAR perception task of Occupancy Completion and Forecasting (OCF) in the context of autonomous driving to unify these aspects into a cohesive framework. This task requires new algorithms to address three challenges altogether: (1) sparse-to-dense reconstruction, (2) partial-to-complete hallucination, and (3) 3D-to-4D prediction. To enable supervision and evaluation, we curate a large-scale dataset termed OCFBench from public autonomous driving datasets. We analyze the performance of closely related existing baseline models and our own ones on our dataset. We envision that this research will inspire and call for further investigation in this evolving and crucial area of 4D perception. Our code for data curation and baseline implementation is available at https://github.com/ai4ce/Occ4cast.
Among Us: Adversarially Robust Collaborative Perception by Consensus
Mar 27, 2023



Multiple robots could perceive a scene (e.g., detect objects) collaboratively better than individuals, although easily suffer from adversarial attacks when using deep learning. This could be addressed by the adversarial defense, but its training requires the often-unknown attacking mechanism. Differently, we propose ROBOSAC, a novel sampling-based defense strategy generalizable to unseen attackers. Our key idea is that collaborative perception should lead to consensus rather than dissensus in results compared to individual perception. This leads to our hypothesize-and-verify framework: perception results with and without collaboration from a random subset of teammates are compared until reaching a consensus. In such a framework, more teammates in the sampled subset often entail better perception performance but require longer sampling time to reject potential attackers. Thus, we derive how many sampling trials are needed to ensure the desired size of an attacker-free subset, or equivalently, the maximum size of such a subset that we can successfully sample within a given number of trials. We validate our method on the task of collaborative 3D object detection in autonomous driving scenarios.
Reconstructing 3D Human Pose by Watching Humans in the Mirror
Apr 01, 2021
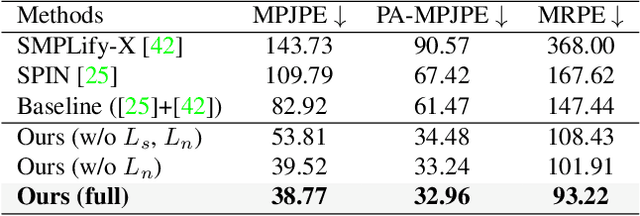
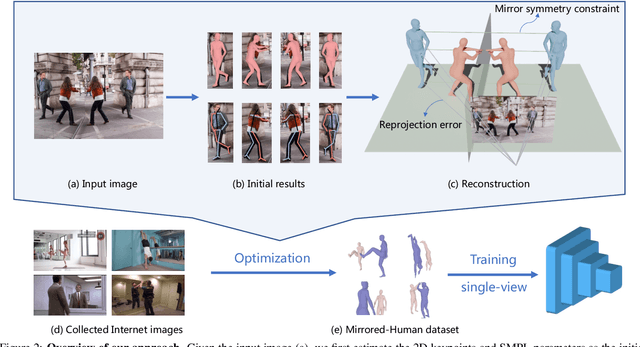
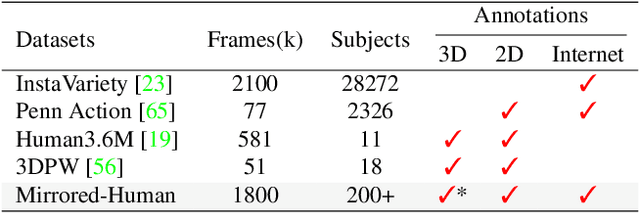
In this paper, we introduce the new task of reconstructing 3D human pose from a single image in which we can see the person and the person's image through a mirror. Compared to general scenarios of 3D pose estimation from a single view, the mirror reflection provides an additional view for resolving the depth ambiguity. We develop an optimization-based approach that exploits mirror symmetry constraints for accurate 3D pose reconstruction. We also provide a method to estimate the surface normal of the mirror from vanishing points in the single image. To validate the proposed approach, we collect a large-scale dataset named Mirrored-Human, which covers a large variety of human subjects, poses and backgrounds. The experiments demonstrate that, when trained on Mirrored-Human with our reconstructed 3D poses as pseudo ground-truth, the accuracy and generalizability of existing single-view 3D pose estimators can be largely improved.
SMAP: Single-Shot Multi-Person Absolute 3D Pose Estimation
Aug 26, 2020
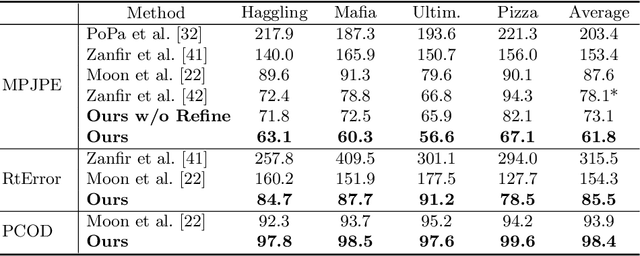
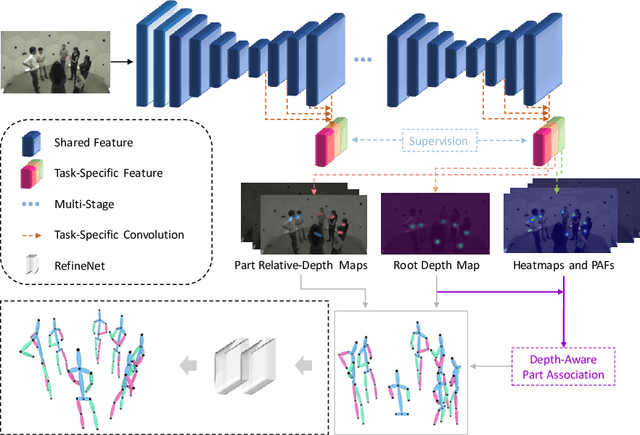
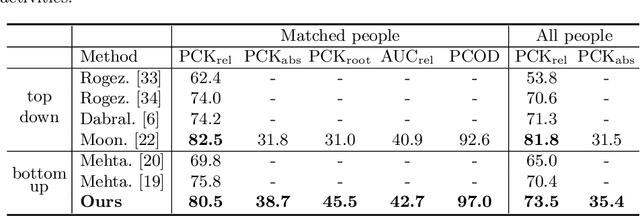
Recovering multi-person 3D poses with absolute scales from a single RGB image is a challenging problem due to the inherent depth and scale ambiguity from a single view. Addressing this ambiguity requires to aggregate various cues over the entire image, such as body sizes, scene layouts, and inter-person relationships. However, most previous methods adopt a top-down scheme that first performs 2D pose detection and then regresses the 3D pose and scale for each detected person individually, ignoring global contextual cues. In this paper, we propose a novel system that first regresses a set of 2.5D representations of body parts and then reconstructs the 3D absolute poses based on these 2.5D representations with a depth-aware part association algorithm. Such a single-shot bottom-up scheme allows the system to better learn and reason about the inter-person depth relationship, improving both 3D and 2D pose estimation. The experiments demonstrate that the proposed approach achieves the state-of-the-art performance on the CMU Panoptic and MuPoTS-3D datasets and is applicable to in-the-wild videos.